

如何在光线跟踪和碰撞检测上下文中使用NanoVDB 库的示例
描述
开放式 VDB 是奥斯卡奖获奖的稀疏动态卷的行业标准库。在整个视觉效果行业中,它被用于模拟和渲染水、火、烟、云和大量其他依赖于稀疏体积数据的效果。该库包括一个分层的、动态的数据结构和一套工具,用于高效地存储和操作三维网格上离散的稀疏体数据。库由 学院软件基金会( ASWF ) 维护。有关详细信息,请参见 VDB :具有动态拓扑的高分辨率稀疏卷 。
尽管 OpenVDB 提供了性能优势,但它的设计并没有考虑到 GPUs 。它对几个外部库的依赖使得利用 GPUs 上的 VDB 数据变得很麻烦,这正是本文主题的动机。我们将向您介绍 NanoVDB 库,并提供一些如何在光线跟踪和碰撞检测上下文中使用它的示例。
NanoVDB 简介
最初在 NVIDIA 开发的 NanoVDB 库是一个 ASWF OpenVDB 项目的新增功能 。它提供了一个与 OpenVDB 的核心数据结构完全兼容的简化表示,具有在 NanoVDB 和 OpenVDB 数据结构之间来回转换、创建和可视化数据的功能。
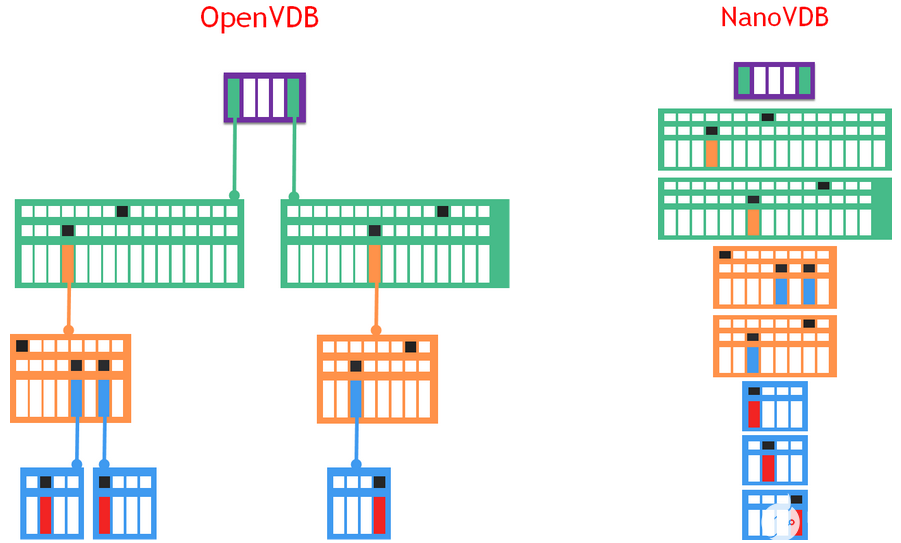
图 1 OpenVDB 和 NanoVDB 数据结构的图示。
NanoVDB 采用了 VDB 树结构的压缩、线性化、只读表示(图 1 ),这使得它适合于树层次结构的快速传输和快速、无指针遍历。为了提高效率,数据流经过调整,可以在 GPUs 和 CPU 上使用。
创建 NanoVDB 网格
尽管 NanoVDB 网格是一种只读数据结构,但该库包含生成或加载数据的功能。
所有的 OpenVDB 网格类 – LevelSets 、 FogVolumes 、 PointIndexGrids 和 PointDataGrids ——都支持 NanoVDB 表示,并且可以直接从 OpenVDB 文件(即 。 vdb 系统 文件)加载。还可以将数据加载或保存到 NanoVDB 自己的文件格式中或从中保存,该格式本质上是其内存流的一个转储,其中包含用于高效检查的附加元数据。
以下代码示例从 OpenVDB 文件转换:
以下代码示例从 OpenVDB 文件转换:
openvdb::io::File file(fileName); auto vdbGrid = file.readGrid(gridName); auto handle = nanovdb::openToNanoVDB(vdbGrid);
虽然从现有的 OpenVDB 数据加载是典型的用例,但是附带的 网格生成器 工具允许您直接在内存中构建 NanoVDB 网格。提供了一些简单原语的函数来帮助您入门:
// generate a sparse narrow-band level set (i.e. truncated signed distance field) representation of a sphere. auto handle = nanovdb::createLevelSetSphere(50, nanovdb::Vec3f(0));
下面的示例显示了如何使用 lambda 函数生成小而密集的体积(图 2 ):
nanovdb::GridBuilder builder(0);
auto op = [](const nanovdb::Coord& ijk) -> float { return menger(nanovdb::Vec3f(ijk) * 0.01f);
};
builder(op, nanovdb::CoordBBox(nanovdb::Coord(-100), nanovdb::Coord(100)));
// create a FogVolume grid called "menger" with voxel-size 1
auto handle = builder.getHandle<>(1.0, nanovdb::Vec3d(0), "menger", nanovdb::GridClass::FogVolume);
网格控制柄
网格句柄 是一个简单的类,它拥有它分配的缓冲区的所有权,允许网格的范围划分( RAII )。
它还用于封装不透明的网格数据。尽管网格数据本身是以数据类型(如 浮动 为模板的),但句柄提供了一种方便的方法来访问网格的元数据,而不必知道网格的数据类型 MIG 是什么。这很有用,因为您可以纯粹从句柄确定 GridType 。
下面的代码示例验证是否有包含级别集函数的 32 位浮点网格:
const nanovdb::GridMetaData* metadata = handle.gridMetaData();
if (!metadata->isLevelSet() || !metadata->gridType() == GridType::Float) throw std::runtime_error("Not the right stuff!");
网格缓冲区
NanoVDB 被设计成支持许多不同的平台, CPU , CUDA 甚至图形 api 。为了实现这一点,数据结构被存储在一个平坦的连续内存缓冲区中。
使这个缓冲区驻留在 CUDA 设备上很简单。为了完全控制,您可以使用 CUDA api 分配设备内存,然后将句柄的数据上载到其中。
void* d_gridData; cudaMalloc(&d_gridData, handle.size()); cudaMemcpy(d_gridData, handle.data(), handle.size(), cudaMemcpyHostToDevice); const nanovdb::FloatGrid* d_grid = reinterpret_cast(d_gridData);
NanoVDB 的 GridHandle 模板化在缓冲区类型上,缓冲区类型是其内存分配的包装器。它默认为使用主机系统内存的 主机缓冲区 ;然而, NanoVDB 还提供了 CUDA 缓冲器 ,以便轻松创建 CUDA 设备缓冲区。
auto handle = nanovdb::openToNanoVDB<nanovdb::CudaDeviceBuffer>(vdbGrid); handle->deviceUpload(); const nanovdb::FloatGrid* grid = handle->deviceGrid();
将数据流解释为纳米网格类型后,可以使用这些方法访问网格中的数据。有关更多详细信息,请参阅相关 API 的文档。本质上,它反映了 OpenVDB 中只读方法的基本子集。
auto hostOrDeviceOp = [grid] __host__ __device__ (nanovdb::Coord ijk) -> float { // Note that ReadAccessor (see below) should be used for performance. return grid->tree().getValue(ijk); };
可以构造自定义缓冲区来处理不同的内存空间。有关创建可与图形 API 交互操作的缓冲区的示例的更多信息,请参阅存储库中的示例。
致使
由于 NanoVDB 网格提供了一个紧凑的只读 VDB 树,因此它们很适合渲染任务。光线将 VDB 网格跟踪到图像中。使用每线程一条光线,并使用一个自定义的 雷吉诺 functor 生成光线,该函数接受像素偏移并创建世界空间光线。完整的代码在存储库示例中可用。
考虑到沿射线采样具有空间相干性这一事实,可以使用 读写器 来加速采样。当光线向前移动时,这会缓存树遍历堆栈,从而允许自底向上的树遍历,这比传统的自上而下遍历要快得多,后者涉及相对较慢的无界根节点。
auto renderTransmittanceOp = [image, grid, w, h, rayGenOp, imageOp, dt] __host__ __device__ (int i) { nanovdb::RaywRay = rayGenOp(i, w, h); // transform the ray to the grid's index-space... nanovdb::Ray iRay = wRay.worldToIndexF(*grid); // clip to bounds. if (iRay.clip(grid->tree().bbox()) == false) { imageOp(image, i, w, h, 1.0f); return; } // get an accessor. auto acc = grid->tree().getAccessor(); // integrate along ray interval... float transmittance = 1.0f; for (float t = iRay.t0(); t < iRay.t1(); t+=dt) { float sigma = acc.getValue(nanovdb::Coord::Floor(iRay(t))); transmittance *= 1.0f - sigma * dt; } imageOp(image, i, w, h, transmittance ); };
由于光线与水平集网格相交是一项常见任务, NanoVDB 实现了一个零交叉功能,并使用分层 DDA ( HDDA )作为沿光线的根搜索的一部分来清空空间跳跃(图 5 )。有关 HDDA 的更多信息,请参阅 OpenVDB 中高效光线行进的分层数字微分分析仪 。下面是代码示例:
... auto acc = grid->tree().getAccessor(); // intersect with zero level-set... float iT0; nanovdb::Coord ijk; float v; if (nanovdb::ZeroCrossing(iRay, acc, ijk, v, iT0)) { // convert intersection distance (iT0) to world-space float wT0 = iT0 * grid->voxelSize(); imageOp(image, i, w, h, wT0); } else { imageOp(image, i, w, h, 0.0f); } ...
碰撞检测
碰撞检测和解决是 NanoVDB 的另一项任务,因为它们通常需要有效地查找实体碰撞对象的有符号距离值。窄带电平集表示非常理想,因为它们用符号对内部/外部拓扑信息(碰撞检测所需)进行了紧凑编码。此外,最近点变换(冲突解决所需的)很容易从水平集函数的梯度计算。
下面的代码示例是一个用于处理冲突的函数。使用 读写器 是很有用的,因为用于冲突解决的梯度计算涉及到同一空间附近的多个提取。
auto collisionOp = [grid, positions, velocities, dt] __host__ __device__ (int i) { nanovdb::Vec3f wPos = positions[i]; nanovdb::Vec3f wVel = velocities[i]; nanovdb::Vec3f wNextPos = wPos + wVel * dt; // transform the position to a custom space... nanovdb::Vec3f iNextPos = grid.worldToIndexF(wNextPos); // the grid index coordinate. nanovdb::Coord ijk = nanovdb::Coord::Floor(iNextPos); // get an accessor. auto acc = grid->tree().getAccessor(); if (tree.isActive(ijk)) { // are you inside the narrow band? float wDistance = acc.getValue(ijk); if (wDistance <= 0) { // are you inside the levelset? // get the normal for collision resolution. nanovdb::Vec3f normal(wDistance); ijk[0] += 1; normal[0] += acc.getValue(ijk); ijk[0] -= 1; ijk[1] += 1; normal[1] += acc.getValue(ijk); ijk[1] -= 1; ijk[2] += 1; normal[2] += acc.getValue(ijk); normal.normalize(); // handle collision response with the surface. collisionResponse(wPos, wNextPos, normal, wDistance, wNextPos, wNextVel); } } positions[i] = wNextPos; velocities[i] = wNextVel; };
同样,完整的代码可以在存储库中找到。
基准
NanoVDB 被开发成在主机和设备上同样运行良好。使用 modernCUDA 中的扩展 lambda 支持,您可以轻松地在两个平台上运行相同的代码。
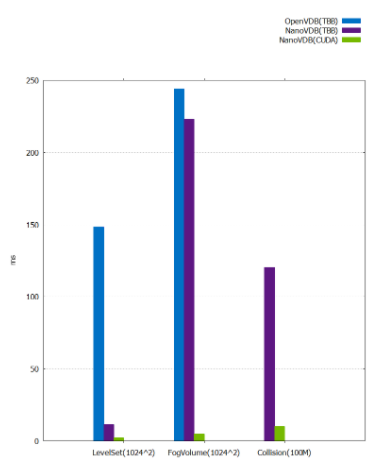
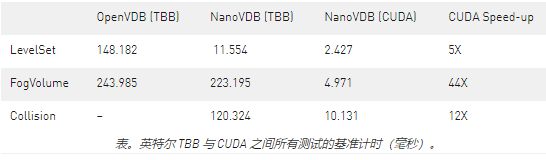
本节包括比较英特尔线程构建块和 CPU CUDA 上光线跟踪和碰撞检测性能的基准测试。计时以毫秒为单位,与 NVIDIA NVIDIA 8000 相比,是在 Xeon E5-2696 v4 x2 –( 88 个 CPU 线程)上生成的。使用的 FogVolume 是兔子云, LevelSet 是 dragon 数据集。两者都可以从 OpenVDB 网站下载。渲染的分辨率为 1024×1024 。这次碰撞试验模拟了一亿颗弹道粒子。
虽然基准测试(图 6 和下表)显示了 NanoVDB 高效表示加速 CPU 上 OpenVDB 的好处,但它真正突出了使用 GPU 对 VDB 数据进行只读访问以进行碰撞检测和光线跟踪的好处。
结论
NanoVDB 是一个小而强大的库,它通过使用 GPUs 来加速某些 OpenVDB 应用程序。开源存储库现在可用了!要下载源代码、构建示例
关于作者
Wil Braithwaite 在伦敦和洛杉矶的工作室工作了 15 年的视觉特效。他的职位包括研究、技术指导、合成、 CG 监督和 MOCAP 监督。他开创了图形硬件在 VFX 管道中的应用,在 NVIDIA 担任高级应用工程师,专门从事咨询、培训和使用 NVIDIA 技术协助 VFX 工作室项目的开发。
Ken Museth 是模拟技术的高级主管,并于 2020 年初加入 NVIDIA ,当时他发起了 NanoVDB 的开发。他以前在开发虚拟现实技术的时候,一直致力于虚拟现实的开发。他是 VDB 的创建者和 OpenVDB 的首席架构师,也是其技术指导委员会的主席。此外,肯在 SpaceX 公司工作了六年,对新的猛禽火箭发动机进行大规模流体动力学模拟。在 2017 年加入 Weta 之前,他在梦工厂动画和数字领域工作了 10 年,在此之前,他曾在加州理工学院和林科平大学担任研究员和全职教授。他拥有哥本哈根大学量子动力学博士学位,并获得电影艺术与科学学院颁发的技术成就奖。肯是 SIGGRAPH 2020 技术论文委员会成员。
审核编辑:郭婷
-
中断中的上下文切换详解2023-03-23 1544
-
如何分析Linux CPU上下文切换问题2022-05-05 3133
-
CAD中怎么进行碰撞检测?CAD碰撞检测教程2021-05-19 7314
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 1151
-
Linux驱动中断上下文中会发生什么结果实验测试2020-09-18 1330
-
进程上下文与中断上下文的理解2018-12-11 3452
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 3926
-
初学OpenGL:什么是绘制上下文2018-04-28 2945
-
基于时间上下文的跟踪检测方法2017-12-19 882
-
基于低秩重检测的多特征时空上下文的视觉跟踪2017-12-15 987
-
基于上下文相似度的分解推荐算法2017-11-27 1010
-
基于局部敏感直方图的时空上下文跟踪_葛骁倩2017-03-19 748
-
基于Pocket PC的上下文菜单实现2011-07-25 1015
-
基于交互上下文的预测方法2009-10-04 738
全部0条评论

快来发表一下你的评论吧 !
