

这4种CPU错误该如何找到,没找到会有什么后果
描述
Codasip 验证总监 Philippe Luc 分享了他对验证工程师应注意哪些错误的看法。
您是否知道在设计复杂的处理器内核时可能会出现 1,000 到 2,000 个错误?真的,一千个虫子?嗯,这就是经验告诉我们的。并非所有的错误都是生来平等的:它们的重要性和后果可能会有很大差异。让我们来看看 4 类CPU 错误,如何找到它们,如果我们没有找到它们会给用户带来什么后果。
类型 1:验证工程师容易发现的处理器 BUG
“哦,我忘记了分号”。是的,这是一个错误。很容易检测到,通常是您在编译时直接发现的错误。除了睁大眼睛,没有其他办法可以避免这些.
“哦,原来规范的一部分没有实现”。这是另一个容易找到的 CPU 错误,您可以通过任何体面的测试平台找到 - 前提是存在显式测试。在这种情况下,执行该功能的第一个简单测试将失败。您的处理器验证团队需要做什么?确保你有详尽的测试。另一方面,设计团队需要努力仔细阅读规范,并在开发过程中遵循规范中的任何更改。
换句话说,简单的错误是通过运行一个测试该功能的测试来发现的。它的(坏)行为是系统性的,而不是时间条件。详尽的验证是找到此类 CPU 错误的关键。代码覆盖率会帮助你,但绝对不够。如果 RTL 中没有对某个特性进行编码,那么覆盖率如何报告它缺失?代码审查- 手头有规范 - 绝对有帮助。
类型 2:验证团队喜欢找到的极端案例
极端情况下的CPU 错误更难找到,需要强大的测试平台。运行该功能的简单测试用例正确通过,即使有随机延迟。很多时候,当异步事件加入聚会时,您会发现这些错误。例如,一个中断恰好在 2 条指令之间以精确的时间到达。或者缓存中的一行在存储缓冲区想要合并时被驱逐。要解决这些错误,您需要一个能够兼顾指令、参数和延迟的测试平台,以便执行所有可能的指令和事件交错。显然,一个好的检查者应该发现任何与预期的偏差。
在这种情况下,代码覆盖率有帮助吗?不幸的是没有。仅仅因为错误的情况是已经单独涵盖的几个事件的组合。在这里,条件覆盖或分支覆盖可能会有所帮助。但分析起来很痛苦,而且最终很少有好处。
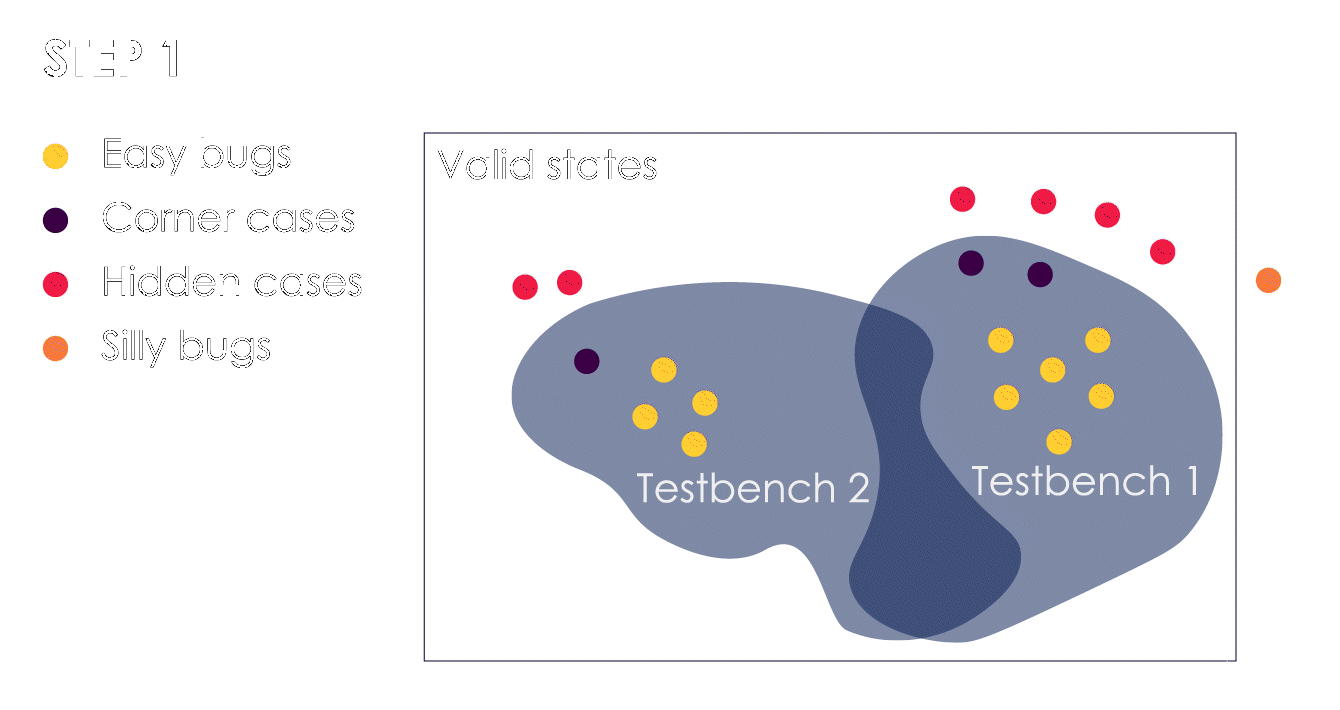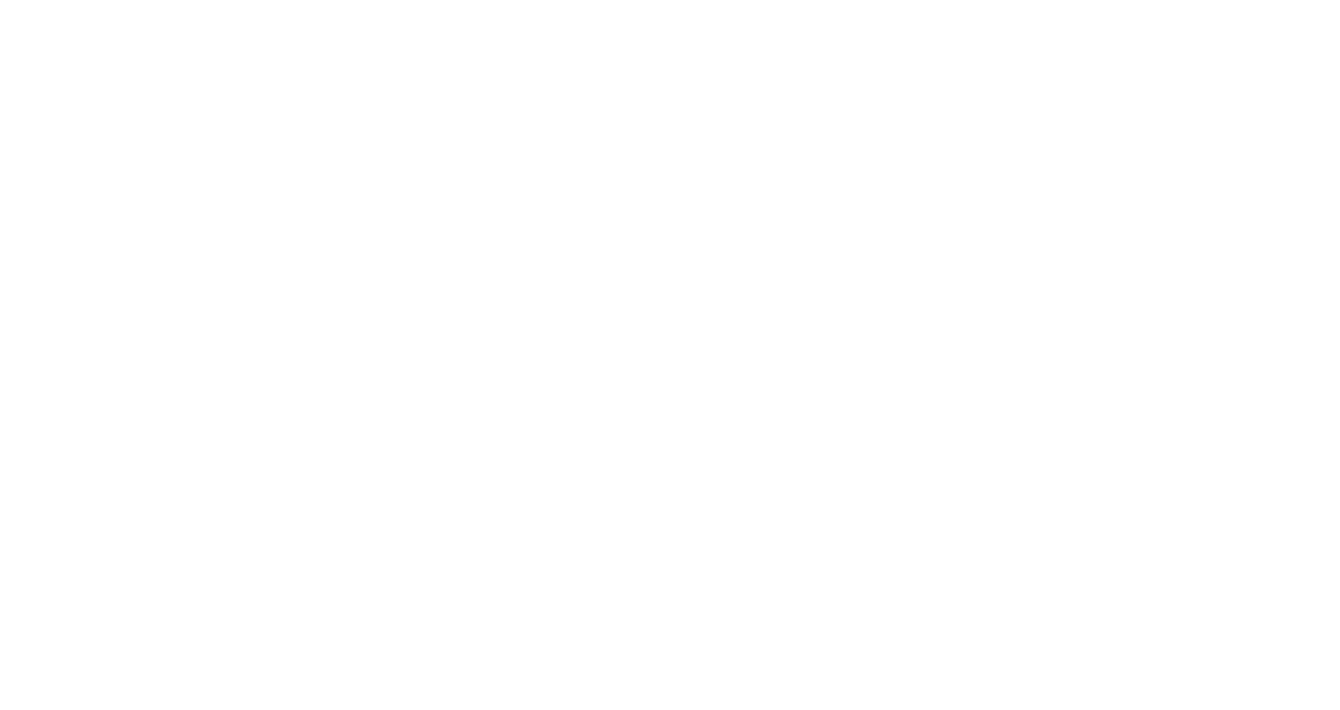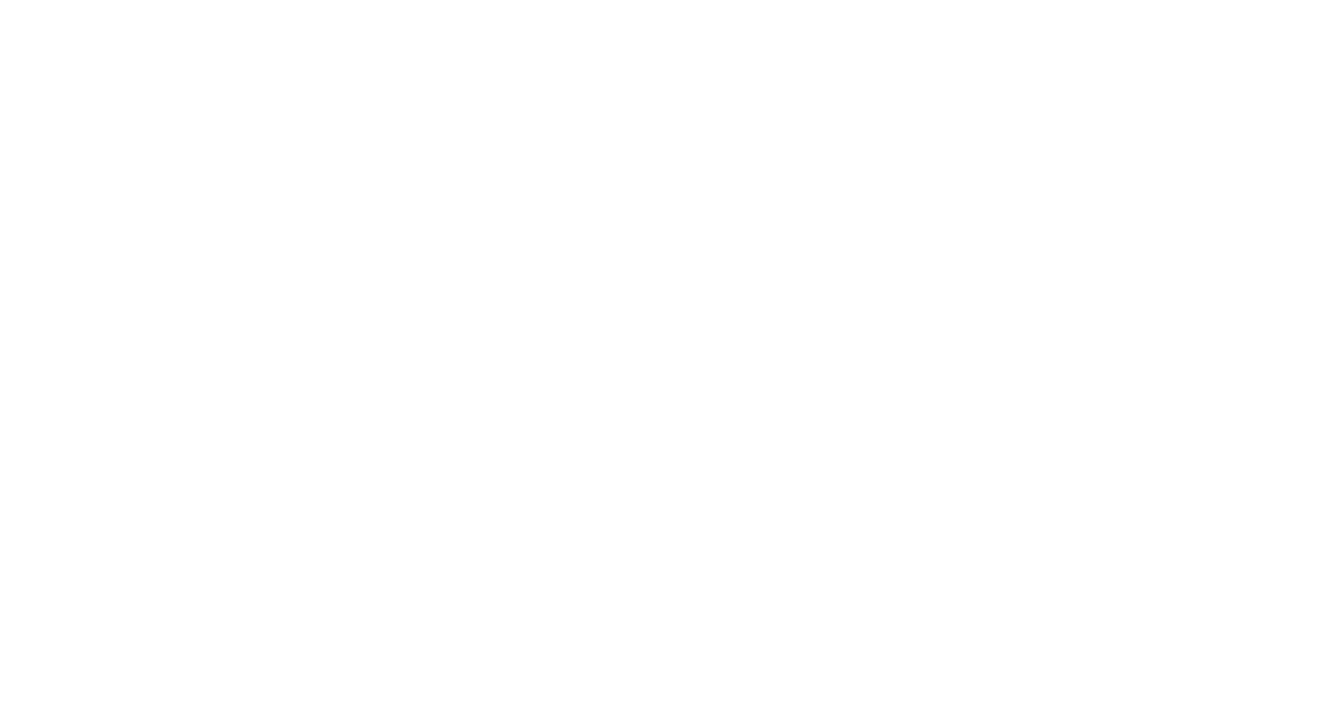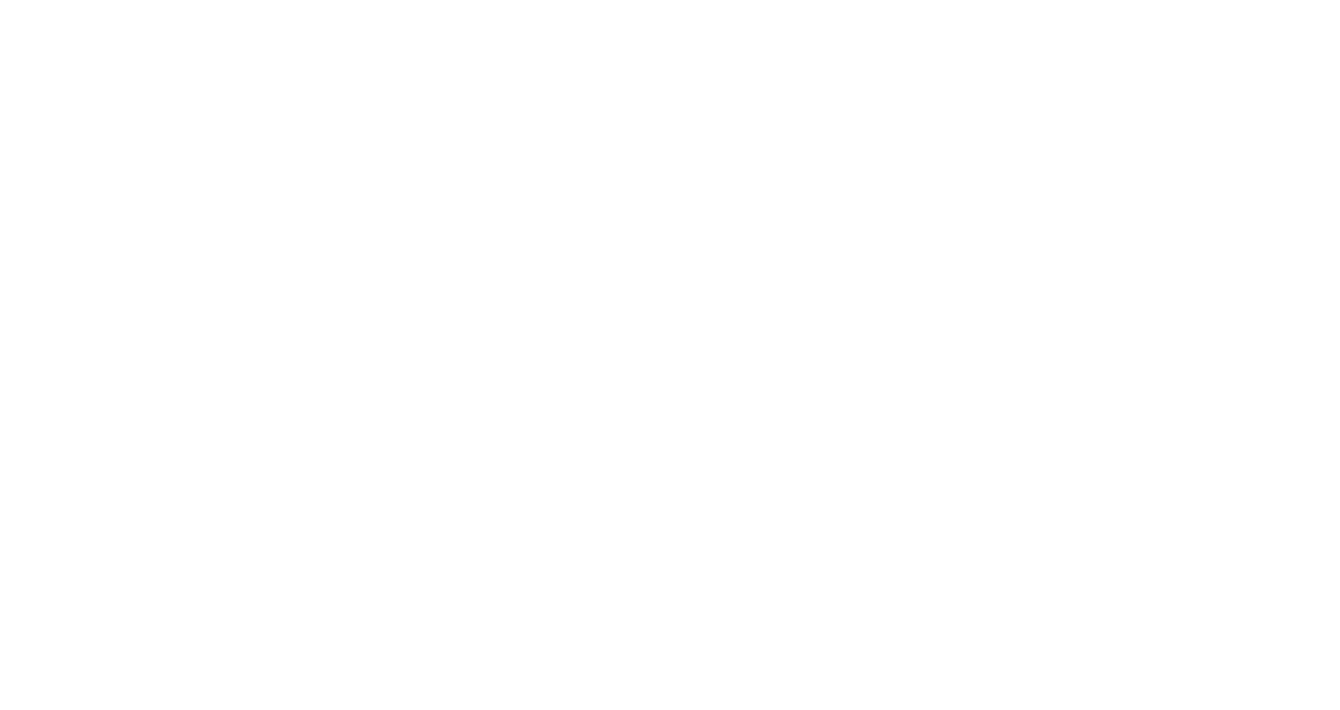
1. 测试台发现了简单的错误和一些极端情况。2.我们从这些极端案例中学习,以改进测试平台并扩大验证范围。这样做,我们会发现隐藏的案例变成了极端案例(或简单的错误)。3. 由于Bug“成群结队”,我们可以根据最后发现的Bug进一步扩大我们的验证范围。当我们遇到一个愚蠢的错误时,我们知道我们的测试已经足够远了。
类型 3:意外发现的隐藏 CPU 错误 - 或由客户发现
隐藏的错误是由客户发现的(这是不好的),或者是偶然发现的(在内部,在发布之前)。在这两种情况下,这意味着验证方法无法找到它们。
如果您使用不同的测试台或环境,您可能会因为刺激不同而找到其他案例。很公平。那么,我们所说的“偶然发现”是什么意思?这是随机测试平台方法的限制。
对于随机刺激,测试平台通常会生成“相同”的东西。如果你掷骰子得到一个随机数,那么连续 10 次得到数字 6 的机会很少。准确地说,6000 万分之一的机会。对于具有 100 条不同指令的RISC-V CPU,(等概率的)随机指令生成器每 10²⁰ 次只有 1 次机会连续生成 10 次相同的指令。只是魔方不同位置数量的两倍……在 10 级流水线处理器上,使用所有流水线级上存在的相同指令对其进行测试并非不合理。如果你不调整你的随机约束,祝你好运......
类型 4:现实生活中不会发生的愚蠢错误
您可能会过度寻找极端案例和隐藏案例,最终创建的测试太愚蠢了。
在连接调试器的同时在每个周期来回更改字节顺序可能永远不会在消费产品上发生,如果 CPU 错误的后果对客户来说永远不可见,那么它就不是真正的错误。如果您在复制文件时故意拔下 U 盘,而文件已损坏,我认为这不是错误。如果某些操作导致 USB 控制器挂起,那么是的,这是一个错误。
谨防扩大验证范围。当发现愚蠢的案例时,您可能将工程工作投入到错误的地方。
您可以应用不同的验证技术在客户之前有效地发现 CPU 错误。在 Codasip,我们使用多个组件测试平台、各种随机测试生成器、随机刺激器和其他几种技术来验证我们的产品。随着项目的发展,我们开发了这些技术以拥有强大的验证方法。在我们的博客文章中了解更多信息,其中我们解释了我们如何不断改进我们的验证方法。
审核编辑:符乾江
-
找不到这个啊?在哪里能找到这图标2013-04-23 2108
-
这是什么函数,没找到?2015-10-09 2202
-
请教各位大神,在proteus中绘制LM3409HV调光电路时,怎么找到LM3409HV这个芯片,找了好久没找到2016-07-15 4892
-
求助,急,找了好多都没找到!2016-08-26 3601
-
Labview 测量I/O里面没找到研华的信息?2017-08-10 3520
-
请问在CCS3.3里,运行时有一个菜单“Animate”,CCS4.2里没找到对应的菜单是我没找到还是没有?2018-07-30 2389
-
请问TMDSCNCD28035图纸没找到是在哪里2018-09-11 2030
-
没找到STM8S库中的ABS(X)功能2019-01-15 2746
-
如何找到有错误的符号?2019-06-27 1962
-
C6748没找到它的CSL文件怎么办?2020-08-11 1412
-
如何找到所需网站的IP地址以及如何找到IP地址的来源2019-12-10 6701
-
如何找到烧坏电阻的值2023-02-16 3838
-
如何快速找到PCB中的GND?2023-12-07 2601
-
西门子博途中CPU对错误的反应2023-12-11 2771
-
找到CAN总线(故障)节点的三种办法2024-02-02 3169
全部0条评论

快来发表一下你的评论吧 !
