

数据分析将成为创新起源与企业核心能力
描述
据 Gartner 2022 年最新趋势分析,数据分析将成为创新起源与企业核心能力,数据越来越重要了。在更早前 IDC 和数据存储公司希捷的报告表示,我国产生的数据量从 2019 年的约 9.4ZB 将猛增至 2025 年的 48.6ZB。现在,数据工程师需要面对愈加繁杂和庞大的数据、离线场景/实时场景/流式场景等众多不同的分析场景、多个数据库技术栈并存和与之对应的存储计算成本,很多公司的数据团队往往会被这些海量数据与各类底层集群、基础设施的要求所淹没。
如何降本增效,打通数据分析与存储,提高数据分析的灵活性,同时降低底层资源的运维成本,成为了令技术团队头疼的问题。
智能湖仓,数据分析的下一站已到来
这个时代,驾驭数据的能力是所有决策者“技能清单”里最重要的一项。历史告诉我们,无论哪个行业,率先在行业中掌握新工具“利器”是多么重要。
最早的传统型、老式的纯数据仓库已经不适宜半 / 非结构化数据的处理;而单纯的数据湖虽然适合存储数据,但不支持事务处理,不保证数据质量,并且缺乏一致性与隔离性。
站在数据价值出口的角度来看,只有各类数据价值平台全面落地应用,大数据的潜能才会被进一步释放。为了实现数据湖和数据仓库之间的无缝流转,打通数据存储和计算的不同的层面,兼顾数据湖的灵活性和数据仓库的成长性,促进企业更有效的工具应用,像亚马逊云科技就提出了“智能湖仓”架构,帮助企业客户加快大数据价值实现进程。
以创新技术厂商亚马逊云科技为例,2020 年在亚马逊云科技 re:Invent 大会上,亚马逊云科技针对数据分析等相关服务推出了“智能湖仓”架构,不过早在 2017 年,亚马逊就发布了 Amazon Redshift Spectrum,该功能使得 Amazon Redshift 在当时就具备了打通数据湖和数据仓库的能力,实现跨数据湖、数据仓库的数据查询。此外,在 2021 年 re:Invent 大会上,亚马逊云科技更进一步,在存算分离架构基础上,推出更多数据分析服务的无服务器(Severless)版。

现在,无服务器架构(以 2014 年推出的 Amazon Lambda 为代表)已经是云原生中最热门的技术类别。无服务器应用程序是由事件驱动的,并通过与技术无关的 API 或消息收发进行松散耦合,可以让开发者更关注于构建产品中的应用,而不需要管理和维护底层堆栈。现在,数据分析服务借助无服务器的能力,可以让用户更便捷地构建数据存储、分析、智能应用解决方案,彻底实现无服务器的数据分析服务,完成底层庞杂数据的高效处理、流转与共享。
能够达到这样的技术水平和高度,离不开时间的沉淀和技术的积累。想要深刻理解“智能湖仓”,就需要了解它的过去与现在。我们能看到,亚马逊云科技所推出的无服务器数据分析服务,经历了几个阶段:
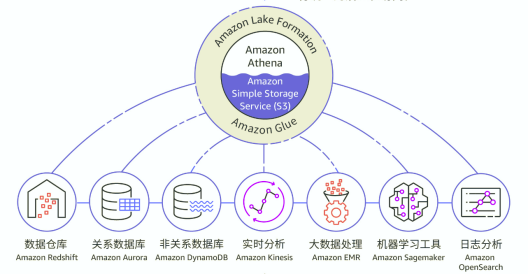
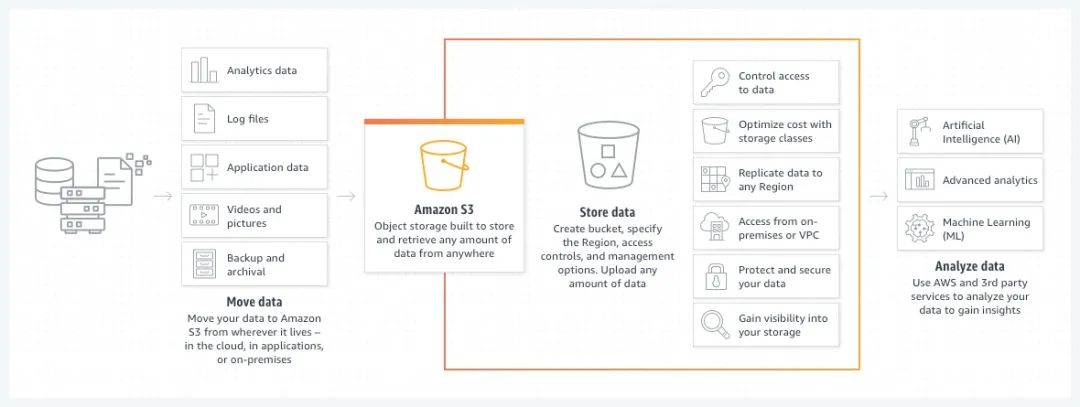
(1)2006 年,亚马逊云科技正式推出 Amazon S3,其作为亚马逊第一个云产品,提供了多种经济高效的存储类和易于使用的管理功能,从而满足特定的业务、组织和合规性要求。如今“智能湖仓”就是基于 Amazon S3 构建数据湖,绕湖集成数据仓库、大数据处理、日志分析、机器学习等数据服务。Amazon S3 数据湖的可靠性和大容量的数据存储能力,是确保整个“智能湖仓”架构有效应用的基础。对于软件开发人员来说,现在已经是无服务器架构的 Amazon S3 可以很低的成本提供可扩展、可靠且延迟低的数据存储基础设施,让开发人员利用云计算的规模优势,以极低的前期资源投入换取稳定的数据基础设施,非常适合进行快速技术创新。
(2)Amazon Athena 是一种无服务器的交互式查询服务,用户能够轻松使用标准 SQL 分析 Amazon S3 中的数据。无需 ETL ,具备 SQL 技能的任何人都可以轻松快速地分析数据湖中的大规模数据集,这对技术人员的生产力是一种解放!当我们想使用 SQL 直接进行数据湖上的分析且不想管理任何集群时,Athena 无疑是一个敏捷且快速开始的选择。
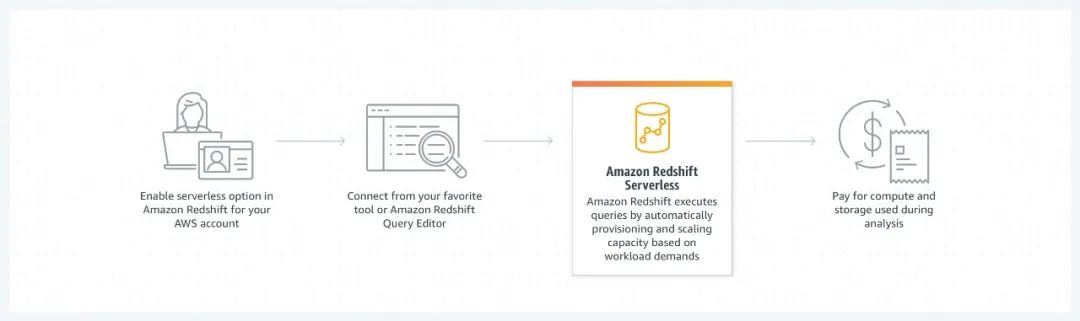
(3)Amazon Redshift 使用 SQL 在数据仓库、运营数据库和数据湖间分析结构化和半结构化数据,专注于在急速获取洞察,并交付业务结果,无需考虑管理数据仓库等基础设施。而现如今,无服务器版的 Amazon Redshift Serverless 使得数据仓库更加敏捷,用户无需亲自设置和管理数据仓库基础设施,即可在几秒钟内轻松运行和扩展分析,实现 PB 级数据规模的数据分析。目前来说,已经有很多企业去选择 Amazon Redshift 来缩短他们获得洞察的时间,因为它易于使用,可在任何规模提供可靠的性能分析所有数据,也可能是因为 Amazon Redshift 提供比其他云数据仓库高 3 倍的性价比。Amazon Redshift Serverless 是非常适合难以预测计算需求的情况,例如可变工作负载、具有空闲时间的周期性工作负载以及具有峰值的稳态工作负载。这种方法也非常适合需要快速入门的临时分析需求以及测试和开发环境。
(4)Amazon EMR 也推出了 Serverless 无服务器的版本。开发者可以使用无服务器的方式运行使用开源大数据框架(如 Apache Spark、Hive 和 Presto)构建的程序,在云中运行 PB 级数据分析,而无需配置、管理、优化或保护集群。用户无需猜测集群大小,Amazon EMR Serverless 具备自动细粒度扩缩,并且提供性能优化的运行时,速度是开源版本的两倍以上。另外,Amazon EMR 在安装 Spark、Hive、Presto 或 Trino 时可以默认安装 Hudi 组件,以实现开放格式(如 Apache Parquet 和 Apache Avro)维护 Amazon S3 或 HDFS 中的数据。举个例子,使用 Amazon EMR,技术人员可以将 Parquet 数据集转化为 Hudi 数据集,而无需重写数据集,快速将现有数据集迁移至 Apache Hudi 数据集,例如 Amazon S3 上 1TB 的 Parquet 数据集,引导执行的速度已经比批量插入快了五倍!
通过了解,CSDN 看到,上述这些仅仅只是亚马逊云科技中的一小部分数据服务及其无服务器版的发展变化。发布既是无服务器架构的云原生 NoSQL—Amazon DynamoDB,两年前即实现无服务器化的云原生关系型数据库Amazon Aurora Serverless v1(本周第二代v2也已上线),也都是值得挖掘的技术创新。
正是随着这些服务的升级与发展,“智能湖仓”也在向更敏捷,更智能的方向演变。也让技术界看到,数据分析的下一站已到来。
全栈式云原生数据分析服务,让数据真正“敏捷分析”
我们能看到,“智能湖仓”更强调架构,强调数据的自由流动和集中统一治理。“智能湖仓”架构不是简单地将湖与仓打通,而是将湖、仓与专门构建等数据服务连接成为一个整体,让数据在其间移动和访问,进一步实现数据在数据湖、数据仓库,以及在数据查询、数据分析、机器学习等各类专门构建等服务之间按需移动,从而形成统一且连续等整体,满足客户等各种需求。
亚马逊云科技的“智能湖仓”架构具有灵活扩展、专门构建、数据融合、敏捷分析、开源开放等特点。详细来说,背靠 Amazon S3 数据湖存储的高可靠和大容量,对于数据存储资源弹性伸缩扩展,在此之上,技术人员通过使用亚马逊云科技经验总结的具象产品实力,如交互式查询服务 Amazon Athena、云上大数据平台 Amazon EMR、云数据仓库 Amazon Redshift 等专门构建的数据分析服务,以及数据融合统一治理的架构之下,企业可以无需机器学习经验,使用 SQL 语句,甚至不编写代码,去进行数据分析。这种模式可以大大降低数据人员的技术门槛,让更多数据业务人员去拥抱数据,实现敏捷、快速、低成本的数据分析。
在“智能湖仓”架构下,云原生数据分析服务可以全面覆盖流数据分析、数据湖、Hadoop 等常用的分析场景,所有均无服务器化。无服务器的分析工具让客户无需配置、扩展或管理集群或服务器,也不必担心容量配置,从而可以最大程度地为客户减少无差别的繁琐工作,让数据真正实现全栈、敏捷地分析。
面对海量数据与细分环境,亚马逊云科技无服务器的“智能湖仓”架构则将易用、易扩展、高性能、专门构建、安全及智能等特性融于一体,打通数据湖和数据仓库,进一步将各种服务无缝集成,确保数据在不同服务之间顺畅流动,进而帮助客户尽可能最大程度地提高数据价值,加速创新,并成为数据驱动型组织。
从亚马逊的技术布局和发展路径,我们能看到,全栈、云原生的数据分析时代已经到来,智能化的湖仓将成为新一代数据平台架构。而借助智能湖仓,与数据相关的技术与业务人员,将可以摆脱对底层架构与数据处理技术的多个掣肘,专注于挖掘数据的创新性分析与应用,以发现并抓住任何一个创新的机遇。
审核编辑 :李倩
-
Get职场新知识:做分析,用大数据分析工具2023-12-05 3433
-
电商数据分析攻略,让你轻松搞定数据分析!2023-06-27 4257
-
什么是数据分析,数据分析能为企业带来什么?2023-04-21 1664
-
成为Python数据分析师,需要掌握哪些技能2021-06-23 6986
-
如何使用企业数据分析EDA?2021-05-05 2669
-
还在为大数据分析工具发愁?以下是2021最值得推荐的大数据分析工具2021-03-05 3134
-
BI数据分析软件使用指南2021-01-04 1927
-
现在做企业级数据分析,离不开秒分析的数据可视化工具2020-07-21 2370
-
BI分享秀——高度开放的数据分析经验共享2020-05-12 1763
-
数据分析到底对企业的作用是什么2019-02-22 9853
-
工业大数据分析平台的应用价值探讨2018-11-12 3632
-
怎么有效学习Python数据分析?2018-06-28 3011
-
数据分析需要的技能2018-04-10 3361
-
Quick BI助力云上大数据分析---深圳云栖大会2018-04-03 3193
全部0条评论

快来发表一下你的评论吧 !
