

使用NVIDIA Docker在容器运行时启用GPU
描述
NVIDIA 使用容器来开发、测试、基准测试和部署深度学习( DL )框架和 HPC 应用程序。大约两年前,我们用 NVIDIA -Docker 大规模地写了 构建和部署 GPU 容器 。从那时起, NVIDIA -Docker 被下载了近 200 万次。许多客户使用 NVIDIA -Docker 将 NVIDIA 集装箱化并运行 GPU 加速的工作负载。
NVIDIA 通过 NVIDIA GPU 云( NGC )提供 GPU 加速容器,用于 DGX 系统、公共云基础设施,甚至是带有 GPUs 的本地工作站。 NVIDIA -Docker 是这些计划的关键基础技术。
除了 Docker 之外,容器技术被用于 DL 和 HPC 工作负载的不断发展的用例集,这使得我们从根本上重新思考我们现有的 NVIDIA -Docker 架构。我们的主要目标不仅追求不同容器运行时的可扩展性,而且还追求容器编排系统的可扩展性。
这里介绍的 NVIDIA 容器运行时是我们的下一代 GPU 感知容器运行时。它与 Docker 使用的 Open Containers Initiative ( OCI )规范和其他流行的容器技术兼容。
您将了解到 NVIDIA 容器运行时组件,以及如何扩展它以支持多个容器技术。让我们检查一下新运行时的体系结构和优点,展示一些新特性,并介绍一些使用 Docker 和 LXC 部署 GPU 加速应用程序的示例。
NVIDIA 集装箱运行时间
NVIDIA 在 2016 年设计了 NVIDIA -Docker ,以实现 Docker 映像中的可移植性,利用 NVIDIA GPUs 。它允许与驱动程序无关的 CUDA 映像,并提供一个 Docker 命令行包装器,在启动时将驱动程序的用户模式组件和 GPU 设备文件装入容器中。
在 NVIDIA -Docker 的生命周期中,我们意识到架构缺乏灵活性,原因如下:
与 Docker 的紧密集成不允许将来支持其他容器技术,如 LXC 、 CRI-O 和其他运行时
我们希望利用 Docker 生态系统中的其他工具–例如 撰写 (用于管理由多个容器组成的应用程序)
在 Kubernetes 和 Swarm 等编排器中支持 GPUs 作为一级资源
改进对 GPUs 的容器运行时支持,特别是自动检测用户级 NVIDIA 驱动程序库, NVIDIA 内核模块、设备排序、兼容性检查和 GPU 功能,如图形、视频加速
因此,重新设计的 NVIDIA -Docker 将对 GPUs 的核心运行时支持转移到一个名为 libnvidia-container 的库中。该库依赖于 Linux 内核原语,并且相对于更高的容器运行时层是不可知的。这使得 GPU 支持很容易扩展到不同的容器运行时,如 Docker 、 LXC 和 CRI-O 。该库包括一个命令行实用程序,还提供了一个 API ,以便将来集成到其他运行时中。我们构建的用于集成到各种运行时的库、工具和层统称为 NVIDIA 容器运行时。
在接下来的几节中,您将了解到 Docker 和 LXC 的集成。
Docker 支持
在深入研究 NVIDIA 容器运行时与 Docker 的集成之前,让我们简单看看 Docker 平台是如何演变的。
自 2015 年以来, Docker 一直在捐赠其容器平台的关键组件,首先是开放容器倡议( OCI )规范和一个名为 runc 的轻量级容器运行时规范的实现。 2016 年末, Docker 还捐赠了一个管理容器生命周期和包装 OCI / runc 的守护程序 containerd 。 containerd 守护进程处理图像的传输、容器的执行(使用 runc )、存储和网络管理。它被设计成嵌入到更大的系统中,比如 Docker 。关于这个项目的更多信息可以在官方网站 网站 上找到。
图 1 显示了 libnvidia-container 如何集成到 Docker 中,特别是在 GPU 层。为了在 Docker 中启用 nvidia-container-runtime-hook 容器,我们使用了一个名为 nvidia-container-runtime-hook 到 runc 的定制 OCI 预启动钩子(有关钩子的更多信息可以在 OCI 运行规范 中找到)。在 runc 中添加预启动钩子需要我们用 Docker 注册一个新的与 OCI 兼容的运行时(使用– runtime 选项 )。在创建容器时,预启动钩子检查容器是否启用了 GPU (使用环境变量),并使用容器运行库向容器公开 NVIDIA GPUs 。
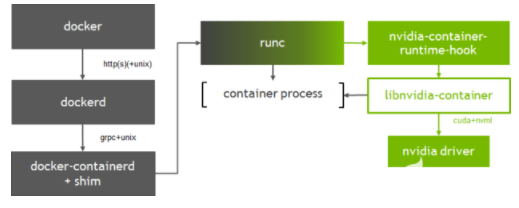
图 1 NVIDIA 容器运行时与 Docker 的集成
runc 层的集成还允许灵活地支持其他 OCI 运行时,如 CRI-O 。 containerd 的 1 。 1 版增加了对 Kubernetes 中容器运行时接口( CRI )的支持;上周 Kubernetes 宣布 通过 CRI 插件实现了 containerd 集成的普遍可用性。 NVIDIA 运行时的新架构可以很容易地支持 Kubernetes 运行时的任何一种选择。这种灵活性非常重要,因为我们与社区密切合作,使 Kubernetes 的 GPU 支持 成为一流的。
环境变量
NVIDIA 容器运行时使用容器映像中的环境变量指定 GPU 加速容器。
NVIDIA _可视设备:可在容器内访问 GPUs 的控件。默认情况下,容器可以访问所有 GPUs 。
NVIDIA _驱动程序功能:控制哪些驱动程序特性(例如计算、图形)暴露到容器中。
NVIDIA U 需要 u *:逻辑表达式,用于定义容器支持的配置上的约束(例如最小 CUDA 、驱动程序或计算能力)。
如果没有检测到环境变量(在 Docker 命令行或图像中),则使用默认的 runc 。您可以在 NVIDIA 容器运行时 文档 中找到有关这些环境变量的更多信息。这些环境变量已经在 NVIDIA 的 官方的 CUDA 容器中设置。
安装
您的系统必须满足以下先决条件,才能在 Docker 中开始使用 NVIDIA 容器运行时。
支持 您的发行版的 Docker 版本。跟随 Docker 的官方 说明书 。
最新的 NVIDIA 驱动程序。使用 程序包管理器 安装 cuda-drivers 包,或者使用驱动程序下载 网站 中的安装程序。请注意,使用 cuda-drivers 包可能无法在 Ubuntu 18.04 LTS 系统上运行。
要开始使用带有 Docker 的 NVIDIA 容器运行时,可以使用 NVIDIA -docker2 安装程序包,也可以手动使用 设置 运行时和 Docker 引擎。 nvidia-docker2 软件包包括一个自定义的 daemon.json 文件,用于将 NVIDIA 运行时注册为 Docker 的默认运行时,以及一个向后兼容 NVIDIA -Docker 1. 0 的脚本。
如果安装了 NVIDIA -docker 1.0 ,则需要在安装 NVIDIA 运行时之前删除它和任何现有的 GPU 容器。请注意,以下安装步骤适用于 Debian 发行版及其衍生产品。
$ docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f $ sudo apt-get purge -y nvidia-docker
现在,让我们添加包存储库并刷新包索引。
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - $ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update
然后使用 nvidia-docker2 包安装各个组件并重新加载 Docker 守护程序配置。
$ sudo apt-get install -y nvidia-docker2 $ sudo pkill -SIGHUP dockerd
运行以下命令行实用程序( CLI )以验证 NVIDIA 驱动程序和运行时是否已正确安装在您的系统上(作为安装程序包的一部分提供)。运行时 CLI 提供有关系统中检测到的驱动程序和设备的信息。在本例中,运行库已正确检测并枚举了系统中的 4 个 NVIDIA Tesla v100 。
$ sudo nvidia-container-cli --load-kmods info NVRM version: 396.26 CUDA version: 9.2 Device Index: 0 Device Minor: 2 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-e354d47d-0b3e-4128-74bf-f1583d34af0e Bus Location: 00000000:00:1b.0 Architecture: 7.0 Device Index: 1 Device Minor: 0 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-716346f4-da29-392a-c4ee-b9840ec2f2e9 Bus Location: 00000000:00:1c.0 Architecture: 7.0 Device Index: 2 Device Minor: 3 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-9676587f-b418-ee6b-15ac-38470e1278fb Bus Location: 00000000:00:1d.0 Architecture: 7.0 Device Index: 3 Device Minor: 2 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-2370332b-9181-d6f5-1f24-59d66fc7a87e Bus Location: 00000000:00:1e.0 Architecture: 7.0
nvidia-container-cli 检测到的 CUDA 版本验证主机上安装的 NVIDIA 驱动程序是否足以运行基于特定 CUDA 版本的容器。如果存在不兼容,运行时将不启动容器。有关 CUDA 兼容性和最低驱动程序要求的更多信息,请参见 在这里 。
现在,让我们尝试用 Docker 运行一个 GPU 容器。这个例子提取 Docker Hub 存储库 上可用的 NVIDIA CUDA 容器,并在容器内运行 nvidia-smi 命令。
$ sudo docker run --rm --runtime=nvidia -ti nvidia/cuda root@d6c41b66c3b4:/# nvidia-smi Sun May 20 22:06:13 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | Off | | N/A 41C P0 34W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | Off | | N/A 39C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | Off | | N/A 39C P0 38W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 | | N/A 42C P0 38W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
运行 GPU 集装箱
现在让我们看一些运行更复杂的 GPU 应用程序的例子。 NVIDIA 为 深度学习 和 NGC 注册 上的 HPC 提供了多种预制容器。
深度学习框架容器
这个例子使用 NGC 提供的 PyTorch 深度学习框架容器来训练一个 deep 神经网络 。您需要打开一个免费的 NGC 帐户才能访问最新的深度学习框架和 HPC 容器。 NGC 文件 概述了开始所需的步骤。
本例使用了 NVIDIA_VISIBLE_DEVICES 变量,仅向容器公开两个 GPUs 。
$ sudo docker run -it --runtime=nvidia --shm-size=1g -e NVIDIA_VISIBLE_DEVICES=0,1 --rm nvcr.io/nvidia/pytorch:18.05-py3 Copyright (c) 2006 Idiap Research Institute (Samy Bengio) Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz) All rights reserved. Various files include modifications (c) NVIDIA CORPORATION. All rights reserved. NVIDIA modifications are covered by the license terms that apply to the underlying project or file.
在容器中运行 nvidia-smi 命令,验证只有两个 GPUs 可见。
root@45cebefa1480:/workspace# nvidia-smi Mon May 28 07:15:39 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 | | N/A 39C P0 36W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 | | N/A 38C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ root@45cebefa1480:/workspace#
尝试运行容器附带的 MNIST 培训示例:
root@45cebefa1480:/workspace/examples/mnist# python main.py Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Processing... Done! main.py:68: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument. return F.log_softmax(x) main.py:90: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number 100. * batch_idx / len(train_loader), loss.data[0])) Train Epoch: 1 [0/60000 (0%)] Loss: 2.373651 Train Epoch: 1 [640/60000 (1%)] Loss: 2.310517 Train Epoch: 1 [1280/60000 (2%)] Loss: 2.281828 Train Epoch: 1 [1920/60000 (3%)] Loss: 2.315808 Train Epoch: 1 [2560/60000 (4%)] Loss: 2.235439 Train Epoch: 1 [3200/60000 (5%)] Loss: 2.234249 Train Epoch: 1 [3840/60000 (6%)] Loss: 2.226109 Train Epoch: 1 [4480/60000 (7%)] Loss: 2.228646 Train Epoch: 1 [5120/60000 (9%)] Loss: 2.132811
OpenGL 图形容器
如前几节所述, NVIDIA 容器运行时现在为运行 OpenGL 和 EGL 应用程序提供了支持。下一个例子使用 OpenGL 构建并运行 多体问题 模拟。使用 NVIDIA 吉特实验室 上提供的示例 Dockerfile 来构建容器。
复制 Dockerfile 并构建 多体问题 示例
$ docker build -t nbody .
允许 root 用户访问正在运行的 X 服务器
$ xhost +si:localuser:root
运行[VZX129 连续样本
$ sudo docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix nbody
图 2 用 Docker 运行 N-bodyCUDA / OpenGL 示例
编写 Docker
最后一个例子使用 Docker Compose 展示了使用 NVIDIA 容器运行时启动多个 GPU 容器是多么容易。这个例子将启动 3 个容器—— OpenGL 的 多体问题 示例、一个 EGL 示例( 钉 来自 Mesa )和一个运行 NVIDIA -smi 公司 命令的简单容器。
安装 Docker Compose
$ sudo curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose
从 NVIDIA Gitlab 克隆可用的样本
$ git clone https://gitlab.com/nvidia/samples.git
写一个 docker-compose.yml 来指定三个容器和环境。使用您选择的文本编辑器复制以下内容:
version: '2.3' services: nbody: build: samples/cudagl/ubuntu16.04/nbody runtime: nvidia environment: - DISPLAY volumes: - /tmp/.X11-unix:/tmp/.X11-unix peglgears: build: samples/opengl/ubuntu16.04/peglgears runtime: nvidia nvsmi: image: ubuntu:18.04 runtime: nvidia environment: - NVIDIA_VISIBLE_DEVICES=all command: nvidia-smi
允许 root 用户访问正在运行的 X 服务器(对于 多体问题 示例)
$ xhost +si:localuser:root
最后,启动容器
$ sudo docker-compose up
您的控制台输出可能如下所示
Building nbody
Step 1/6 : FROM nvidia/cudagl:9.0-base-ubuntu16.04
---> b6055709073e
Step 2/6 : ENV NVIDIA_DRIVER_CAPABILITIES ${NVIDIA_DRIVER_CAPABILITIES},display
---> Using cache
---> ebd1c003a592
Step 3/6 : RUN apt-get update && apt-get install -y --no-install-recommends cuda-samples-$CUDA_PKG_VERSION && rm -rf /var/lib/apt/lists/*
---> Using cache
---> 1987dc2c1bbc
Step 4/6 : WORKDIR /usr/local/cuda/samples/5_Simulations/nbody
---> Using cache
---> de7af4fbb03e
Step 5/6 : RUN make
---> Using cache
---> a6bcfb9a4958
Step 6/6 : CMD ./nbody
---> Using cache
---> 9c11a1e93ef2
Successfully built 9c11a1e93ef2
Successfully tagged ubuntu_nbody:latest
WARNING: Image for service nbody was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`.
Starting ubuntu_nbody_1 ... done
Starting ubuntu_nvsmi_1 ... done
Starting ubuntu_peglgears_1 ... done
Attaching to ubuntu_nvsmi_1, ubuntu_peglgears_1, ubuntu_nbody_1
ubuntu_nvsmi_1 exited with code 0
peglgears_1 | peglgears: EGL version = 1.4
peglgears_1 | peglgears: EGL_VENDOR = NVIDIA
peglgears_1 | 246404 frames in 5.0 seconds = 49280.703 FPS
ubuntu_peglgears_1 exited with code 0
支持带 LXC 的 GPU 容器
Linux 容器(或 LXC 公司 )是一个操作系统级的虚拟化工具,用于创建和管理系统或应用程序容器。 Docker 的早期版本使用 LXC 作为底层容器运行时技术。 LXC 提供了一套高级的工具来管理容器(例如模板、存储选项、直通设备、 autostart 等),并为用户提供了大量的控制。在参考文献中,我们在本文末尾的参考文献中提供了来自 Canonical 和 Cisco 的工程师关于 LXC 的 GTC 2018 演讲的链接。
LXC 支持非特权容器(使用 Linux 内核中的用户名称空间特性)。在 HPC 环境中部署容器的上下文中,这是一个巨大的优势,在这种环境中,用户可能没有运行容器的管理权限。 LXC 还支持 Docker 图像的导入,下面我们将详细介绍一个示例。
NVIDIA 继续与 LXC 社区密切合作,开发上游补丁,以添加 GPU 支持。 4 月初发布的 lxc3 。 0 。 0 包括使用 NVIDIA 运行时对 GPUs 的支持。有关更多信息和演示,请参阅 Canonical 的新闻 邮递 。
如图所示, VX134 是如何将容器集成到 VX12 中的。
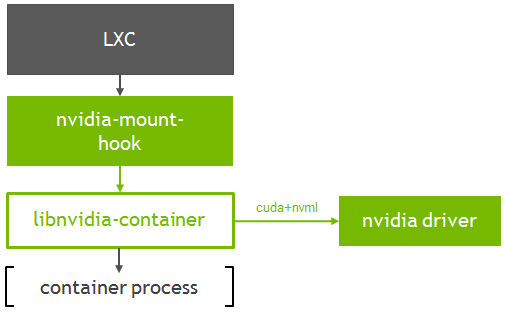
图 3 NVIDIA 容器运行时与 LXC 的集成
让我们看看用 LXC 运行一个简单的 CUDA 容器。这个例子展示了如何使用默认的 LXC OCI 模板 从 Docker Hub 上可用的 OCI 映像(使用诸如 Skopo 和 擦除 )创建应用程序容器。
首先,让我们为工具设置存储库:
$ sudo add-apt-repository ppa:ubuntu-lxc/lxc-stable $ sudo apt-add-repository ppa:projectatomic/ppa
安装 LXC 和相关工具,如 skopeo :
$ apt-get install libpam-cgfs lxc-utils lxcfs lxc-templates skopeo skopeo-containers jq libnvidia-container-tools
肥皂套装:
$ sudo curl -fsSL -o /usr/local/bin/umoci https://github.com/openSUSE/umoci/releases/download/v0.4.0/umoci.amd64 $ sudo chmod ugo+rx /usr/local/bin/umoci
为每个用户设置用户、组 ID 和虚拟以太网接口。请参阅 LXC 文档 中有关创建非特权容器的内容。为了方便起见,这里提供了示例脚本。
$ sudo curl -fsSL -o /usr/local/bin/generate-lxc-perms https://gist.githubusercontent.com/3XX0/ef77403389ffa1ca85d4625878706c7d/raw/4f0d2c02d82236f74cf668c42ee72ab06158d1d2/generate-lxc-perms.sh $ sudo chmod ugo+rx /usr/local/bin/generate-lxc-perms $ sudo curl -fsSL -o /usr/local/bin/generate-lxc-config https://gist.githubusercontent.com/3XX0/b3e2bd829d43104cd120f4258c4eeca9/raw/890dc720e1c3ad418f96ba8529eae028f01cc994/generate-lxc-config.sh $ sudo chmod ugo+rx /usr/local/bin/generate-lxc-config
现在,为每个容器设置 GPU 支持:
$ sudo tee /usr/share/lxc/config/common.conf.d/nvidia.conf <<< 'lxc.hook.mount = /usr/share/lxc/hooks/nvidia' $ sudo chmod ugo+r /usr/share/lxc/config/common.conf.d/nvidia.conf
作为一次性设置,请将权限和配置设置为常规用户:
$ sudo generate-lxc-perms $ generate-lxc-config
使用 lxc-create 从 NVIDIA 的 Docker Hub 存储库上的 CUDA 映像下载并创建一个 CUDA 应用程序容器。
$ lxc-create -t oci cuda -- -u docker://nvidia/cuda
Getting image source signatures
Copying blob sha256:297061f60c367c17cfd016c97a8cb24f5308db2c913def0f85d7a6848c0a17fa
41.03 MB / 41.03 MB [======================================================] 0s
Copying blob sha256:e9ccef17b516e916aa8abe7817876211000c27150b908bdffcdeeba938cd004c
850 B / 850 B [============================================================] 0s
Copying blob sha256:dbc33716854d9e2ef2de9769422f498f5320ffa41cb79336e7a88fbb6c3ef844
621 B / 621 B [============================================================] 0s
Copying blob sha256:8fe36b178d25214195af42254bc7d5d64a269f654ef8801bbeb0b6a70a618353
851 B / 851 B [============================================================] 0s
Copying blob sha256:686596545a94a0f0bf822e442cfd28fbd8a769f28e5f4018d7c24576dc6c3aac
169 B / 169 B [============================================================] 0s
Copying blob sha256:aa76f513fc89f79bec0efef655267642eba8deac019f4f3b48d2cc34c917d853
6.65 MB / 6.65 MB [========================================================] 0s
Copying blob sha256:c92f47f1bcde5f85cde0d7e0d9e0caba6b1c9fcc4300ff3e5f151ff267865fb9
397.29 KB / 397.29 KB [====================================================] 0s
Copying blob sha256:172daef71cc32a96c15d978fb01c34e43f33f05d8015816817cc7d4466546935
182 B / 182 B [============================================================] 0s
Copying blob sha256:e282ce84267da687f11d354cdcc39e2caf014617e30f9fb13f7711c7a93fb414
449.41 MB / 449.41 MB [====================================================] 8s
Copying blob sha256:91cebab434dc455c4a9faad8894711a79329ed61cc3c08322285ef20599b4c5e
379.37 MB / 552.87 MB [=====================================>-----------------]
Writing manifest to image destination
Storing signatures
Unpacking the rootfs • rootless{dev/agpgart} creating empty file in place of device 10:175 • rootless{dev/audio} creating empty file in place of device 14:4 • rootless{dev/audio1} creating empty file in place of device 14:20
作为普通用户,我们可以在容器内运行 nvidia-smi :
$ lxc-execute cuda root@cuda:/# nvidia-smi Mon May 28 21:48:57 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 | | N/A 40C P0 36W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 | | N/A 39C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 | | N/A 39C P0 38W / 300W | 0MiB / 16160MiB | 1% Default | +-------------------------------+----------------------+----------------------+ | 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 | | N/A 40C P0 38W / 300W | 0MiB / 16160MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
结论
本文介绍了 NVIDIA 容器运行时,以及如何将其轻松集成到容器运行时和编排生态系统中,以启用 GPU 支持。现在就开始用它来构建和运行 GPU 容器吧!安装程序包可用于 品种 的 Linux 发行版。 NVIDIA -Docker 1 。 0 已被弃用,不再被积极支持。我们强烈建议用户在使用 Docker 时升级到新的 NVIDIA 运行时。未来的路线图包括许多令人兴奋的特性,包括对 Vulkan 、 CUDA MPS 、集装箱驱动程序等的支持。
关于作者
Jonathan Calmels 是 NVIDIA 的系统软件工程师。他的工作主要集中在 GPU 数据中心软件和用于深度学习的超大规模解决方案。乔纳森拥有计算机科学与工程硕士学位。
Felix Abecassis 是 NVIDIA 的系统软件工程师,致力于使 GPU 应用程序更易于在数据中心部署和管理。 GPU 专注于机器学习支持框架。他拥有法国学校 EPITA 的计算机科学硕士学位。
Pramod Ramarao 是 NVIDIA 加速计算的产品经理。他领导 CUDA 平台和数据中心软件的产品管理,包括容器技术。
审核编辑:郭婷
-
WSL2与Docker容器之间相互迁移的教程2022-03-17 3491
-
紫金桥组态软件新的功能_运行时组态2017-10-13 1260
-
如何缩短Vivado的运行时间2019-05-29 15697
-
k8s容器运行时演进历史2021-02-02 2846
-
云芯一号测评3:Docker基础使用测试2022-01-26 629
-
如何使用NVIDIA Docker部署GPU服务器应用程序2022-04-27 3942
-
Go运行时:4年之后2022-11-30 1747
-
如何在Docker容器中运行Nginx2023-02-17 3401
-
什么是Kubernetes容器运行时CRI2023-02-20 3543
-
怎样避免电力电容器运行时漏油2023-04-07 2084
-
ch32v307记录程序运行时间2023-08-22 2022
-
Xilinx运行时(XRT)发行说明2023-09-14 809
-
各种容器运行的作用是什么2023-09-20 1867
-
如何保证它们容器运行时的安全?2023-11-03 1724
-
Kubernetes容器运行时containerd与CRI-O如何选择2026-02-26 604
全部0条评论

快来发表一下你的评论吧 !
