

如何改进和加速扩散模型采样的方法1
描述
这是一系列关于 NVIDIA 研究人员如何改进和加速扩散模型采样的方法的一部分,扩散模型是一种新颖而强大的生成模型。 Part 2 介绍了克服扩散模型中缓慢采样挑战的三种新技术。
生成模型是一类机器学习方法,它可以学习所训练数据的表示形式,并对数据本身进行建模。它们通常基于深层神经网络。相比之下,判别模型通常预测给定数据的单独数量。
生成模型允许您合成与真实数据不同但看起来同样真实的新数据。设计师可以在汽车图像上训练生成性模型,然后让生成性人工智能计算出具有不同外观的新颖汽车,从而加速艺术原型制作过程。
深度生成学习已成为机器学习领域的一个重要研究领域,并有许多相关应用。生成模型广泛用于图像合成和各种图像处理任务,如编辑、修复、着色、去模糊和超分辨率。
生成性模型有可能简化摄影师和数字艺术家的工作流程,并实现新水平的创造力。类似地,它们可能允许内容创建者高效地为游戏、动画电影或 metaverse 生成虚拟 3D 内容。
基于深度学习的语音和语言合成已经进入消费品领域。医学和医疗保健等领域也可能受益于生成性模型,例如生成对抗疾病的分子候选药物的方法。
当神经网络被用于不同的生成性学习任务时,尤其是对于不同的生成性学习任务,神经网络和神经网络也可以被用于合成。
生成性学习三位一体
为了在实际应用中得到广泛采用,生成模型在理想情况下应满足以下关键要求:
High-quality sampling :许多应用程序,尤其是那些直接与用户交互的应用程序,需要高生成质量。例如,在语音生成中,语音质量差是很难理解的。类似地,在图像建模中,期望的输出在视觉上与自然图像无法区分。
模式覆盖和样本多样性 :如果训练数据包含复杂或大量的多样性,一个好的生成模型应该在不牺牲生成质量的情况下成功捕获这种多样性。
快速且计算成本低廉的采样 :许多交互式应用程序需要快速生成,例如实时图像编辑。
虽然目前大多数深层生成性学习方法都注重高质量的生成,但第二和第三个要求也非常重要。
忠实地表示数据的多样性对于避免数据分布中遗漏少数模式至关重要。这有助于减少学习模型中不希望出现的偏差。
另一方面,在许多应用程序中,数据分布的长尾巴特别有趣。例如,在交通建模中,人们感兴趣的正是罕见的场景,即与危险驾驶或事故相对应的场景。
降低计算复杂度和采样时间不仅可以实现交互式实时应用。它还通过降低发电所需的总功率使用量,减少了运行昂贵的深层神经网络(发电模型的基础)所造成的环境足迹。
在本文中,我们将这三个需求带来的挑战定义为 生成性学习三位一体 ,因为现有方法通常会做出权衡,无法同时满足所有需求。
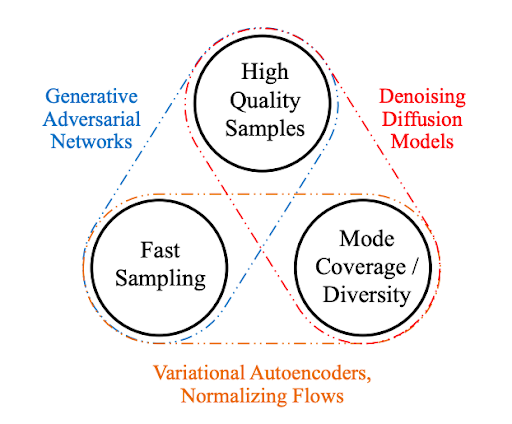
图 1 生成性学习三位一体
基于扩散模型的生成性学习
最近,扩散模型已经成为一种强大的生成性学习方法。这些模型,也被称为去噪扩散模型或基于分数的生成模型,表现出惊人的高样本质量,通常优于生成性对抗网络。它们还具有强大的模式覆盖和样本多样性。
扩散模型已经应用于各种生成任务,如图像、语音、三维形状和图形合成。
扩散模型包括两个过程:正向扩散和参数化反向扩散。
前向扩散过程通过逐渐扰动输入数据将数据映射为噪声。这是通过一个简单的随机过程正式实现的,该过程从数据样本开始,使用简单的高斯扩散核迭代生成噪声较大的样本。也就是说,在这个过程的每一步,高斯噪声都会逐渐添加到数据中。
第二个过程是一个参数化的反向过程,取消正向扩散并执行迭代去噪。这个过程代表数据合成,并经过训练,通过将随机噪声转换为真实数据来生成数据。它也被正式定义为一个随机过程,使用可训练的深度神经网络对输入图像进行迭代去噪。
正向和反向过程通常使用数千个步骤来逐步注入噪声,并在生成过程中进行去噪。

图 2 扩散模型处理数据和噪声之间的移动
图 2 显示,在扩散模型中,固定前向过程以逐步方式逐渐扰动数据,使其接近完全随机噪声。学习一个参数化的反向过程来执行迭代去噪,并从噪声中生成数据,如图像。
在形式上,通过x0表示一个数据点,例如图像,通过xt表示时间步长t的扩散版本,正向过程由以下公式定义:

虽然离散时间扩散模型和连续时间扩散模型看起来可能不同,但它们有一个几乎相同的生成过程。事实上,很容易证明离散时间扩散模型是连续时间模型的特殊离散化。
在实践中使用连续时间扩散模型基本上要容易得多:
它们更通用,可以通过简单的时间离散化转换为离散时间模型。
它们是用 SDE 描述的, SDE 在各个科学领域都得到了很好的研究。
生成性 SDE 可以使用现成的数值 SDE 解算器进行求解。
它们可以转换为相关的常微分方程( ODE ),这些方程也得到了很好的研究,并且易于使用。
如前所述,扩散模型通过遵循反向扩散过程生成样本,该过程将简单的基本分布(通常为高斯分布)映射到复杂的数据分布。在生成 SDE 表示的连续时间扩散模型中,由于神经网络逼近分数函数
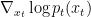
,这种映射通常很复杂。
用数值积分技术解决这个问题需要调用 1000 次深层神经网络来生成样本。正因为如此,扩散模型在生成样本时通常很慢,需要几分钟甚至几小时的计算时间。这与生成性对抗网络( GANs )等竞争性技术形成了鲜明对比,后者只需对神经网络进行一次调用即可生成样本。
总结
尽管扩散模型实现了较高的样本质量和多样性,但不幸的是,它们在采样速度方面存在不足。这限制了扩散模型在实际应用中的广泛采用,并导致了从这些模型加速采样的研究领域的活跃。在 Part 2 中,我们回顾了 NVIDIA 为克服扩散模型的主要局限性而开发的三种技术。
关于作者
Arash Vahdat 是 NVIDIA research 的首席研究科学家,专攻计算机视觉和机器学习。在加入 NVIDIA 之前,他是 D-Wave 系统公司的研究科学家,从事深度生成学习和弱监督学习。在 D-Wave 之前,阿拉什是西蒙·弗雷泽大学( Simon Fraser University , SFU )的一名研究人员,他领导了深度视频分析的研究,并教授大数据机器学习的研究生课程。阿拉什在格雷格·莫里( Greg Mori )的指导下获得了 SFU 的博士和理学硕士学位,致力于视觉分析的潜变量框架。他目前的研究领域包括深层生成学习、表征学习、高效神经网络和概率深层学习。
Karsten Kreis 是 NVIDIA 多伦多人工智能实验室的高级研究科学家。在加入 NVIDIA 之前,他在 D-Wave Systems 从事深度生成建模工作,并与他人共同创立了变分人工智能,这是一家利用生成模型进行药物发现的初创公司。卡斯滕在马克斯·普朗克光科学研究所获得量子信息理论理学硕士学位,并在马克斯·普朗克聚合物研究所获得计算和统计物理博士学位。目前,卡斯滕的研究重点是开发新的生成性学习方法,以及将深层生成模型应用于计算机视觉、图形和数字艺术等领域的问题。
审核编辑:郭婷
-
从扩散角度看电磁场2014-09-29 2999
-
已有频率与加速度功率谱密度的数据,怎么得到时域和加速度的关系图2015-08-19 20789
-
智能小车上的速度码盘和加速度传感器可以得到小车的运动轨迹吗2020-05-20 2790
-
气轨上测量滑块的速度和加速度2009-06-09 1305
-
基于改进的各向异性扩散的图像恢复2009-10-26 573
-
基于定向扩散路由协议的改进2010-09-14 629
-
基于改进灰色模型的ATS测试仪器校准周期确定2017-12-05 1105
-
如何改进和加速扩散模型采样的方法22022-05-07 4547
-
蒸馏无分类器指导扩散模型的方法2022-10-13 2291
-
Stable Diffusion采样速度翻倍!仅需10到25步的扩散模型采样算法2022-11-21 2595
-
基于扩散模型的图像生成过程2023-07-17 4609
-
如何加速生成2 PyTorch扩散模型2023-09-04 2205
-
扩散模型的理论基础2024-10-28 2581
-
浙大、微信提出精确反演采样器新范式,彻底解决扩散模型反演问题2024-11-27 1563
-
基于移动自回归的时序扩散预测模型2025-01-03 2111
全部0条评论

快来发表一下你的评论吧 !
