

Multilingual多语言预训练语言模型的套路
描述
Multilingual是NLP中的研究热点之一,其中的一个研究方向是如何构建多语言预训练语言模型,实现不同语言的在隐空间的对齐,一个模型支持多语种的NLP任务,同时利用数据丰富的语言提升数据较少的语言效果。这篇文章就为大家整理了Multilingual多语言预训练语言模型的套路,包括XLM、XLM-R、ERNIE-M、Unicoder、ALM等5个经典模型,以及这些模型之间的演进关系。
1 XLM:多语言预训练的起点
随着BERT、GPT预训练语言模型的兴起,这些方法也被自然而然的用在了多语言预训练任务上。通过在BERT、GPT等成熟的NLP模型结构上同时学习多个语言的语料,并设计多语言对齐任务,实现了Multilingual预训练语言模型,应用到下游各种语言的任务中。
Facebook在Crosslingual language model pretraining(NIPS 2019)一文中提出XLM预训练多语言模型,整体思路基于BERT,并提出了针对多语言预训练的3个优化任务。后续很多多语言预训练工作都建立在XLM的基础上,我们来详细看看XLM的整体训练过程。
首先,需要构造一个多语言的vocabulary list。XLM让所有语言共用同一个词表,利用Byte Pair Encoding (BPE)的方法从所有语言中采样文本构造词典。为了提升low-resource语言采样比例,缓解预训练模型偏向high-resource语言,在采样过程中会对各个语言采样比例做一定的矫正。通过多种语言共用一个BPE词表的方法,便于不同语言的token embedding在隐空间对齐,也能提取到不同语言共用的token。
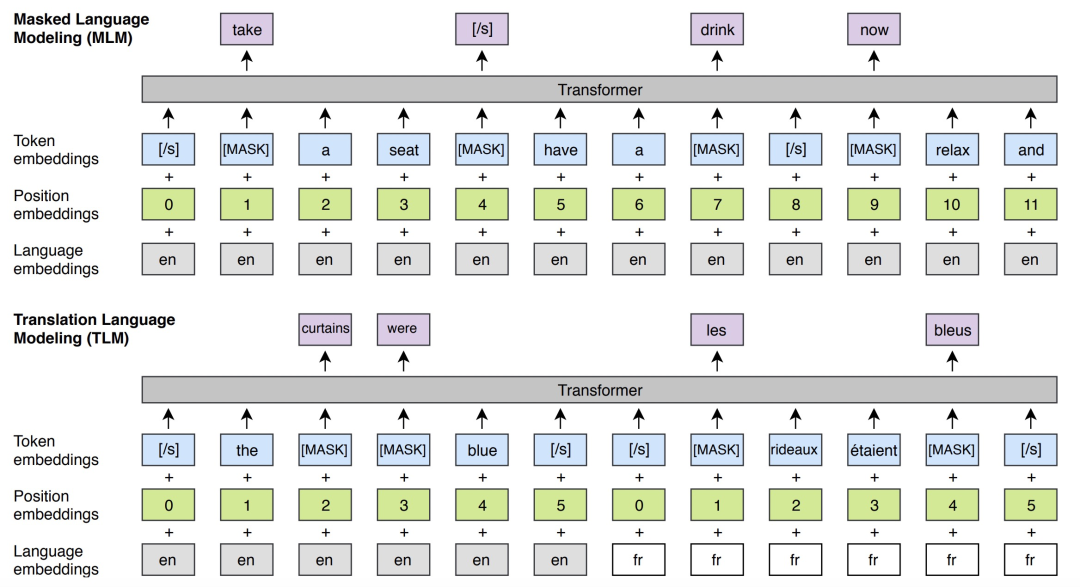
模型预训练主要包括两个任务,分别是MLM和TLM。其中MLM和BERT中采用的方式类似,mask部分token进行预测。TLM是Translation Language Model,这个任务为了引入多语言的对齐关系,将两种语言的文本拼接到一起采用mask token的方式预测。这样在预测过程中,既可以根据本语言的信息预测,也可以根据另一种语言的信息预测。此外,XLM引入了language embedding,用来标明每个位置上的token属于哪个语言。XLM的两个预训练任务如下图所示。
2 XLM-R:更细致的XLM
Unsupervised cross-lingual representation learning at scale(ACL 2019)在XLM的基础上进一步分析了影响多语言预训练模型效果的因素,提出在100多种语言上预训练得到的XLM-R模型。下面列举了本文中的核心实验结论,揭示了不同的多语言训练方式对效果的影响。
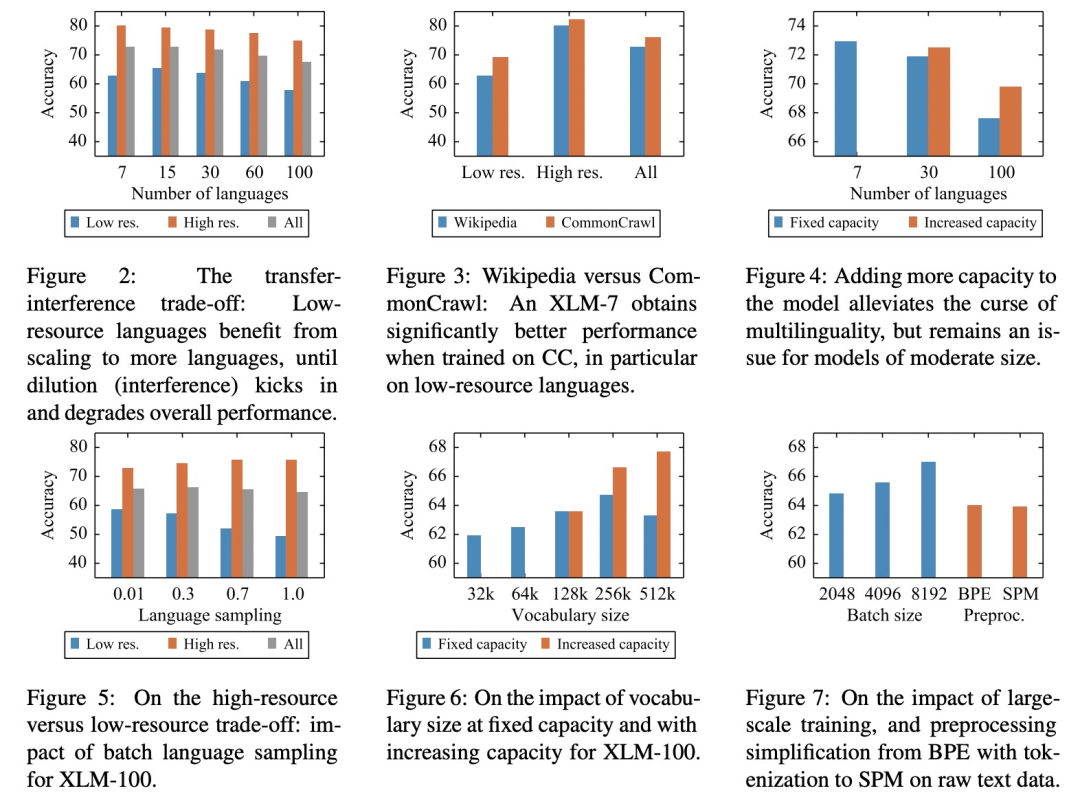
图2显示了随着预训练过程引入语言种类的变化,low resource语言的效果先上升后下降。这是因为在模型capacity一定的情况下,引入多种语言一方面会让low resource语言获得可迁移的知识,另一方面过多的语言也稀释了模型的capacity,每种语言能够使用的capacity减少,导致效果下降。而high resource语言的效果随着引入语言数量的增加是持续下降的。图4显示,增加模型尺寸可以缓解多语言稀释capacity的问题(7种语言和30种语言效果对比),但是引入100种语言后即使增加模型尺寸效果仍然不佳。
图5展示了不同语言采样权重变化的效果影响,low resource和high resource语言之间存在一定的矛盾性,因此随着采样偏向于high resource语言,low resource语言的效果越来越差。图6则展示了词典尺寸大小对效果的影响,词典尺寸增大,对应embedding层尺寸增加,可以比较明显的提升多语言预训练模型效果。
基于以上这些实验的分析,作者提出了基于RoBerta的XLM-R,在100余种语言、2.5T的数据上预训练,取得了在XNLI数据集上相比基础版XLM模型15%的效果提升。相比于XLM,XLM-R最大的区别之一是没有使用TLM这个预训练任务,所有预训练数据都是单语言的,不包括两个语言对齐的数据。
3 ERINE-M:回译的引入
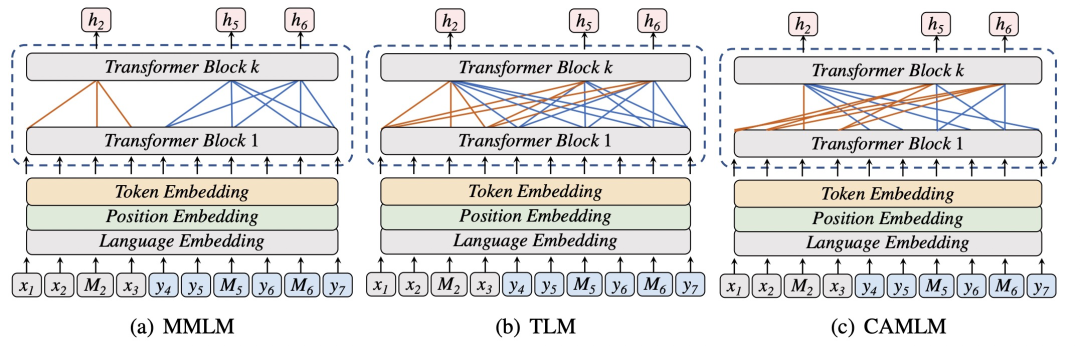
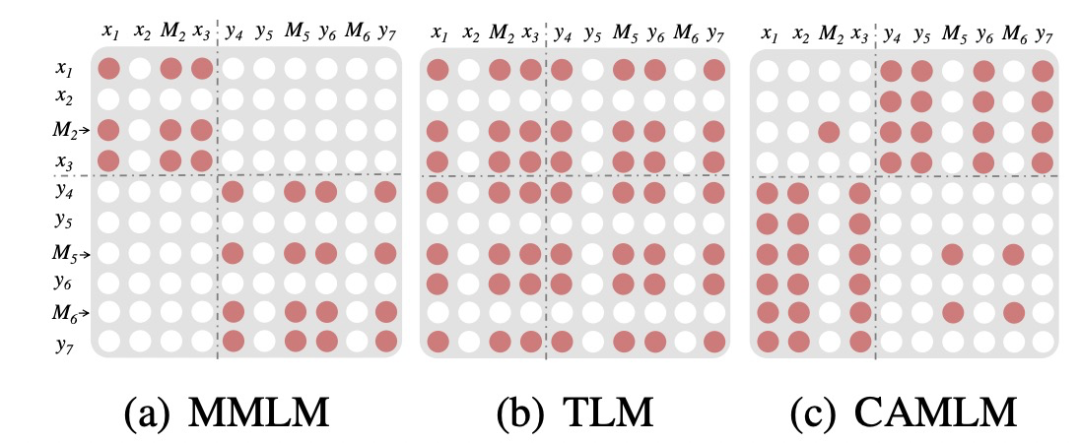
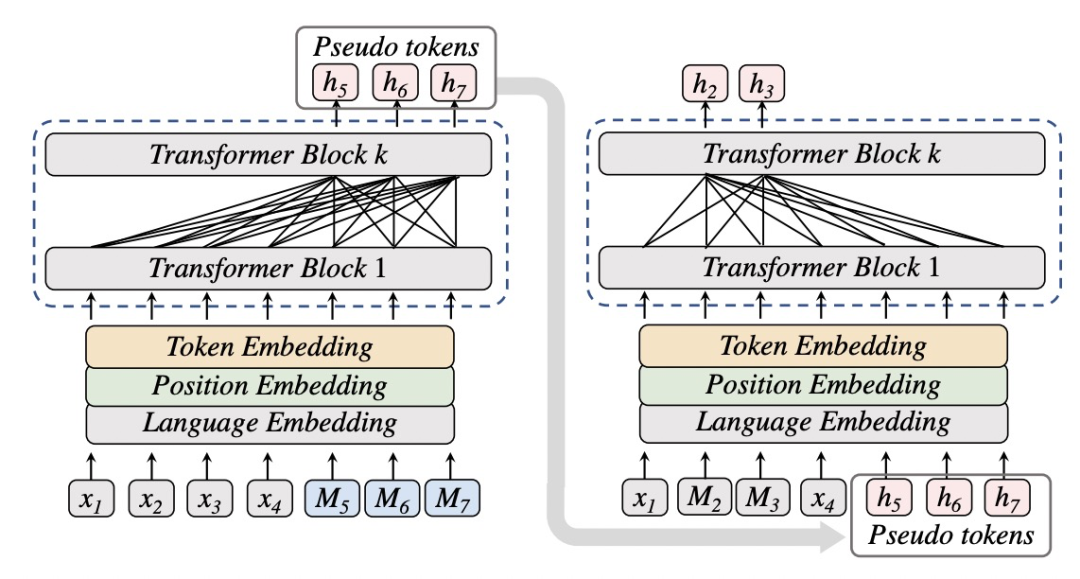
ERNIE-M: Enhanced multilingual representation by aligning cross-lingual semantics with monolingual corpora(EMNLP 2019)基于XLM-R提出了ERNIE-M模型,主要是在MMLM、TLM两个任务以外,新引入了CAMLM(Cross-attention Masked Language Modeling)和BTMLM(Back-translation Masked Language Modeling)两个额外的任务。其中CAMLM任务和TLM任务类似,都是用翻译文本对作为输入,预测被mask的token,区别在于TLM在预测一个mask token时可以同时参考两种语言的所有信息,而CAMLM在预测source句子中被mask的token时,只能使用target句子的信息;在预测target句子中被mask的token时,只能使用source句子的信息。实现上做了一个mask的操作,强制让模型只能用另一种语言的context预测本语言的mask token,提升模型的多语言对齐能力。CAMLM和MMLM、TLM等任务的区别如下图所示。
不论是TLM还是CAMLM,都需要使用parallel的句子,如果可用的parallel数据较少,就会影响对齐效果。因此,文中提出了第二个任务BTMLM,利用CAMLM学到的多语言之间的对齐关系,将回译任务融入到预训练中。核心思路是,使用CAMLM预训练好的模型,根据单语言语料生成另一种语言的伪数据,利用这个伪数据作为输入,构造parallel句子作为输入。BTMLM的示意图如下。第一步将单语言输入后面接mask,利用CAMLM预训练多语言模型生成mask部分的token,得到伪样本(即隐空间中当前样本在另一种样本下的翻译)。接下来,将伪样本作为输入,以MLM为目标,同时使用源句子和伪样本预测被mask掉的token。这种方式相当于一种数据增强手段,通过模型自动生成parallel数据,缓解了parallel数据不足的问题。
4 Unicoder:多语言对齐任务的优化
Unicoder: A Universal Language Encoder by Pre-training with Multiple Crosslingual Tasks(ACL 2019)提出了多语言预训练模型Unicoder。在XLM中,模型的训练任务主要是单语言的,Unicoder提出了3种新的多语言对齐任务来提升预训练多语言模型效果。
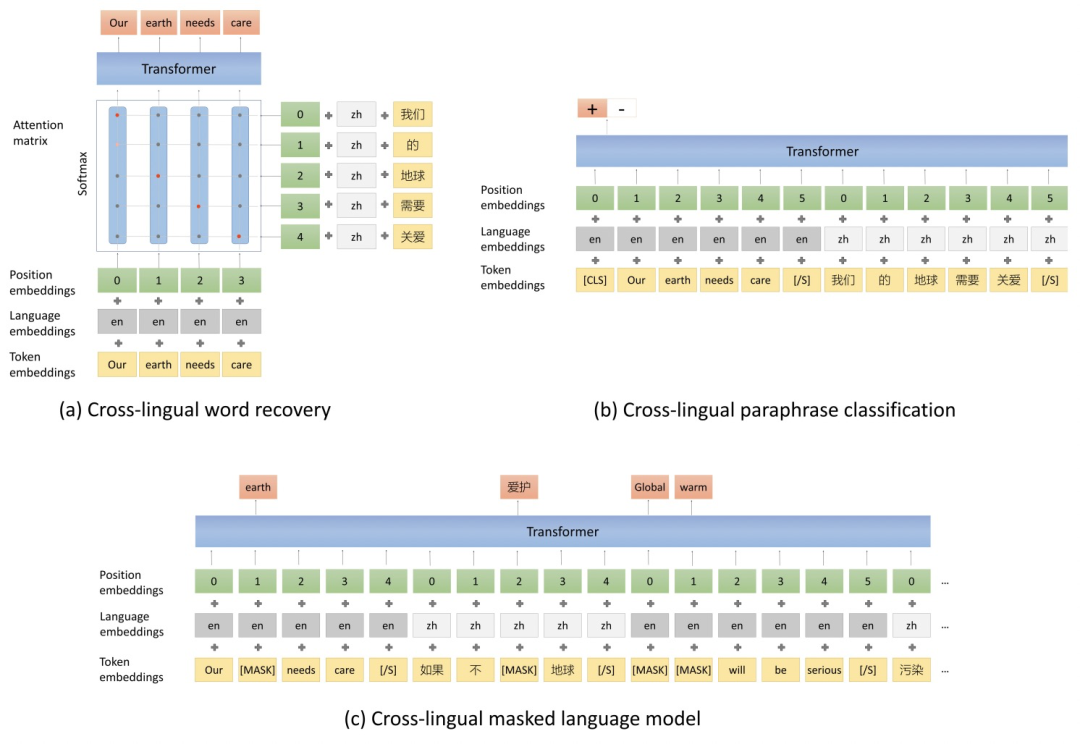
第一个任务是Cross-lingual Word Recovery,输入是两种语言的语句pair对(X,Y),然后利用attention的方法将X用Y表示,再利用这些表示还原X。这其实类似于一个基于attention的翻译任务,实现了不同语言之间的word alignment。
第二个任务是Cross-lingual Paraphrase Classification,是一个分类任务。输入同样是两个语言的句子对,预测这两个句子是否表达的是同一个含义。数据集的构造方法上,正样本采用机器翻译数据集的数据构造正样本。为了构造hard负样本,即语义在一定程度上相似但不是互为翻译的文本对,作者采用了Effective Parallel Corpus Mining using Bilingual Sentence Embeddings(2018)提出的hard negatives构造方法。先使用随机采样的负样本构造简单负样本训练一个baseline模型,再利用这个模型计算当前样本和所有负样本相似度,取相似度最高且又不是正样本的负样本,作为hard negatives。
第三个任务是Cross-lingual Masked Language Model,将一些文档级别翻译较好的数据集的两种语言进行重组,得到多语言document,在这种多语言document上以Mask Language Model为优化目标训练。三种不同的预训练任务如下图所示。
5 ALM:样本构造上的创新
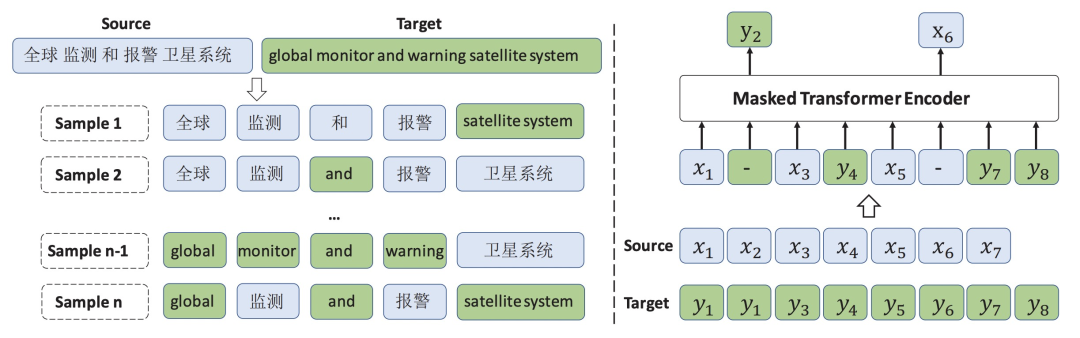
Alternating Language Modeling for Cross-Lingual Pre-Training(AAAI 2020)提出一种新的多语言模型预训练方式。之前的做法如XLM都是将多语言文本对拼接到一起,而本文提出的ALM方法通过将源语言中的部分短语替换成另一种语言,生成了多语言交替的样本作为训练样本,以Transformer为基础在这种样本上进行Mask Language Model的学习。这种方法强制让每次预测被mask掉的单词时,都要参考其他语言的信息,进一步缩小了不同语言在隐空间的距离。
6 总结
以上就是多语言预训练中5个经典模型的介绍。除了本文介绍的预训练语言模型外,对比学习、meta-learning等方法在Multilingual中也有很多应用。多语言任务还是非常重要的,尤其当今很多企业都展开国际化战略,拓展海外市场,多语言建模技术更成为不可缺少的能力。
审核编辑 :李倩
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
多语言综合信息服务系统研究与设计2009-04-01 509
-
SoC多语言协同验证平台技术研究2015-12-31 1068
-
基于Toradex多语言image的编译与MUI切换演示2017-09-18 1005
-
谷歌深度学习如何处理人类语言?2021-03-01 2022
-
多语言翻译新范式的工作:机器翻译界的BERT2021-03-31 4110
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2607
-
CogBERT:脑认知指导的预训练语言模型2022-11-03 1990
-
Firefly(流萤): 中文对话式大语言模型2023-04-07 8719
-
基于LLaMA的多语言数学推理大模型2023-11-08 1182
-
多语言开发的流程详解2023-11-30 2156
-
大语言模型(LLMs)如何处理多语言输入问题2024-03-07 1618
-
大语言模型的预训练2024-07-11 1928
-
ChatGPT 的多语言支持特点2024-10-25 2601
-
京东多语言质量解决方案2026-01-13 1300
全部0条评论

快来发表一下你的评论吧 !
