

跨图像关系型KD方法语义分割任务-CIRKD
描述
语义分割任务作为计算机视觉中的基础任务之一,其目的是对图像中的每一个像素进行分类。该任务也被广泛应用于实践,例如自动驾驶和医学图像分割。现有流行的用于语义分割任务的模型,例如DeepLab和PSPNet系列,虽然获得了很好的分割精度,但是所需的算力成本较高。本文考虑使用知识蒸馏(Knowledge Distillation,KD)算法来缓解这个问题。KD作为模型压缩里的一项重要技术,其核心思想是将教师模型中学习的知识作为监督信号来训练学生模型,使得学生模型得到更好的性能。虽然现有的语义分割知识蒸馏方法能够对学生网络的性能进行提升,但是这些方法通常是从单张图像中提取知识,忽略了跨图像之间的关系信息也是一种有价值的知识。
最近,地平线-中科院提出了一种新颖的跨图像关系型KD方法用于语义分割任务-CIRKD。该方法尝试在语义分割任务中建模pixel-to-pixel和pixel-to-region这两种对比关系作为KD的监督信号。本文主要从方法介绍以及实验结果对提出的CIRKD进行讲解。
KD作为一种思想已被广泛应用,尤其是图像分类任务。但是先前的工作表明直接将图像分类KD方法直接迁移到语义分割任务是不可行的,因为它们没有考虑到语义分割的结构化信息。一些经典的语义分割KD工作于是去尝试捕捉到一些上下文信息来建模结构化知识,比如pixel相似度,pixel与region向量的相似度关系,但是这些方法通常在单张图像内部进行信息提取,难以捕捉到更加广泛的上下文依赖。
于是,我们提出一种跨图像的知识蒸馏方法来建模图像间的依赖,从而使得网络能够捕捉到更加丰富的结构化信息。具体地,本工作建模数据集中的全部图像之间建模pixel-to-pixel以及pixel-to-region的对比关系作为知识。动机在于一个好的教师模型可以产生更好的全局pixel依赖以及特征空间。CIRKD引导学生模型去模仿教师网络产生的更好的结构化语义关系,因此提升了语义分割表现。
具体方法
本方法分别从mini-batch和memory的角度对结构化关系进行建模。
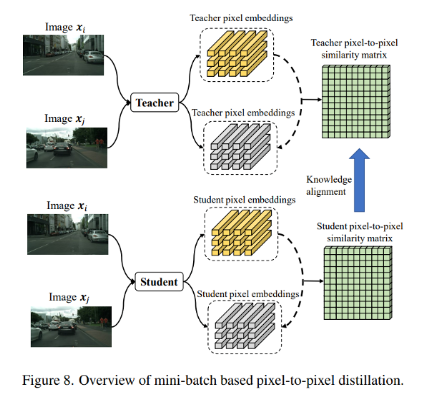
1. 基于mini-batch的pixel-to-pixel蒸馏
首先是在batch中建模关系,将图像产生的特征图在spatial维度上进行分离,产生pixel-wise的特征向量。针对某一个pixel点的特征向量作为锚样本,其他pixel点特征向量(包括当前图像和其他图像)作为对比样本,可以得到相似度矩阵。基于此方法,在教师端和学生端都可以产生对应的相似度矩阵,然后通过KL散度进行逼近,使得学生可以学到教师的相似度矩阵:
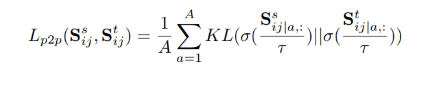
一个batch内的图像进行两两之间的关系矩阵求取和迁移:
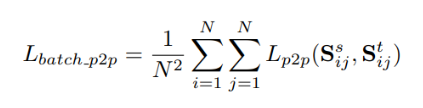
整个过程的示意图如下所示:
2. 基于memory的pixel-to-pixel蒸馏
相对于基于mini-batch的对比性关系求取,这里采用一个memory bank来存储对比向量,使得每一个锚样本都可以得到充足的对比样本。针对某一个pixel点的特征向量作为锚样本,每次训练随机从memory bank中采样大量的pixel特征向量来构造对比样本,通过相乘分别得到教师和学生的相似度矩阵:
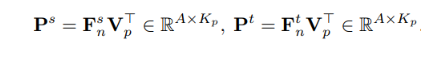
使用KL散度的误差形式将教师和学生的pixel-to-pixel相似度矩阵进行对齐:
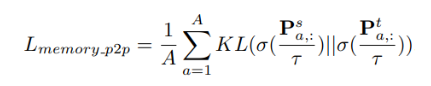
3. 基于memory的pixel-to-region蒸馏
离散化的pixel特征向量不能充分在捕捉到图像内容,因此本方法利用memory对region向量进行存储。region向量产生自对来自相同类别的pixel向量做一个平均。针对某一个pixel点的特征向量作为锚样本,每次训练随机从memory bank中采样大量的region特征向量来构造对比样本,通过相乘分别得到教师和学生的相似度矩阵:
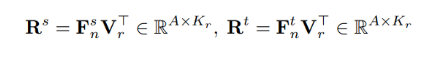
使用KL散度的误差形式将教师和学生的pixel-to-region相似度矩阵进行对齐:
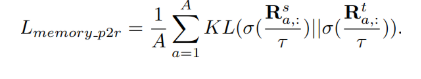
基于memory进行KD的整体示意图如下所示:
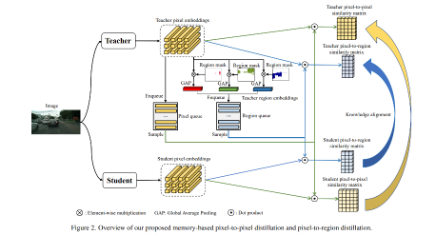
最终的训练误差则是将以上3部分误差相加在一起:
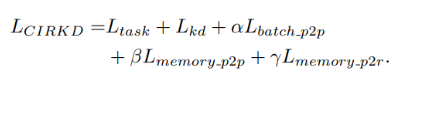
实验结果
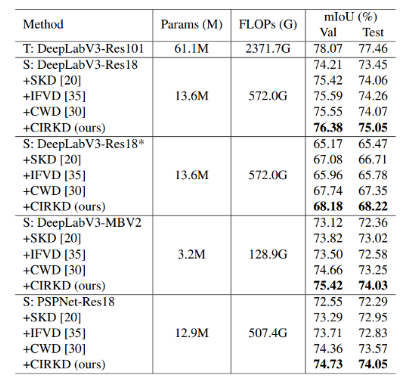
实验在流行的Cityscapes场景分割数据集上进行,相比于其他流行的语义分割KD方法,CIRKD获得了一致最佳的表现。
在一些case study上进行可视化,本方法能够得到最好的分割表现。
审核编辑:彭静
-
图像分割和语义分割的区别与联系2024-07-17 3099
-
图像分割与语义分割中的CNN模型综述2024-07-09 3459
-
深度学习图像语义分割指标介绍2023-10-09 1050
-
PyTorch教程-14.9. 语义分割和数据集2023-06-05 1537
-
语义分割标注:从认知到实践2023-04-30 2041
-
图像语义分割的概念与原理以及常用的方法2023-04-20 7302
-
基于SEGNET模型的图像语义分割方法2021-05-27 944
-
基于深度神经网络的图像语义分割方法2021-04-02 1650
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1466
-
语义分割算法系统介绍2020-11-05 7997
-
目标检测和图像语义分割领域性能评价指标2020-05-13 2114
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1034
-
基于内容的图像分割方法综述2018-01-02 1301
全部0条评论

快来发表一下你的评论吧 !
