

如何让HSPICE仿真效率提升42倍?
描述
作为最早的电子设计自动化软件,我们的EDA云实证系列从SPICE开始,再合适不过。
在它出现之前,人们分析电路,用的是纸笔或者搭电路板。随着电路规模增大,手工明显跟不上。
于是,1971年,SPICE诞生了。全称“Simulation Program with Integrates Circuit Emphasis"。
H-SPICE是随着产业环境及电路设计技术的发展与升级,以“SPICE2”为基础加以改进而成的商业软件产品,现在属于Synopsys。
既然有了新的计算机辅助工具,那问题就来了:
怎么才能跑得更快一点?
怎么才能运行更大规模的集成电路?
第一个答案是算法改进。这属于数学领域,很难。
第二个答案是摩尔定律。从上世纪70年代初到如今,SPICE从只能仿真十几个元器件到今天可以仿真上千万个元器件的电路。但已经几十年没有太大的变化了。
第三个答案是计算架构升级,从单核到多核,单线程到多线程。
第四个答案是Cloud HPC云端高性能计算。谈概念过于抽象,我们今天拿实证说话。
实证背景信息
用户需求
作为一家纯IC设计公司,C社成立已超过十年。
公司在本地部署了由十多台机器组成的计算集群,但目前面临的最大问题依然是算力不足。特别是面对每年十次左右的算力高峰期时,基本上没有太好的办法。
对云的认知
C社相关负责人表示:算力不足是目前IC设计行业普遍面临的问题。对于EDA上云,公司之前没有尝试过,对云模式和架构也并不了解,在数据安全性方面也存在一定的顾虑。
不过该负责人对于EDA上云早有耳闻,也颇感兴趣,愿意进行一定的尝试。毕竟上云若真的能够加快运算速度,就意味着可以更早展开研究,从而提升项目的整体进度。
实证目标
1、HSPICE任务能否在云端运行?
2、云端资源是否能适配HSPICE任务需求?
3、fastone平台能否有效解决目前业务问题?
4、相比传统手动模式,云端计算集群的自动化部署,有哪些好处?
实证参数
平台:
fastone企业版产品
应用:
HSPICE
适用场景:
仿真模拟电路、混合信号电路、精确数字电路、建立SoC的时序及功耗单元库、分析系统级的信号完整性等
技术架构图:
用户登录VDI,使用fastone算力运营平台根据实际计算需求自动创建、销毁集群,完成计算任务。
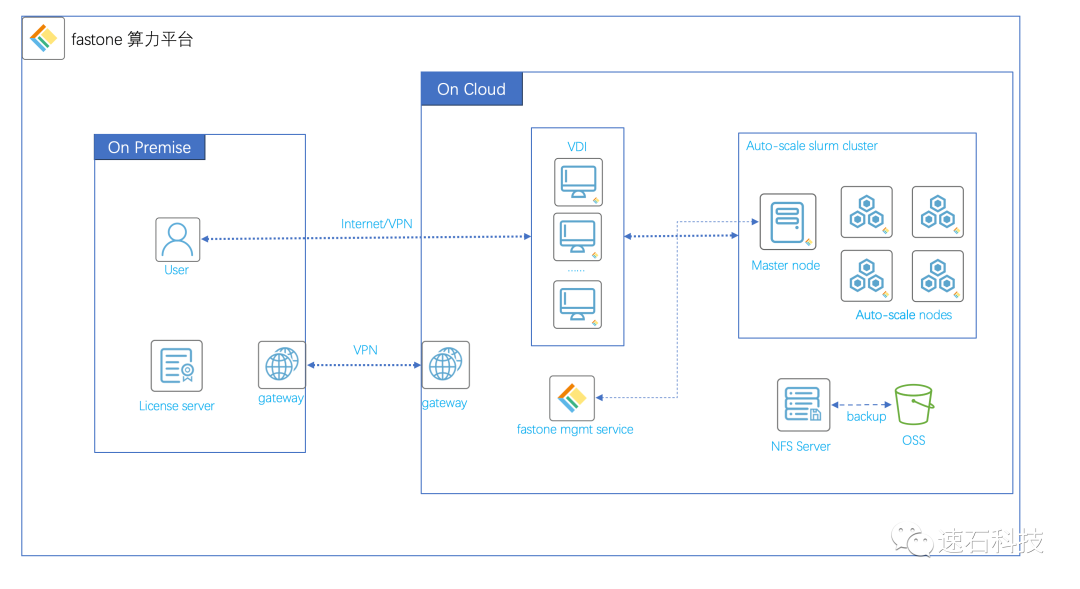
License配置:
EDA License Server设置在本地。
步骤一:硬件选择
选择适合HSPICE应用的配置
云端可以选择的机型有几百种,配置、价格差异极大。
我们首先需要挑选出既能满足HSPICE应用需求,又具备性价比的机型。
已知用户的本地硬件配置:
Xeon(R) Gold 6244 CPU @ 3.60GHz,512GB Memory
本地配置不仅主频高,内存也相当大。
我们推荐的云端硬件配置:
96 vCPU, 3.6GHz, 2nd Gen Intel Xeon Platinum 8275CL, 192 GiB Memory
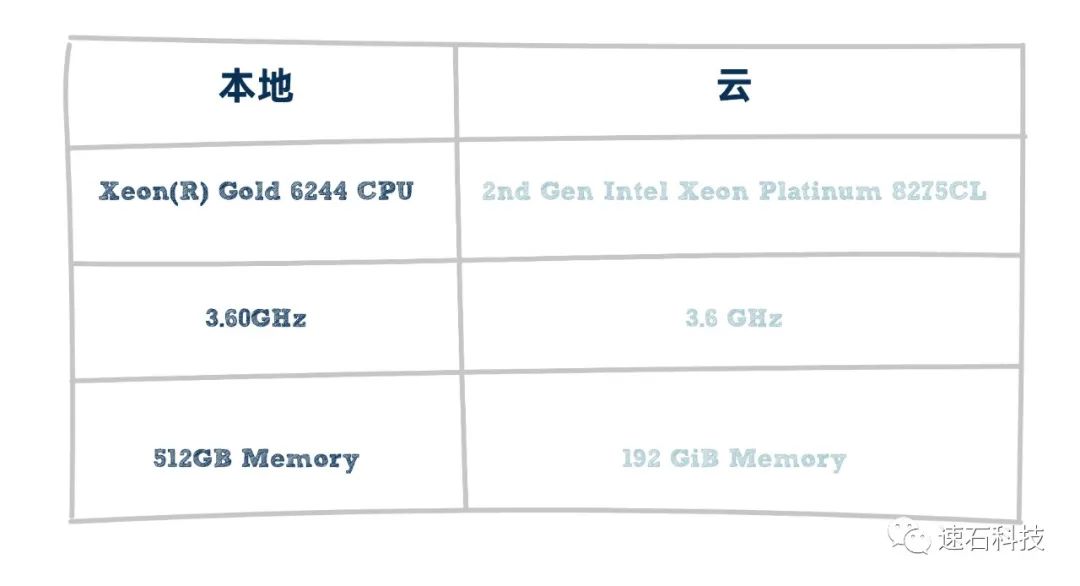
推荐理由:
1、该应用对CPU主频要求较高,但内存要求并不大;
2、我们选择了计算优化型云端实例,即具备高性价比的高主频机器。
C社的本地硬件在HSPICE以外,还需处理一些需要大内存的后端任务,所以需要在配置上兼顾各种资源需求,在当前项目不可避免会造成一定的资源浪费。
步骤二:云端部署
手动模式 VS 自动部署
我们先看手动模式:
第一步:不管你需要用哪朵云,你都得先熟悉那家云的操作界面,掌握正确的使用方法;
第二步:构建大规模算力集群:
配置计算节点,存储节点,VPC,安全组等等
安装应用,把HSPICE安装在集群环境
配置集群调度器,比如slurm
第三步:上传任务数据,开启计算;
第四步:任务完成后及时下载结果并关机。
不要笑,这一点很重要。我们在切换七种视角,我们给各位CXO大佬算算上云这笔账有讲到原因。
此外,还有一个需要考虑的点,时间。
第一步,需要多少时间说不好;
第二步,大概需要专业IT人员平均3-5天;
第三步/第四步,如果数据量较大,需要考虑断点续传和自动重传;
第四步,任务完成时间很可能难以预测。
即使是可测的,我们可以想象一个场景——有个任务预计在凌晨跑完,用户此时有两个选择:
1、调一个闹钟,半夜起来关机——有人遭罪;
2、睡到自然醒,次日上班关机——成本浪费。

在手动模式下,通常都是先构建一个固定规模的集群,然后提交任务,全部任务结束后,关闭集群。
想一下一个几千core的集群拉起来之后,第二、三、四步手动配置的时间里,所有机器一直都是开启状态,也就是说,烧钱中。
再看看我们的自动化部署:
第一步,不需要;
第二步,只需要点击几个按钮,5-10分钟即可开启集群;
第三步,我们有Auto-Scale功能,自动开关机。
另外,我们还自带资源的管理和监控功能。
fastone的Auto-Scale功能可以自动监控用户提交的任务数量和资源的需求,动态按需地开启所需算力资源,在提升效率的同时有效降低成本。
所有操作都是自动化完成,无需用户干预;
在实际开机过程中,可能遇到云在某个可用区资源不足的情况,fastone会自动尝试从别的区域开启资源;
如果需要的资源确实不够,又急需算力完成任务,用户还可以从fastone界面选择配置接近的实例类型来补充。
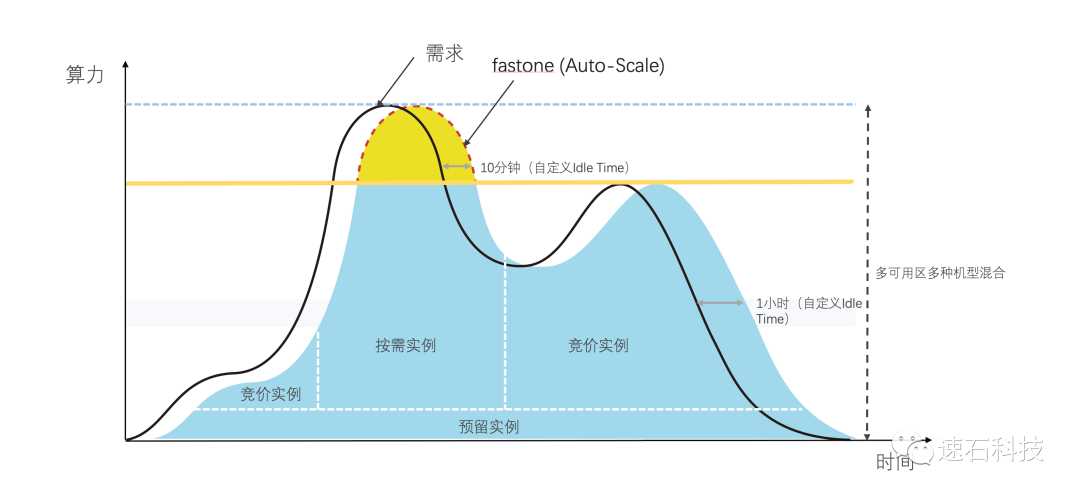
跨区域,跨机型使用,在本次实证场景没有用到。
我们还可以根据GPU的需求来实现自动伸缩,下次单独聊。
实证场景一:云端验证
本地40核 VS 云端40核 VS 云端80核
结论:
1、当计算资源与任务拆分方式均为5*8核时,本地和云端的计算周期基本一致;
2、在云端将任务拆分为10*4核后,比5*8核的拆分方式计算周期减少三分之一;
3、当任务拆分方式不变,计算资源从40核增加到80核,计算周期减半;
4、当计算资源翻倍,且任务拆分方式从5*8核变更为10*4核后,计算周期减少三分之二;
5、fastone自动化部署可大幅节省用户的时间和人力成本。
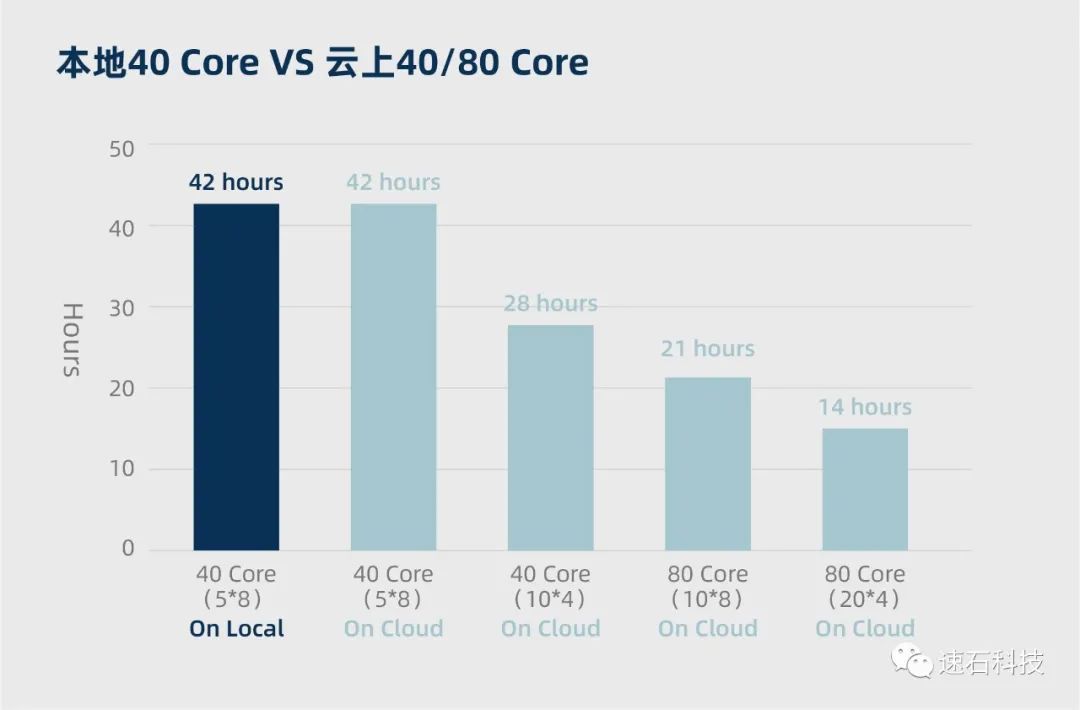
实证过程:
1、本地使用40核计算资源,拆分为5*8核,运行编号为1的HSPICE任务,耗时42小时;
2、云端调度40核计算资源,拆分为5*8核,运行编号为1的HSPICE任务,耗时42小时;
3、云端调度40核计算资源,拆分为10*4核,运行编号为1的HSPICE任务,耗时28小时;
4、云端调度80核计算资源,拆分为10*8核,运行编号为1的HSPICE任务,耗时21小时;
5、云端调度80核计算资源,拆分为20*4核,运行编号为1的HSPICE任务,耗时14小时。
实证场景二:大规模业务验证
超大规模计算任务
结论:
1、增加计算资源并优化任务拆分方式后,云端调度1920核计算资源,将一组超大规模计算任务(共计24个HSPICE任务)的计算周期从原有的30天缩短至17小时即可完成,云端最优计算周期与本地计算周期相比,效率提升42倍;
2、由fastone平台自研的Auto-Scale功能,使平台可根据HSPICE任务状态在云端自动化构建计算集群,并根据实际需求自动伸缩,计算完成后自动销毁,在提升效率的同时有效降低成本;
3、随着计算周期的缩短,设备断电、应用崩溃等风险也相应降低,作业中断的风险也大大降低。在本实例中未发生作业中断。
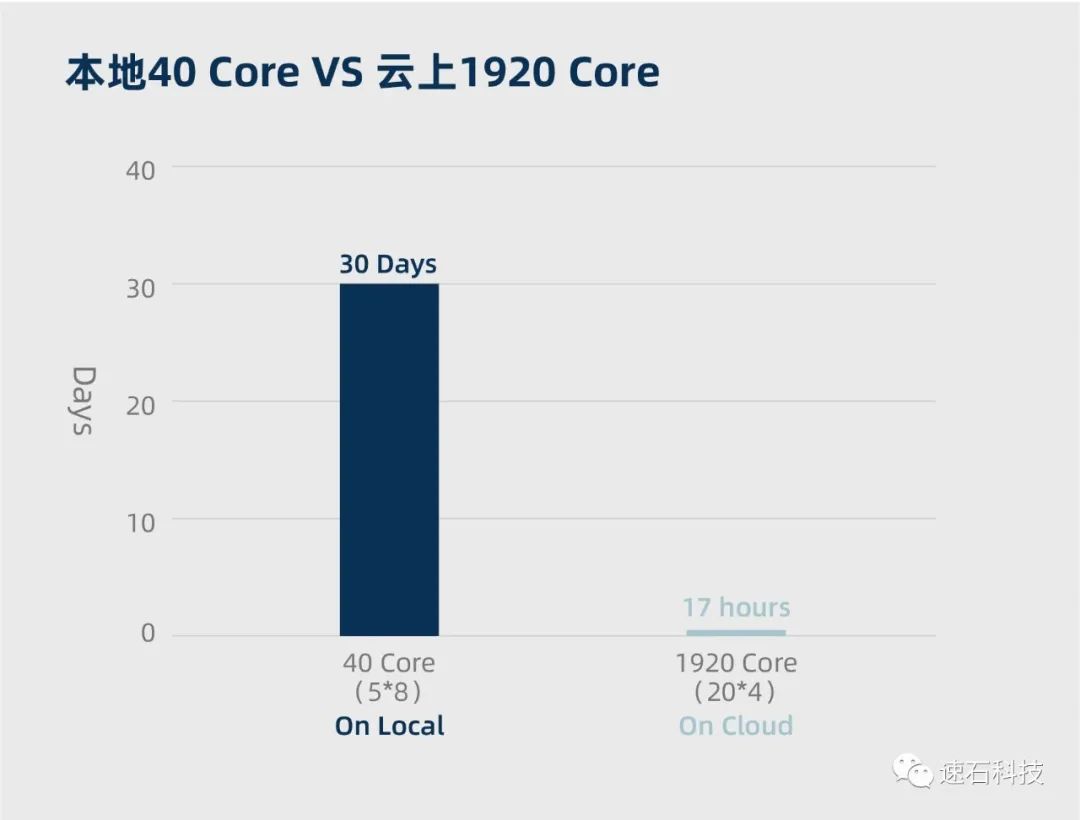
实证过程:
1、本地使用40核计算资源,拆分为5*8核,运行编号从0到23共计24个HSPICE任务,耗时约30天;
2、云端调度1920核计算资源,拆分为24组,每组为20*4核,运行编号从0到23共计24个HSPICE任务,耗时17个小时。
实证小结
我们回顾一下实证目标:
1、HSPICE任务在云端能高效运行;
2、异构的云端资源能更好适配HSPICE任务需求,避免资源浪费;
3、fastone平台有效解决了算力不足问题,效率提升42倍;
4、相比手动模式,fastone平台自研的Auto-Scale功能,既能有效提升部署效率,降低部署门槛,又能大大缩短整个计算周期资源占用率,节约成本。
至于本次实证场景没用到的跨区域,跨机型使用,还有根据GPU的需求来实现自动伸缩,我们下次再聊。
本次半导体行业Cloud HPC实证系列Vol.1就到这里了。
审核编辑 :李倩
-
模拟IC设计中Spectre和HSPICE仿真工具的起源、差别和优劣势2025-01-03 4354
-
hspice共源放大电路仿真分析2024-09-27 2595
-
从30天到17小时,如何让HSPICE仿真效率提升42倍?2023-07-05 2238
-
Hspice模拟电路仿真软件手册2022-09-01 854
-
HSPICE简明教程免费下载2022-03-24 916
-
CMSIS-NN神经网络内核可以让微控制器效率提升5倍是真的吗?2021-03-15 1916
-
HSPICE的简明教程免费下载2021-03-03 1606
-
Star-Hspice_Manual_guide2016-02-24 1372
-
HSPICE 仿真2013-12-09 3951
-
Star-Hspice特征与应用2011-04-09 1054
-
HSPICE基础知识2009-09-28 1522
-
HSPICE参考手册2008-07-13 8177
全部0条评论

快来发表一下你的评论吧 !
