

X-CUBE-AI v7.1.0的三大更新内容
描述
X-CUBE-AI是STM32生态系统中的AI扩展包。可自动转换预训练的人工智能模型,并在用户项目中生成STM32优化库。
最新版的X-CUBE-AI v7.1.0在以下方面进行了三大更新:
支持入门级STM32 MCU
支持最新的AI训练框架
改善用户体验和性能调节。
我们通过提供更多用户友好的界面,不断增强STM32 AI生态系统的功能,并加强了神经网络计算中的更多操作。最重要的是,该扩展包由我们免费提供。
在介绍X-CUBE-AI v7.1.0的三大更新内容之前,我们先回顾一下X-CUBE-AI的主要用途。
什么是X-CUBE-AI扩展包
X-CUBE-AI扩展包,也称STM32Cube.AI,装配优化模块,确保从精度、内存占用和电源效率方面为目标STM32生成最佳拟合模型。
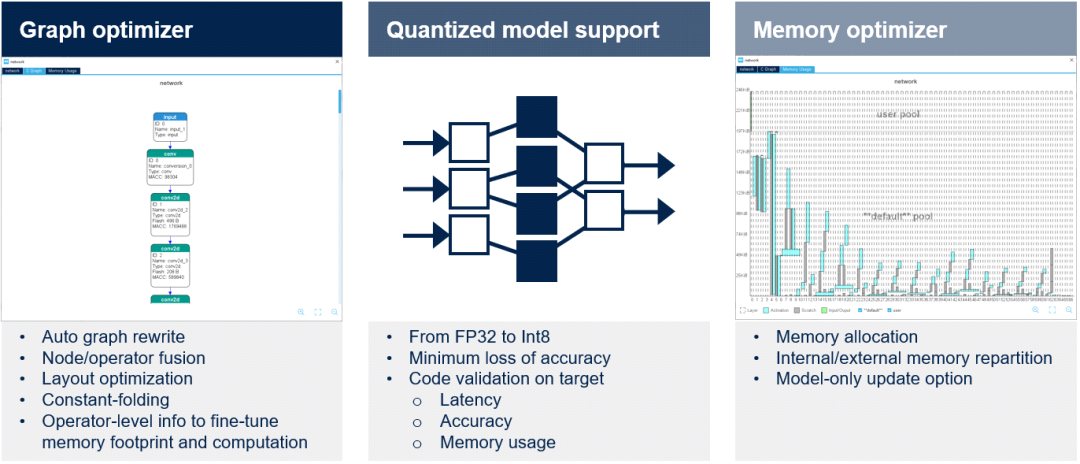
图形优化器通过有利于STM32目标硬件架构的图形简化和优化自动提高性能。使用了几种优化技术,如计算图重组、算子融合、常数折叠等。
量化器X-CUBE-AI扩展包支持FP32和Int8预训练模型。开发人员可以导入量化神经网络以兼容STM32嵌入式架构,同时通过采用文档中详述的训练后量化过程来保持性能。在下一个版本中,还将考虑Int1、Int2和Int3。成功导入模型后,可在桌面和目标STM32硬件上验证代码。
内存优化器内存优化器是一种高级内存管理工具。优化内存分配以获得最佳性能,同时符合嵌入式设计的要求。可在内部和外部资源之间实现内存分配的智能平衡,还可以为模型创建专用内存。开发人员可以轻松地更新模型。
X-CUBE-AI v7.1.0的三大更新
在最新版本的X-CUBE-AI v7.1.0中,我们进行了三大更新。
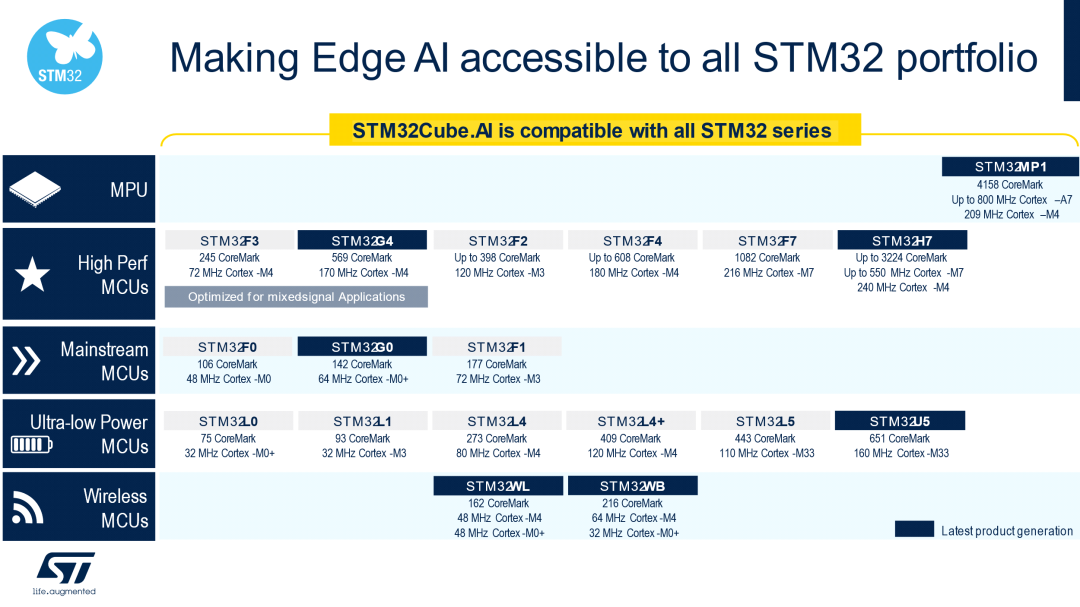
支持入门级STM32 MCU为了让您的边缘设备在各个层面都支持AI,我们使X-CUBE-AI v7.1.0实现了对STM32 Arm Cortex-M0和Arm Cortex-M0+的全面支持。从现在起,用户可以将神经网络带至最小的STM32微控制器上。
开发人员不仅可以在以下产品组合中找到用于各种用途的匹配芯片,还可以拥有一款具有AI启发性的芯片。STM32的频谱范围从超低功耗到高性能系列和微处理器,均包含在内。无线MCU等不同用途也适合AI应用。
支持最新的AI框架最新版本的X-CUBE-AI v7.1.0在Keras和TensorFlow等广泛使用的深度学习框架中添加了多种功能,并将TFLite runtime升级至2.7.0,将ONNX升级至1.9。
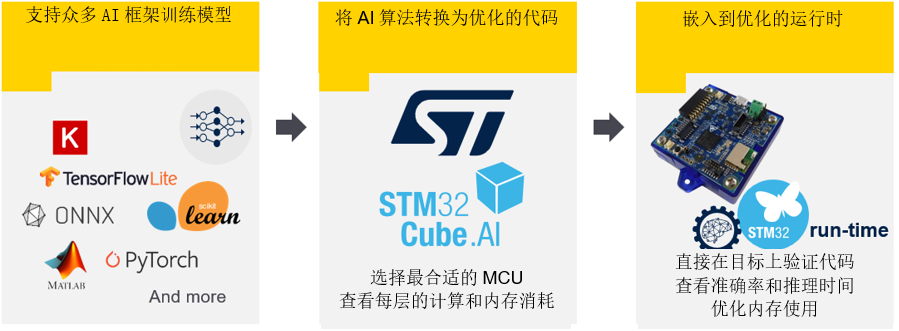
Keras通过Tensorflow得到支持,支持的算子允许处理针对移动或物联网资源受限的运行时环境的大量经典拓扑。例如,SqueezeNet、MobileNet V1或V2、Inception、SSD MobileNet V1等。在X-CUBE-AI v7.1.0中最高可支持TF Keras 2.7.0。
Tensorflow Lite是在移动平台上部署神经网络模型的格式。X-CUBE-AI导入并转换基于flatbuffer技术的tflite文件。处理多个算子,包括量化模型和量化感知训练或训练后量化过程生成的算子。
对于其他可以导出为ONNX标准格式的框架,如PyTorch、Microsoft Cognitive Toolkit、MATLAB等,X-CUBE-AI同样支持。
每个AI框架我们只支持所有可能层和层参数子集,这取决于网络C API的表达能力和特定工具箱的解析器。
我们提供STM32Cube.AI运行时,以便在执行AI应用程序时获得最佳性能。但是,开发人员可以选择TensorFlow Lite运行时作为一种替代方案,在多个项目中发挥作用。即使可能会降低性能,因为运行时针对STM32的优化程度较低。
除了深度学习框架外,X-CUBE-AI还涵盖了来自著名开源库scikit-learn的机器学习算法,这是一个完整的Python机器学习框架,如:随机森林、支持向量机(SVM)、k-means聚类和k最近邻(k-NN)。开发人员可以构建大量有监督或无监督的机器学习算法,并利用简单高效的工具进行数据分析。
X-CUBE-AI v7.1.0不直接支持来自scikit-learn框架或XGBoost包的机器学习算法。在完成训练步骤后,这些算法应转换为ONNX格式,以便部署和导入。skl2onnx实用程序通常用于将模型转换为ONNX格式。可以使用带有ONNX导出器的其他ML框架,但请注意,X-CUBE-AI中ONNX-ML模型的导入主要使用 scikit-learn v0.23.1、skl2onnx v1.10.3和XGBoost v1.5.1进行测试。
改善用户体验和性能调节X-CUBE-AI v7.1.0引入了多堆支持,开发人员只需单击即可轻松地将不同内容分配到碎片化的内存段上。
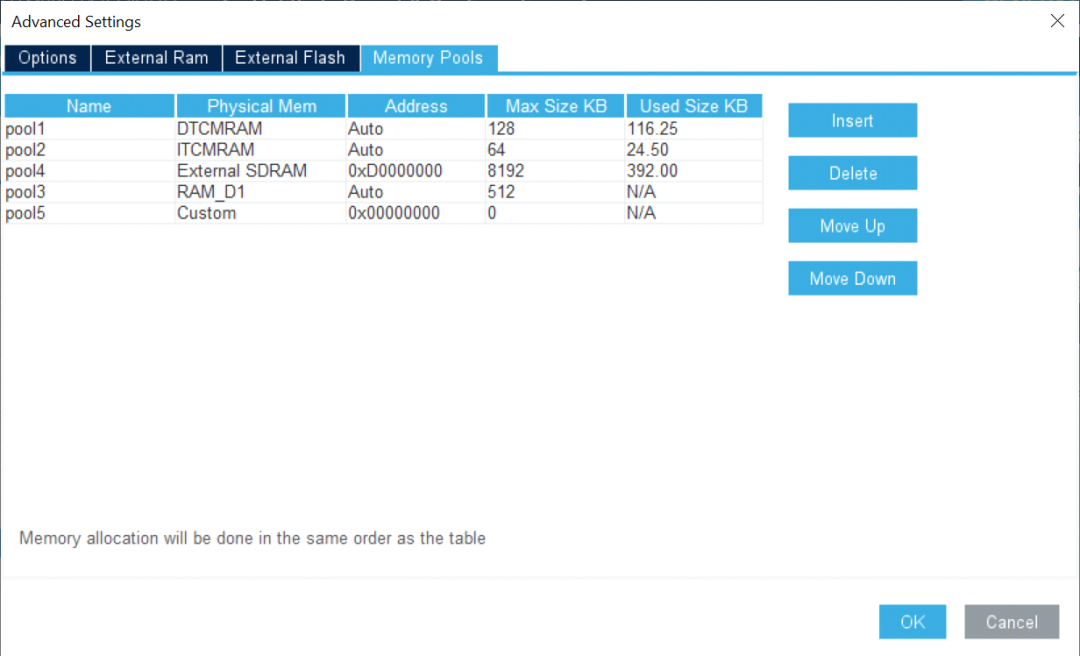
通过使用外部内存支持,开发人员可以轻松地在不同的内存区域分配权重。一旦模型存储在多个数组中,便可将部分权重映射到内部闪存,而其余的则映射到外部闪存。该工具使开发人员可以根据模型要求和应用程序内存占用使用非连续闪存区。
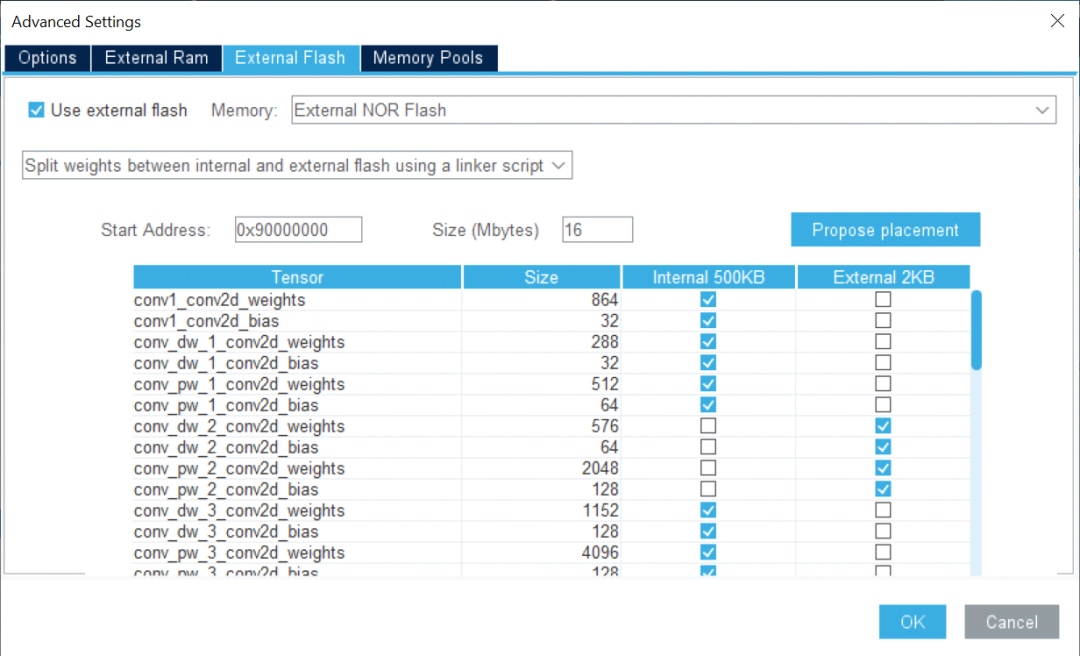
图形用户界面还提供了生成代码中使用的缓冲区的全面视图。一旦选择了模型,开发人员就可以通过直观地检查统计数据来评估整体复杂性和内存占用。模型中的每一层都清晰可见,开发人员可以轻松识别关键层。
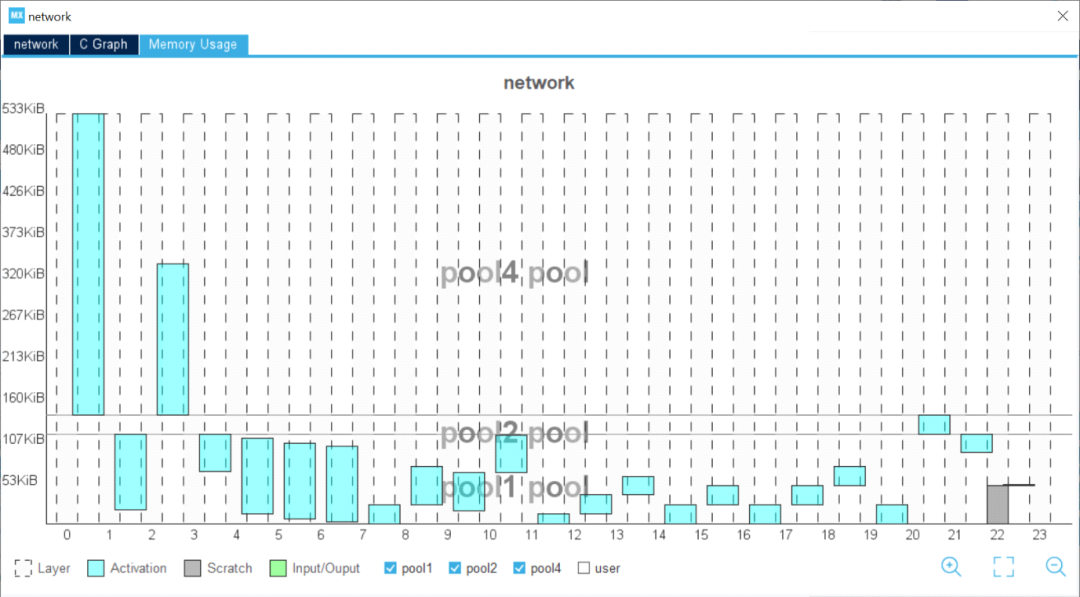
该工具可帮助开发人员加快速度,使我们能够在桌面上验证模型,进行快速基准测试并检测目标STM32设备的最终性能。
验证过程结束时,对比表总结了原始模型和STM32模型之间的准确性和误差。X-CUBE-AI还提供了每层的计算复杂度报告,以及运行时测量的推断时间。
X-CUBE-AI只是意法半导体为STM32用户利用人工智能提供的广泛生态系统的一部分。使用X-CUBE-AI可确保高质量开发的长期支持和可靠性。每次推出新的主要版本时,都会有针对性地定期更新,确保兼容最新AI框架。敬请关注我们为您带来的更多有趣技术。
我们将策划一系列AI主题文章,详细介绍意法半导体在Deep Edge AI领域的努力成果。
本文是该系列文章中的第十一篇,点击上方的话题,订阅我们的AI技术专题系列 。
欢迎您在文后积极留言,告诉我们想了解意法半导体AI的哪些方面,我们将为您呈现更多精彩内容。
原文标题:AI技术专题之十一:更简便、更智能的X-CUBE-AI v7.1.0,让您轻松部署AI模型
文章出处:【微信公众号:意法半导体中国】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
扩展包x-cube-ai能实现SVM支持向量机吗?2024-03-22 658
-
cube AI导入Keras模型出错怎么解决?2024-03-18 821
-
人工智能(AI)X-CUBE-AI扩展包入门指南2023-08-01 876
-
linux上的X-CUBE-AI扩展包中缺少stm32ai应用程序怎么解决?2023-01-09 745
-
X-CUBE-AI配置中缺少平台设置选项卡要怎么处理?2023-01-05 685
-
在X-CUBE-AI.7.1.0中导入由在线AI平台生成的.h5模型报错怎么解决?2022-12-27 770
-
X-CUBE-AI 7.1.0生成代码初始化错误如何解决呢?2022-12-26 904
-
X-CUBE-AI和NanoEdge AI Studio在ML和AI开发环境中的区别是什么?2022-12-05 1174
-
请问一下X-CUBE-AI中的aiValidation是如何运行的?2022-11-30 450
-
X-CUBE-AI STM32Cube扩展包精选资料推荐2022-11-29 947
-
怎么去解决cube ai部署后报错的问题呢2022-11-01 1877
-
轻松实现一键部署AI模型至RT-Thread系统2022-09-02 2012
-
使用STM32CubeMX和X-CUBE-AI生成代码2021-11-01 2050
-
Eagle下载_Eagle v7.1.0免费中文版2019-04-15 8400
全部0条评论

快来发表一下你的评论吧 !
