

基于k近邻与高斯噪声的虚拟困难样本增强方法
描述
在本文中,我们将介绍亚马逊团队在ACL2022中的一篇论文VaSCL,该论文在SimCSE的基础上,提出了一种基于k近邻与高斯噪声的虚拟困难样本增强方法。作者在无监督训练中,进行困难样本增强,从而提高了模型的性能,并且超过了SimCSE。

论文标题:
Virtual Augmentation Supported Contrastive Learning of Sentence Representations
论文链接:
https://arxiv.org/abs/2110.08552
01
引言
在ACL2021中,陈丹琦团队提出了使用Dropout进行正样本增强的对比学习方法SimCSE,该方法操作简单却十分有效,在无监督对比学习中取得了非常好的效果。在有监督SimCSE中,作者对困难负样本的作用进行了探究实验,实验结果证明,引入困难负样本后,有监督SimCSE的指标从84.9提升至86.2。这说明,在对比学习中,引入困难样本是能够提升模型效果的。
然而在无监督SimCSE中,作者仅使用dropout的方式进行了正样本增强,没有额外引入困难样本,这在一定程度上限制了模型的能力。基于这个动机,亚马逊提出了一种基于k近邻与高斯噪声的虚拟困难样本增强的无监督对比学习方法VaSCL。
02
论文解读
基于Dropout的对比损失
在介绍VaSCL模型之前,我们先简单回顾一下无监督SimCSE。假设训练时的batch size为N,将一个batch的数据记作 ,将同一个样本 分别输入模型中两次,使用不同的dropout mask编码得到两个向量 和 。则在规模为N的batch中, 与 的InfoNCE损失为:
基于k近邻的虚拟增强对比损失
在无监督SimCSE的损失函数的基础上,作者还设计了一种基于k近邻的虚拟困难样本增强的损失函数。
将 通过模型编码之后得到向量序列 。
作者通过以下方式获得第i个句向量 的虚拟困难样本:
正样本增强:对 添加高斯噪声 ,得到 ,其中 就是经过高斯增强后的正样本。
获得k近邻:获得 在 中距离最近的k个负样本,在本文中我们称之为k近邻,记作 。
对于 来说, 是正样本, 是负样本集合。则对于 ,k近邻虚拟增强的对比损失如下。分子表示拉近 与 的距离,分母表示拉远 与负样本之间的距离。
在CV中,我们会为输入的图片添加高斯噪声以增加模型的泛化性。添加了高斯噪声的图片,肉眼能看出微小的区别,但不会影响整张图片的语义信息。所以为句向量添加合适的高斯噪声,理论上也不会对句向量的语义信息产生很大的改变。
在 的k近邻 中,存放的是距离 最近的k个负样本,也就是与 最相似的k个负样本。只要batch size足够大,我们可以近似认为, 就是 的困难负样本集合,同样也是 的困难负样本集合。
如何获得上述的高斯噪声 呢?最容易想到的做法便是随机生成一个高斯噪声,直接添加到句向量中。但是为了提高模型的训练难度,生成更高质量的高斯噪声,作者生成若干个候选高斯噪声,然后选出一个使得 最大化的高斯噪声。
从上述操作可以看出,对于最优的高斯噪声 ,作者希望它增强后的正样本 与 的距离尽可能远,与负样本 的距离尽可能近,作者希望这个高斯噪声能够对模型产生尽可能大的迷惑性。通过这个高斯噪声,我们就可以得到困难正样本,并且从某种意义来说,也使得 与 的距离尽可能拉近,达到了增强负样本难度的目的,做法确实挺巧妙。
VaSCL对比损失
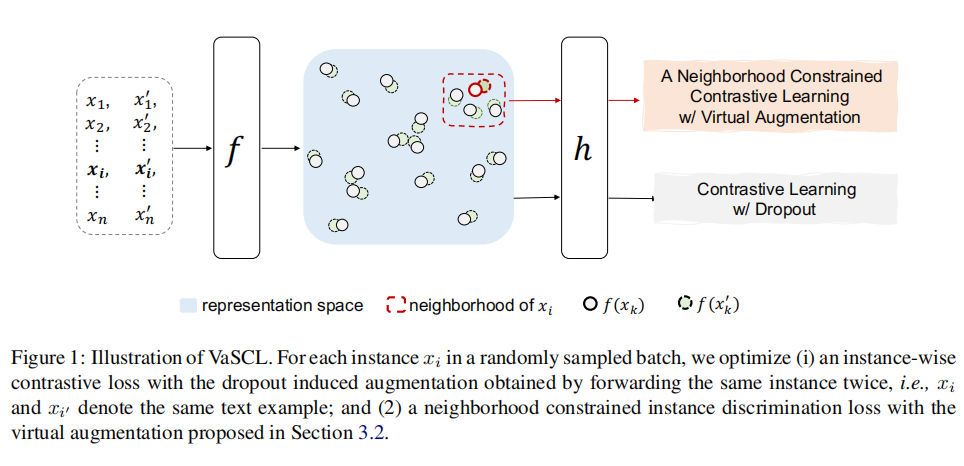
将上述两种对比损失进行组合,得到最终的VaSCL损失函数:
这个损失函数的含义如下:
对于每个句子,拉近同一个句子经过dropout之后的两个句向量之间的距离,拉远它们与其他句子的距离。
对于每个句子,拉近原句向量与高斯噪声增强之后的句向量的距离,拉远它们与k近邻负样本之间的距离。
03
实验结果
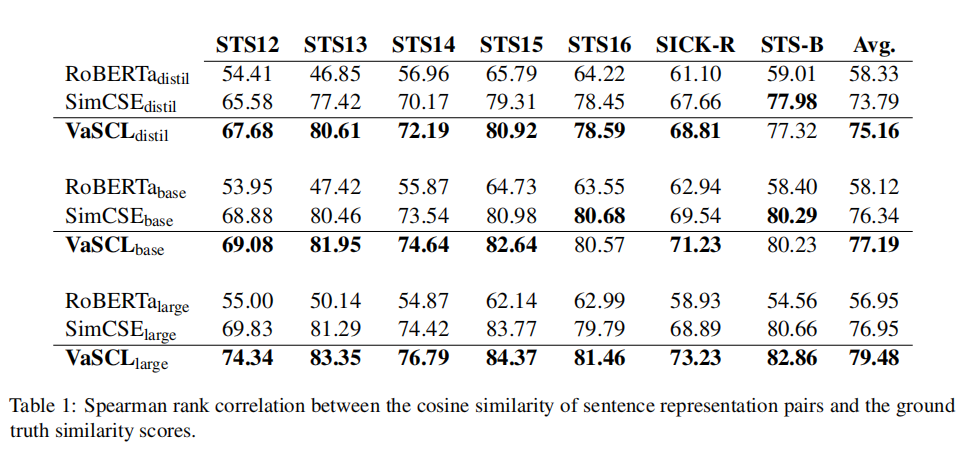
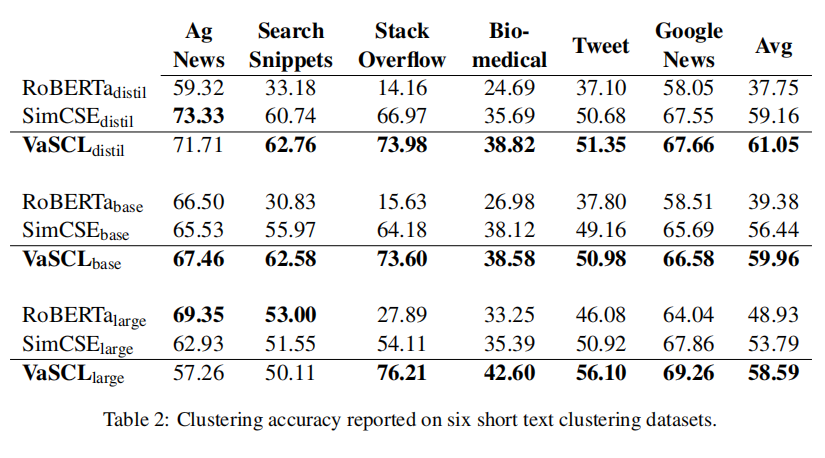
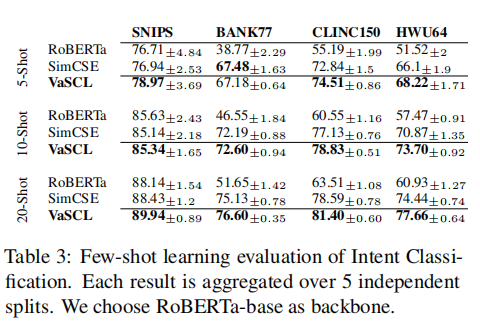
作者分别在STS任务、短文本聚类、意图识别等任务中进行了实验,实验结果如下表所示。可以看到,在三种任务中,绝大部分数据集上,VaSCL的表现都要优于SimCSE,这表明了基于k近邻与高斯噪声的困难样本增强的有效性。
04
总结
SimCSE通过dropout mask这种简单的方法,避免了人工进行正样本增强所带来的语义改变的问题,并且在无监督训练中取得了不错的效果。而VaSCL论文延续了SimCSE这种思想,引入了高斯噪声进行正样本增强,有着异曲同工之妙。
VaSCL在SimCSE的基础上,也进行了困难样本的增强。在进行高斯噪声增强时,使得增强的样本与原始样本尽可能不相似,与负样本尽可能相似,已达到【混淆视听】的效果。通过这种方式,VaSCL在绝大多数据集上的表现,也超过了SimCSE。
审核编辑 :李倩
-
噪声样本标签重标注方法综述2021-05-28 1026
-
面向K近邻分类性能的遗传训练集优化算法2021-05-13 1104
-
基于k近邻的完全随机森林算法KCRForest2021-04-02 1219
-
椒盐噪声高斯噪声2020-05-27 1918
-
机器学习之 k-近邻算法(k-NN)2020-05-15 2314
-
基于判别核主元空间k近邻的批次过程监视2019-01-22 1440
-
如何使用局部近邻标准化和动态主元分析进行故障检测分析策略2018-12-28 1703
-
如何面向K最近邻分类的遗传实例来选择算法2018-11-16 1227
-
Python实现k-近邻算法2018-10-10 3443
-
人工智能机器学习之K近邻算法(KNN)2018-05-29 3574
-
无参数近邻保持及最大化非近邻算法2018-01-05 627
-
基于k近邻推荐方法2017-11-28 686
-
基于K近邻特征选择算法的对比分析2017-11-06 733
-
高斯随机噪声实时生成实现方法研究2006-03-24 3037
全部0条评论

快来发表一下你的评论吧 !
