

分享一份面试真题(附答案)
描述
前言
分享了一份面试真题,整理了一下答案给大家。如果有不正确的,欢迎指出哈,一起进步。
- Redis的key和value可以存储的最大值分别是多少?
- 怎么利用Redis实现数据的去重?
- Redis什么时候需要序列化?Redis序列化的方式有哪些?
- MySQL的B+树的高度怎么计算?
- 线程池的状态有哪些?获取多线程并发执行结果的方式有哪些?
- 线程池原理?各个参数的作用。
- ThreadLocal的使用场景有哪些?原理?内存泄漏?
- kafka是如何保证消息的有序性?
- Nacos的选举机制了解嘛?说下Raft算法?
- 聊一聊TCC补偿机制
1、Redis的key和value可以存储的最大值分别是多少?
-
虽然Key的大小上限为
512M,但是一般建议key的大小不要超过1KB,这样既可以节约存储空间,又有利于Redis进行检索。 -
value的最大值也是
512M。对于String类型的value值上限为512M,而集合、链表、哈希等key类型,单个元素的value上限也为512M。
2. 怎么利用Redis实现数据的去重?
-
Redis的
set:它可以去除重复元素,也可以快速判断某一个元素是否存在于集合中,如果元素很多(比如上亿的计数),占用内存很大。 -
Redis的
bit:它可以用来实现比set内存高度压缩的计数,它通过一个bit设置为1或者0,表示存储某个元素是否存在信息。例如网站唯一访客计数,可以把user_id作为 bit 的偏移量 offset,如设置为1表示有访问,使用1 MB的空间就可以存放800多万用户的一天访问计数情况。 -
HyperLogLog:实现超大数据量精确的唯一计数都是比较困难的,HyperLogLog可以仅仅使用 12 k左右的内存,实现上亿的唯一计数,而且误差控制在百分之一左右。 -
bloomfilter布隆过滤器:布隆过滤器是一种占用空间很小的数据结构,它由一个很长的二进制向量和一组Hash映射函数组成,它用于检索一个元素是否在一个集合中
关于布隆过滤器,关注 数据分析与开发 公号,回复 布隆过滤器 即可获取。
3. Redis什么时候需要序列化?Redis序列化的方式有哪些?
大家先回忆下Java序列化,什么时候需要序列化?
- 序列化:将 Java 对象转换成字节流的过程。
- 反序列化:将字节流转换成 Java 对象的过程。
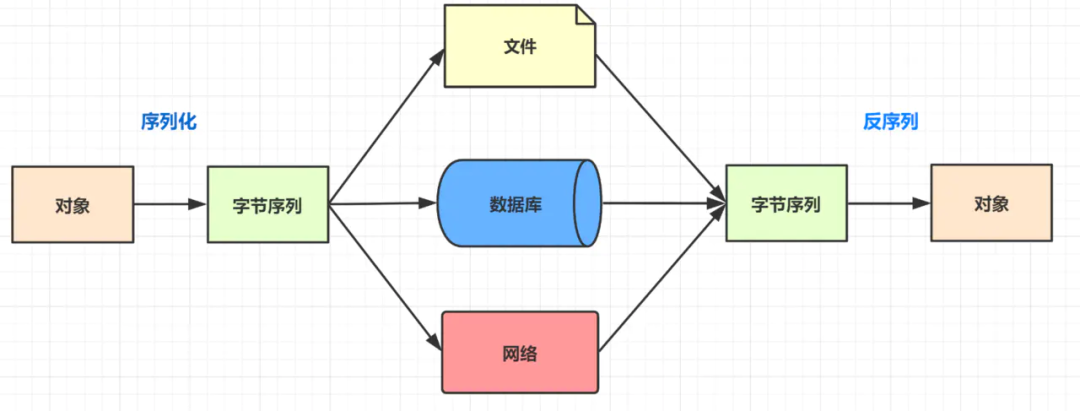
为什么需要序列化呢?
打个比喻:作为大城市漂泊的码农,搬家是常态。当我们搬书桌时,桌子太大了就通不过比较小的门,因此我们需要把它拆开再搬过去,这个拆桌子的过程就是序列化。而我们把书桌复原回来(安装)的过程就是反序列化啦。
- 比如想把内存中的对象状态保存到一个文件中或者数据库中的时候(最常用,如保存到redis);
- 再比喻想用套接字在网络上传送对象的时候,都需要序列化。
RedisSerializer接口 是 Redis 序列化接口,用于 Redis KEY 和 VALUE 的序列化
- JDK 序列化方式 (默认)
- String 序列化方式
- JSON 序列化方式
- XML 序列化方式
4. MySQL的B+树的高度怎么计算?(比如有100w的数据,字段为int类型)
InnoDB存储引擎最小储存单元是页,一页大小就是16k。
B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
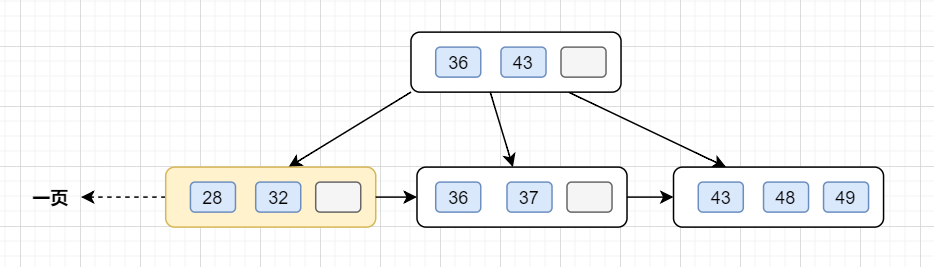
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
- 如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16.
- 非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。
5、线程池的状态有哪些?获取多线程并发执行结果的方式有哪些?
线程池和线程的状态是不一样的哈,线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//线程池状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
线程池各个状态切换状态图如下:
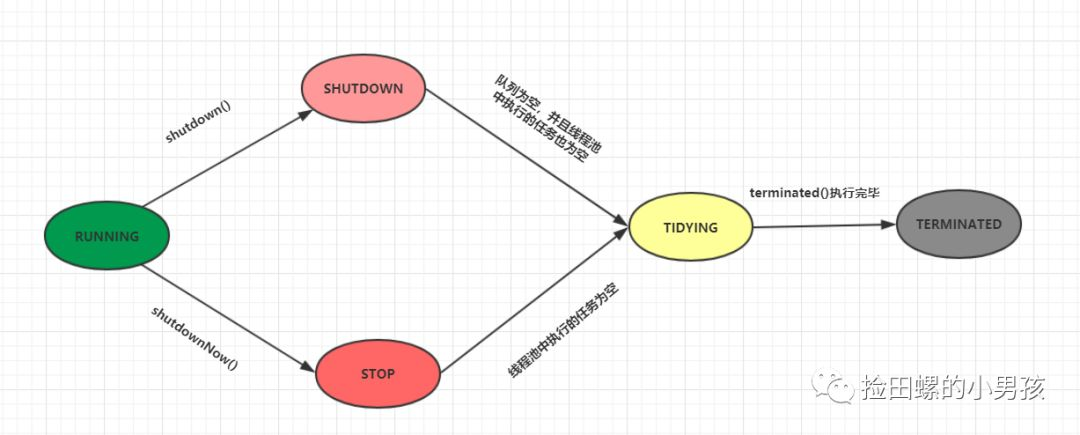
RUNNING
- 该状态的线程池会接收新任务,并处理阻塞队列中的任务;
-
调用线程池的
shutdown()方法,可以切换到SHUTDOWN状态; -
调用线程池的
shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
- 该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
- 该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- 线程池中执行的任务为空,进入TIDYING状态;
TIDYING
- 该状态表明所有的任务已经运行终止,记录的任务数量为0。
-
terminated()执行完毕,进入TERMINATED状态
TERMINATED
- 该状态表示线程池彻底终止
6. 线程池原理?各个参数的作用。
ThreadPoolExecutor的构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
几个核心参数的作用:
- corePoolSize:线程池核心线程数最大值
- maximumPoolSize:线程池最大线程数大小
- keepAliveTime:线程池中非核心线程空闲的存活时间大小
- unit:线程空闲存活时间单位
- workQueue:存放任务的阻塞队列
- threadFactory:用于设置创建线程的工厂,可以给创建的线程设置有意义的名字,可方便排查问题。
- handler: 线城池的饱和策略事件,主要有四种类型。
四种饱和拒绝策略
- AbortPolicy(抛出一个异常,默认的)
- DiscardPolicy(直接丢弃任务)
- DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
- CallerRunsPolicy(交给线程池调用所在的线程进行处理)
线程池原理:
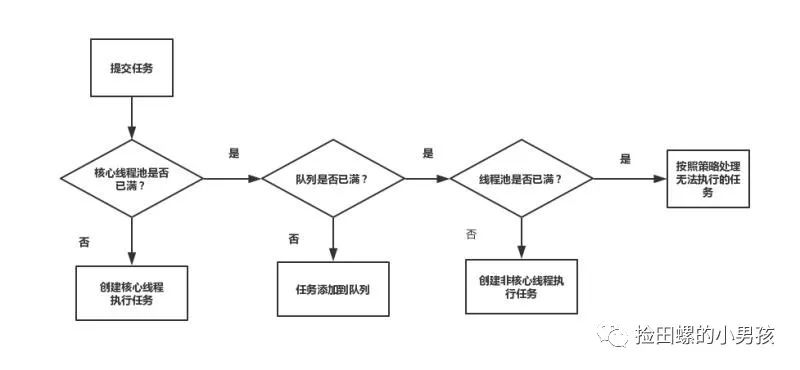
- 提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
- 如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
- 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
- 如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
为了形象描述线程池执行,我打个比喻:
- 核心线程比作公司正式员工
- 非核心线程比作外包员工
- 阻塞队列比作需求池
- 提交任务比作提需求
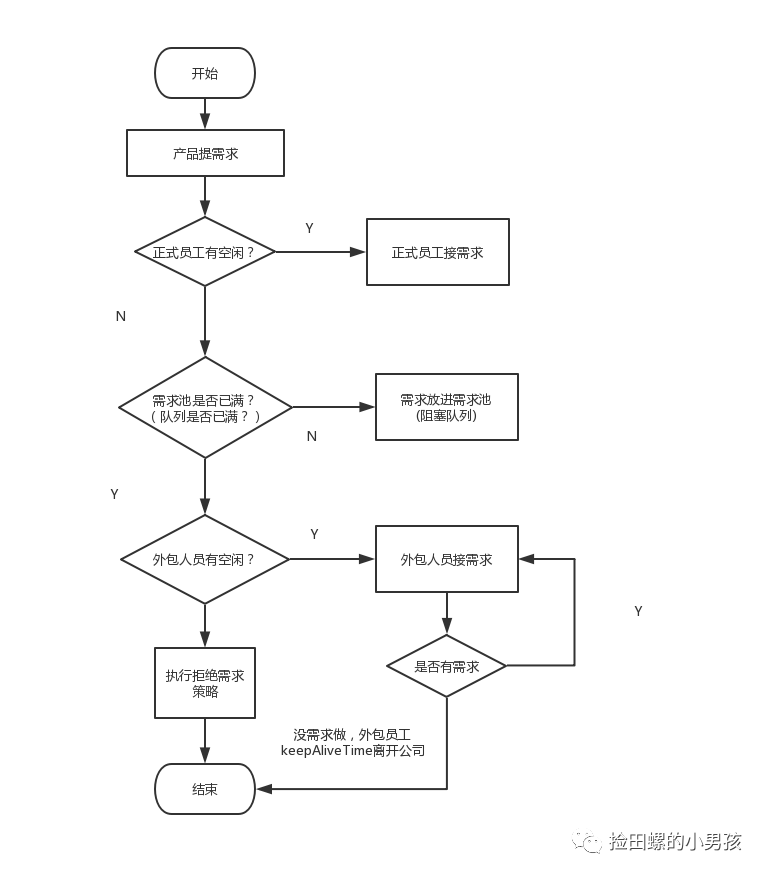
- 当产品提个需求,正式员工(核心线程)先接需求(执行任务)
- 如果正式员工都有需求在做,即核心线程数已满),产品就把需求先放需求池(阻塞队列)。
- 如果需求池(阻塞队列)也满了,但是这时候产品继续提需求,怎么办呢?那就请外包(非核心线程)来做。
- 如果所有员工(最大线程数也满了)都有需求在做了,那就执行拒绝策略。
- 如果外包员工把需求做完了,它经过一段(keepAliveTime)空闲时间,就离开公司了。
7. ThreadLocal的使用场景有哪些?原理?内存泄漏?
ThreadLocal,即线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
ThreadLocal的应用场景
- 数据库连接池
- 会话管理中使用
ThreadLocal内存结构图:
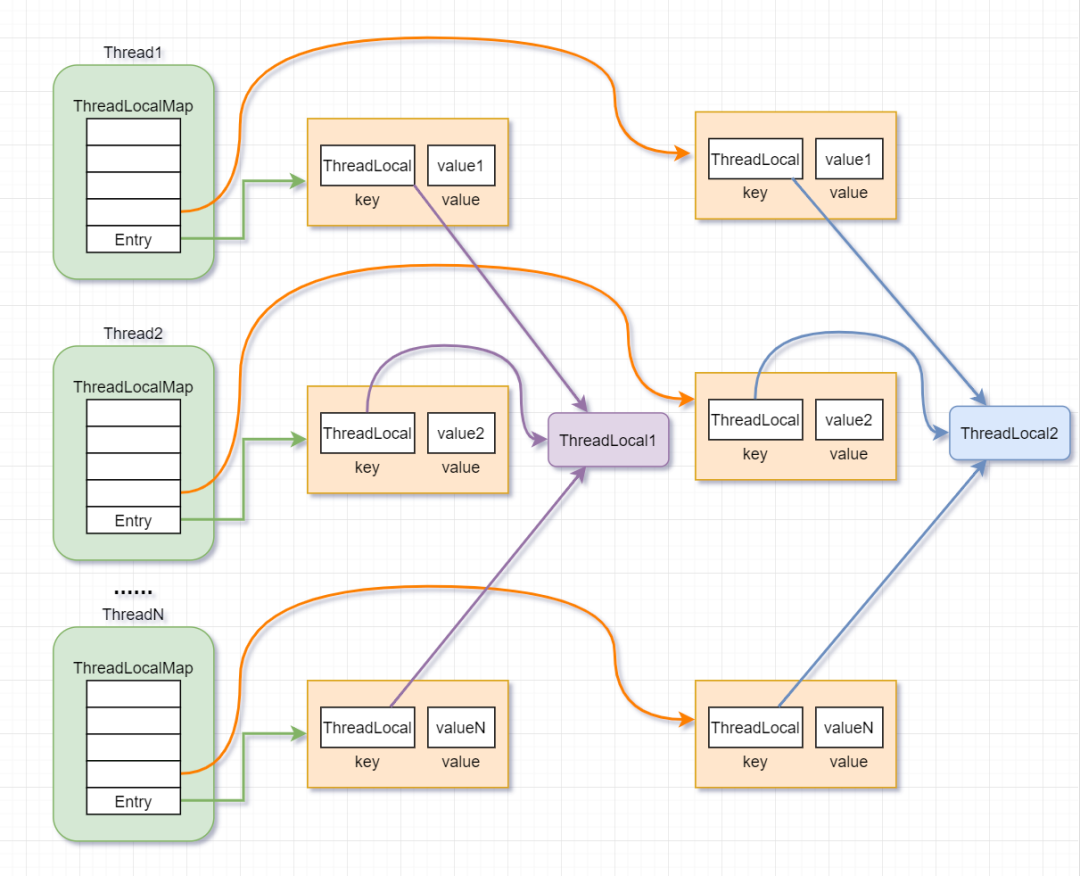
ThreadLocal原理
- Thread对象中持有一个ThreadLocal.ThreadLocalMap的成员变量。
- ThreadLocalMap内部维护了Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocal 内存泄露问题
先看看一下的TreadLocal的引用示意图哈,
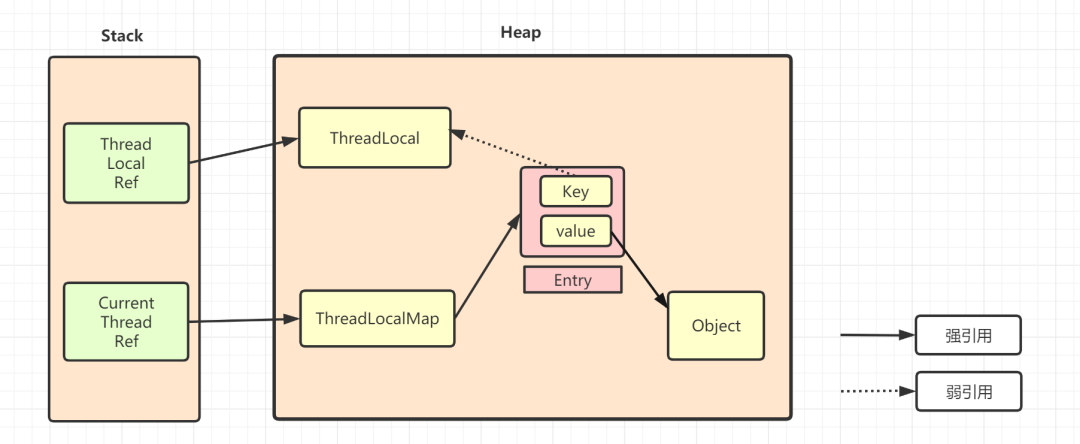
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用,如下
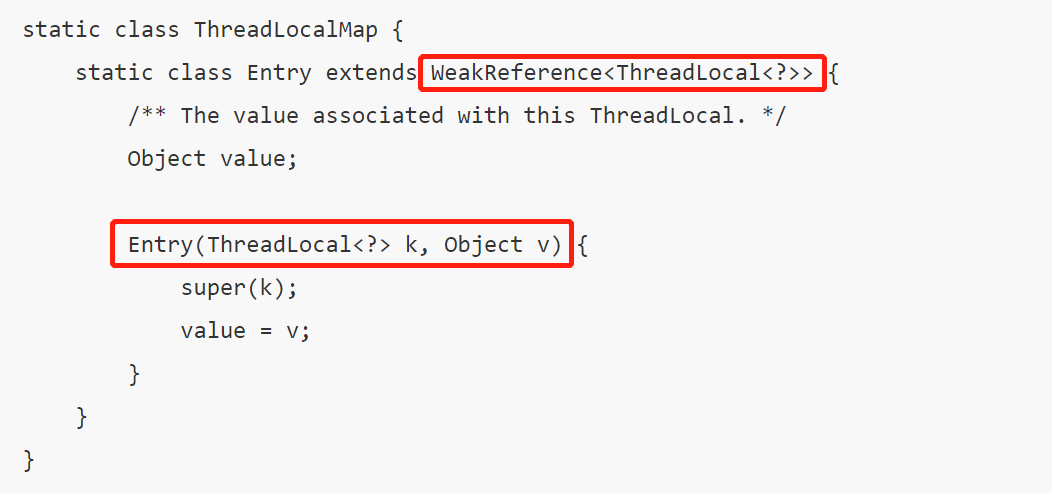
弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。
弱引用比较容易被回收。因此,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是因为ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
如何解决内存泄漏问题?使用完ThreadLocal后,及时调用remove()方法释放内存空间。
8、kafka是如何保证消息的有序性?
kafka这样保证消息有序性的:
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。(全局有序性)
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
大家可以看下消息队列的有序性是怎么推导的哈:
消息的有序性,就是指可以按照消息的发送顺序来消费。有些业务对消息的顺序是有要求的,比如先下单再付款,最后再完成订单,这样等。假设生产者先后产生了两条消息,分别是下单消息(M1),付款消息(M2),M1比M2先产生,如何保证M1比M2先被消费呢。
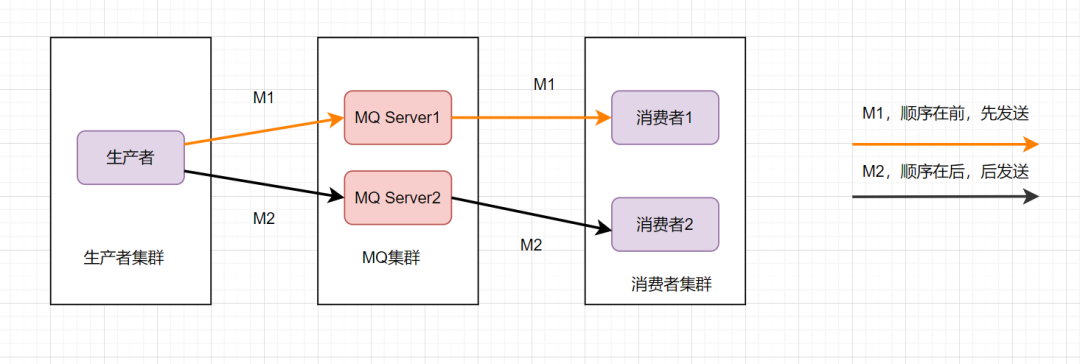
为了保证消息的顺序性,可以将将M1、M2发送到同一个Server上,当M1发送完收到ack后,M2再发送。如图:
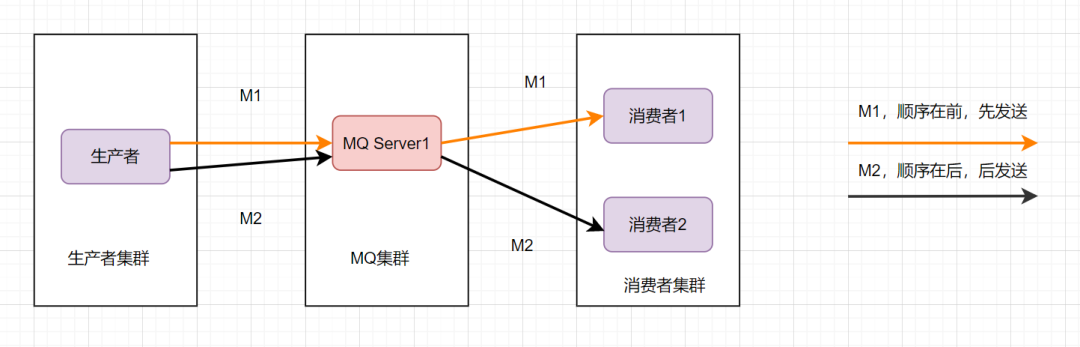
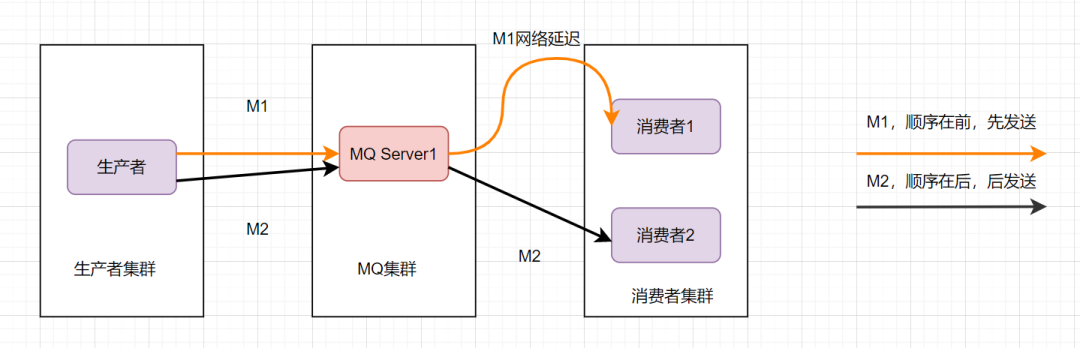
这样还是可能会有问题,因为从MQ服务器到服务端,可能存在网络延迟,虽然M1先发送,但是它比M2晚到。
那还能怎么办才能保证消息的顺序性呢?将M1和M2发往同一个消费者,且发送M1后,等到消费端ACK成功后,才发送M2就得了。
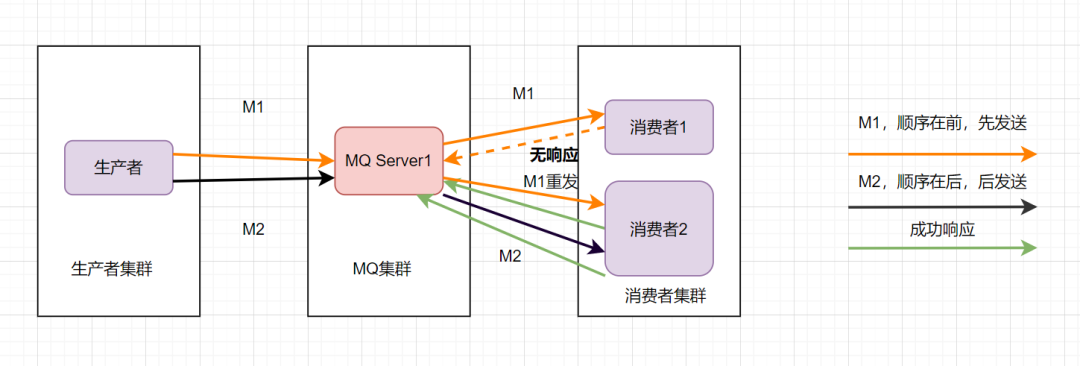
消息队列保证顺序性整体思路就是这样啦。比如Kafka的全局有序消息,就是这种思想的体现: 就是生产者发消息时,1个Topic只能对应1个Partition,一个 Consumer,内部单线程消费。
但是这样吞吐量太低,一般保证消息局部有序即可。在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。然后多消费者单线程消费指定的Partition。
9、Nacos的选举机制了解嘛?说下Raft算法?
Nacos作为配置中心的功能是基于Raft算法来实现的。
Raft 算法是分布式系统开发首选的共识算法,它通过“一切以领导者为准”的方式,实现一系列值的共识和各节点日志的一致。
Raft选举过程涉及三种角色和任期(Term):
- Follower:默默地接收和处理来自Leader的消息,当等待Leader心跳信息超时的时候,就主动站出来,推荐自己当Candidate。
- Candidate:向其他节点发送投票请求,通知其他节点来投票,如果赢得了大多数(N/2+1)选票,就晋升Leader。
- Leader:负责处理客户端请求,进行日志复制等操作,每一轮选举的目标就是选出一个领导者;领导者会不断地发送心跳信息,通知其他节点“我是领导者,我还活着,你们不要发起新的选举,不用找个新领导者来替代我。”
- Term:这跟民主社会的选举很像,每一届新的履职期称之为一届任期
领导选举过程
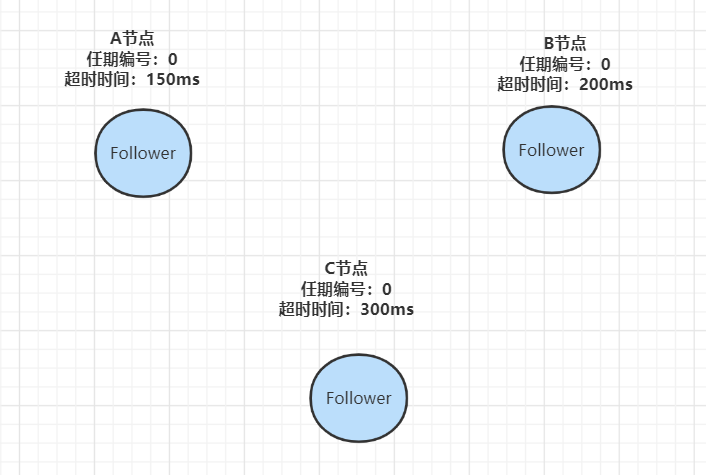
- 在初始时,集群中所有的节点都是Follower状态,都被设定一个随机选举超时时间(一般150ms-300ms):
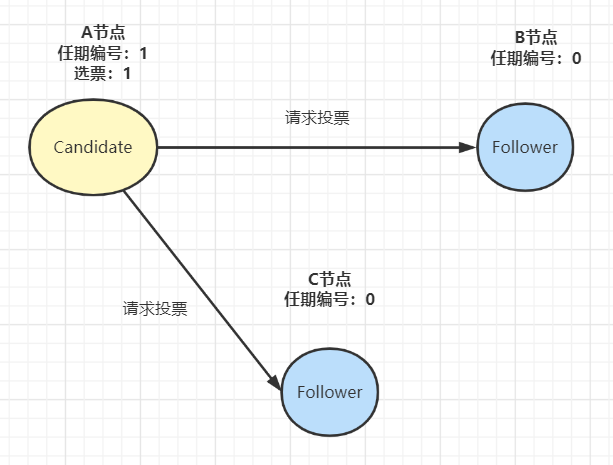
- 如果Follower在规定的超时时间,都没有收到来自Leader的心跳,它就发起选举:将自己的状态切为 Candidate,增加自己的任期编号,然后向集群中的其它Follower节点发送请求,询问其是否选举自己成为Leader:
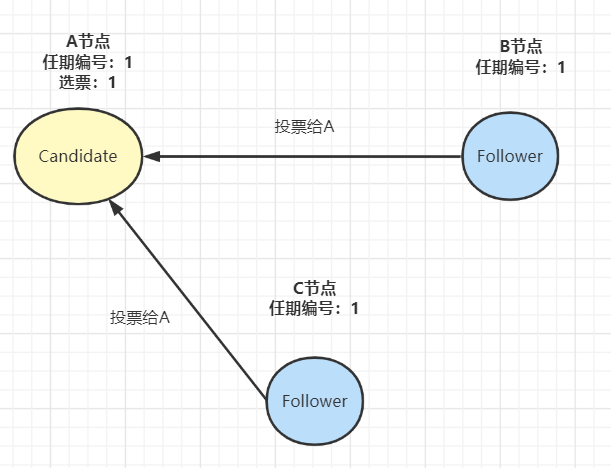
- 其他节点收到候选人A的请求投票消息后,如果在编号为1的这届任期内还没有进行过投票,那么它将把选票投给节点A,并增加自己的任期编号:
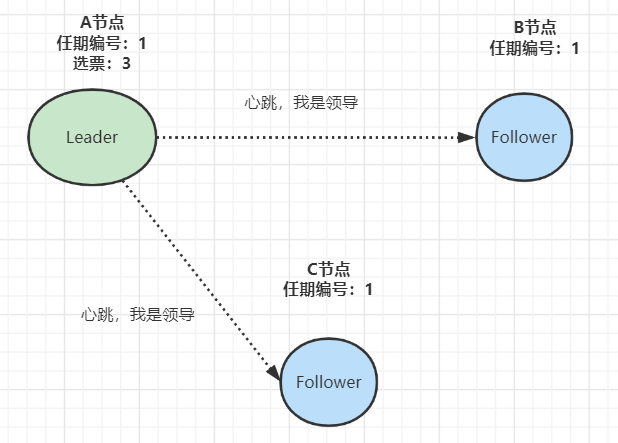
- 当收到来自集群中过半节点的接受投票后,A节点即成为本届任期内 Leader,他将周期性地发送心跳消息,通知其他节点我是Leader,阻止Follower发起新的选举:
10、聊一聊TCC补偿机制
TCC是分布式事务的一种解决方案。它采用了补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。TCC(Try-Confirm-Cancel)包括三段流程:
- try阶段:尝试去执行,完成所有业务的一致性检查,预留必须的业务资源。
- Confirm阶段:该阶段对业务进行确认提交,不做任何检查,因为try阶段已经检查过了,默认Confirm阶段是不会出错的。
- Cancel 阶段:若业务执行失败,则进入该阶段,它会释放try阶段占用的所有业务资源,并回滚Confirm阶段执行的所有操作。
下面再拿用户下单购买礼物作为例子来模拟TCC实现分布式事务的过程:
假设用户A余额为100金币,拥有的礼物为5朵。A花了10个金币,下订单,购买10朵玫瑰。余额、订单、礼物都在不同数据库。
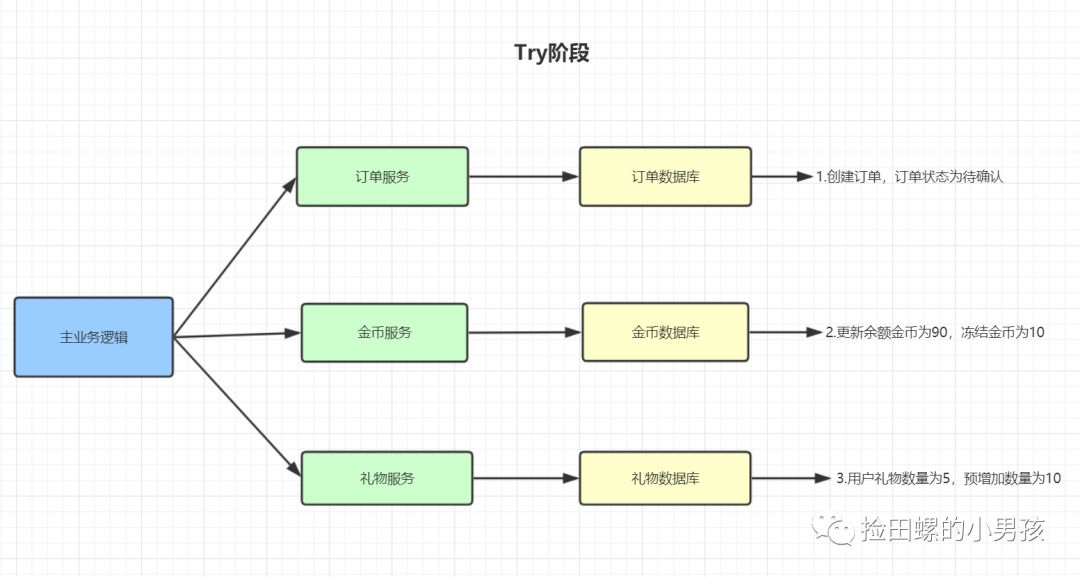
TCC的Try阶段:
- 生成一条订单记录,订单状态为待确认。
- 将用户A的账户金币中余额更新为90,冻结金币为10(预留业务资源)
- 将用户的礼物数量为5,预增加数量为10。
- Try成功之后,便进入Confirm阶段
- Try过程发生任何异常,均进入Cancel阶段
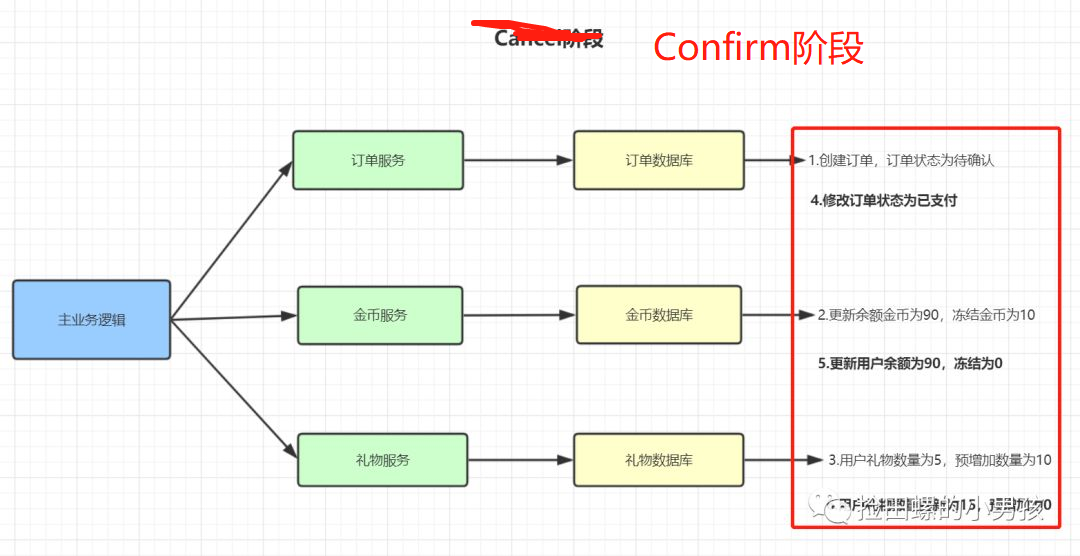
TCC的Confirm阶段:
- 订单状态更新为已支付
- 更新用户余额为90,可冻结为0
- 用户礼物数量更新为15,预增加为0
- Confirm过程发生任何异常,均进入Cancel阶段
- Confirm过程执行成功,则该事务结束
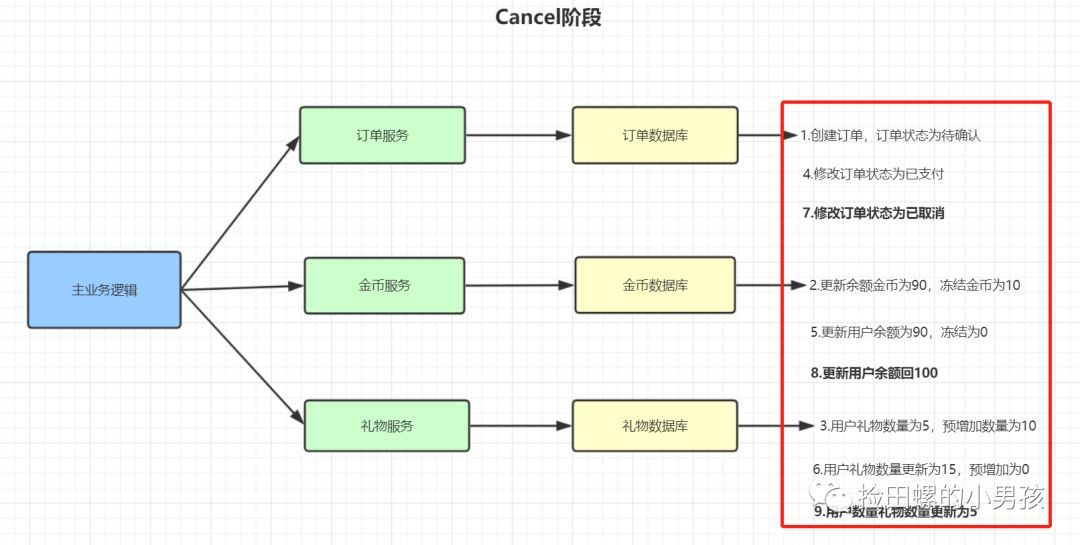
TCC的Cancel阶段:
- 修改订单状态为已取消
- 更新用户余额回100
- 更新用户礼物数量为5
- TCC的优点是可以自定义数据库操作的粒度,降低了锁冲突,可以提升性能
- TCC的缺点是应用侵入性强,需要根据网络、系统故障等不同失败原因实现不同的回滚策略,实现难度大,一般借助TCC开源框架,ByteTCC,TCC-transaction等。
审核编辑 :李倩
-
【硬件方向】名企面试笔试真题:大疆创新校园招聘笔试题2025-05-16 863
-
数字IC设计工程师笔试面试经典100题(大部分有答案)2012-08-20 75835
-
面试标准答案非万能2012-12-26 2879
-
硬件经典面试100题 (附答案)2018-10-12 11129
-
硬件经典面试100题(附参考答案)资料分享2019-02-25 3778
-
谁分享一份嵌入式软件工程师/单片机软件工程师面试试题&答案,THX!2021-10-25 4062
-
2006年下半年嵌入式系统设计师真题参考答案下载2010-03-01 543
-
南邮通信原理考研全部真题及答案(1998~2014年)-by 陈2016-01-13 4179
-
微软面试100题系列2017-01-08 553
-
电子科大《电路分析与电子线路》2018年考试真题及答案2018-06-05 10325
-
Linux面试3道题2018-09-23 746
-
网上流传的一份没有答案的Linux运维面试题详细分析2018-10-20 4177
-
Java架构面试笔试专题资料及经验(含答案)和学习笔记: ActiveMQ消息中间件面试专题.pdf2021-07-26 1282
-
分享一份很全的放大电路资料2022-12-19 916
全部0条评论

快来发表一下你的评论吧 !
