

为什么要使用反向映射 Linux2.6中如何实现反向映射
今日头条
描述
1、为什么要使用反向映射
物理内存的分页机制,一个PTE(Page Table Entry)对应一个物理页,但一个物理页可以由多个PTE与之相对应,当该页要被回收时,Linux2.4的做法是遍历每个进程的所有PTE判断该PTE是否与该页建立了映射,如果建立则取消该映射,最后无PTE与该相关联后才回收该页。该方法显而易见效率极低,因为其为了查找某个页的关联PTE遍历了所有的PTE,我们不禁想:如果把每个页关联的PTE保存在页结构里面,每次只需要访问那些与之相关联的PTE不很方便吗?确实,2.4之后确实采用过此方法,为每个页结构(Page)维护一个链表,这样确实节省了时间,但此链表所占用的空间及维护此链表的代价很大,在2.6中弃之不用,但反向映射机制的思想不过如此,所以还是有参考价值的,
2.6内核新引入的反向映射
反向映射是2.6内核中新引入的一个机制,主要是为了加速页面置换的时候的效率,由于内核中的页面是不区分进程的,多个进程很有可能会共享一个页面,内核只管每个页面必须和一个或者多个pte对应,反过来,每一个present位为1的pte必须和一个页面相对应,这个反过来的对应是个一一映射关系,但是前面的却不然,也就是说页面到pte的映射却不是一一映射的关系,而在一个页面将要被换出物理内存的时候必须实时更新与之相关的各个pte,由此得出的问题就是必须扫描所有的进程的所有的pte,只要找到pte所对应的页面是将要被换出的页面就更新之,这样效率未免太低下,为什么呢?因为页面被换出本应该只涉及页面和与该页面相关的实体,如果为了找到这些所谓的相关实体而消耗大量的时间和空间资源,那么这必然是一个瓶颈,并且这个缺陷是一定可以弥补的,为什么可以弥补呢?因为我们需要做的仅仅是记录下和此页面相关的实体就可以了,而不是通过遍历寻找的方式,这样可以滤去很多无关的查找,必然的一种可能是浪费了空间来存储额外的信息,带来的优惠就是节省了大量的时间,这就是反向映射的设计初衷,那么反向映射是怎么实现的呢?最简单的实现就是在page数据结构中扩展一个字段,实际上是一个链表,里面链接所有指向这个page的pte,换出该页面的时候遍历这个链表就会得到所有的需要更新的pte,这也是2.6的早期版本中使用的方式:
struct page {
...//别的字段就此略过
union {
struct pte_chain *chain;
pte_addr_t direct;
} pte; //这个联合式新增的
...
};
struct pte_chain {
unsigned long next_and_idx;
pte_addr_t ptes[NRPTE]; //一切为了效率,采用了缓存对齐的方式可以最小化缓存缺失
} ____cacheline_aligned;
我已经不能用除了艺术之外的其他词汇来形容以下这个函数了,当然linux内核不管艺术不艺术,最终美丽的代码终成泡影,换来的是高效,linux就是这样,下面的page_add_rmap函数好在巧妙的使用了pte_chain结构:
struct pte_chain * page_add_rmap(struct page *page, pte_t *ptep, struct pte_chain *pte_chain)
{
pte_addr_t pte_paddr = ptep_to_paddr(ptep); //得到pte的地址
struct pte_chain *cur_pte_chain;
if (!pfn_valid(page_to_pfn(page)) || PageReserved(page))
return pte_chain;
pte_chain_lock(page);
if (page->pte.direct == 0) { //新分配的页面肯定只有自己拥有pte指向,新分配的page的pte.direct肯定为0
page->pte.direct = pte_paddr; //下一次该page的pte.direct字段就不为0了
SetPageDirect(page); //设置Direct标志
inc_page_state(nr_mapped);
goto out; //第一次分配的页面不需要什么反向映射,直接返回,实际上第一次分配这个page时,待这个函数返回后,pte_chain将会被释放掉,因为它没有用
}
if (PageDirect(page)) { //如果第二次该page被引用,那么就需要反向映射了,第二次引用该页面时一共有两个pte引用之,第一个就是该页面刚刚被分配时的page->pte.direc,第二个就是当前调用的pte_paddr
ClearPageDirect(page); //清楚掉Direct标志,表明它开始使用反向映射了
pte_chain->ptes[NRPTE-1] = page->pte.direct; //从后向前设置
pte_chain->ptes[NRPTE-2] = pte_paddr;
pte_chain->next_and_idx = pte_chain_encode(NULL, NRPTE-2);
page->pte.direct = 0; //这里设置为0岂不是下次又要到上面的if (page->pte.direct == 0)里面去了,哈哈,注意page的pte是个联合体而不是结构体
page->pte.chain = pte_chain; //这个设置将使得下次上面的if (page->pte.direct == 0)通不过!
pte_chain = NULL; /* We consumed it */
goto out;
}
cur_pte_chain = page->pte.chain; //如果该page第三次被引用,那么就要从这里开始了
if (cur_pte_chain->ptes[0]) { //已经到了第一个,说明一个pte_chain已经满了,因为各个pte是从pte_chain的后面向前面推进的
pte_chain->next_and_idx = pte_chain_encode(cur_pte_chain, NRPTE - 1);
page->pte.chain = pte_chain; //下次将使用新的pte_chain
pte_chain->ptes[NRPTE-1] = pte_paddr;
pte_chain = NULL; //将pte_chain设置为NULL,目的是在外面不被释放,因为我们已经使用了
goto out;
}
cur_pte_chain->ptes[pte_chain_idx(cur_pte_chain) - 1] = pte_paddr;
cur_pte_chain->next_and_idx--; //向前推进
out:
pte_chain_unlock(page);
return pte_chain; //如果没有使用参数传进来的pte_chain,那么返回它,调用者负责释放它,只要返回一个非NULL的pte_chain就说明传进来的pte_chain没有被使用,外面的调用这需要释放之,这是本着谁申请谁释放这一基本的编程原则来的
}
上面的函数其实一点也不复杂,只要仔细阅读一定可以理解的,看完了上面的add,那么这个函数所做的一切在什么地方使用呢?答案当然是在unmap的时候,那么看一下try_to_unmap吧:
int try_to_unmap(struct page * page)
{
struct pte_chain *pc, *next_pc, *start;
int ret = SWAP_SUCCESS;
int victim_i = -1;
...
if (PageDirect(page)) { //如果是第一个页面,那么说明只有一个引用,更新之即可
ret = try_to_unmap_one(page, page->pte.direct);
if (ret == SWAP_SUCCESS) {
page->pte.direct = 0;
ClearPageDirect(page);
}
goto out;
}
start = page->pte.chain; //否则就需要遍历pte.chain了
for (pc = start; pc; pc = next_pc) { //遍历所有的pte_chain
int i;
next_pc = pte_chain_next(pc);
if (next_pc)
prefetch(next_pc);
for (i = pte_chain_idx(pc); i < NRPTE; i++) { //遍历一个pte_chain数组的ptes
pte_addr_t pte_paddr = pc->ptes[i]; //这样就找到了一个pte
...
switch (try_to_unmap_one(page, pte_paddr)) {
...//结果码处理
}
}
}
...
}
如果linux和微软一样,那么代码就到此为止了,事实证明这样已经很不错了,是的,代码优美,效率又高,一切都不错,但是linux开发中没有最好只有更好,所有的物理内存都有page结构与之对应,每个page结构中保存一个pte联合实在不是什么明智之举,毕竟很多page根本就不需要pte反向映射,比如内核使用的page以及很多只有一个进程使用的匿名页面,那么就必须想一个办法,一个懒惰的办法将这个反向映射的相关信息保存到一个用户空间使用的结构体之内,就是说只有在使用反向映射的实体中才保存反向映射信息,否则不保存,这样算法的时间复杂度不变,同时可以节省更多的空间,这样一来2.6后来的内核中就废弃了以上的优雅方式,使用了一种更加高效的方法,将反向映射信息保存到vm_area_struct结构中,因为只有用户空间的页面才会有反向映射,而vm_area_struct是只有用户空间进程才有的数据结构
void page_add_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address)
{
struct anon_vma *anon_vma = vma->anon_vma; //这个anon_vma是一定要有的,如果在fork的时候有两个vma公用了一个page,那么page显然影响了两个pte,这两个pte可以通过这两个vma得到
pgoff_t index;
anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON;
index = (address - vma->vm_start) >> PAGE_SHIFT;
index += vma->vm_pgoff;
index >>= PAGE_CACHE_SHIFT - PAGE_SHIFT;
if (atomic_inc_and_test(&page->_mapcount)) {
page->index = index;
page->mapping = (struct address_space *) anon_vma; //2.6的稍微后期的版本中巧妙使用page的mapping字段存储了反向映射的信息,当然光有page的字段不行,必须要有有个地方将pte链接在一起才行,这个结构就是上面的anon_vma,这个anon_vma是vma中多出来的字段,可能浪费了一些空间,但是说实话vma中页面在物理内存的数量与page的数量相比还是要少啊,因此相比前一个解决方案还是节省了空间。
inc_page_state(nr_mapped);
}
}
2.6后期的方案利用了mapping的低位没有用的特征从而使用了这些位,利用了一切可以利用的空间,并且这个方案将匿名反向映射和文件缓存反向映射分离,在文件反向映射中使用优先级树高效处理,相比前一个早期的版本性能提高了不少。2.6的后期版本中的反向映射解决方案的资料是比较多的,我就不多说了,但是早期的反向映射的资料比较少,因此本文就分析了代码。本文主要想表达的意思就是linux的后期版本的性能基本都比以前的高,不管它的代码的可读性有多糟糕,其实阅读linux代码和理解代码的关键就是理解作者的设计思想,最好的办法就是看changelog,只要理解了changelog就可以理解作者的意图,读懂了代码才可以修改代码,才可以添加自己的逻辑,开发自己的内核。
2、Linux2.6中是如何实现反向映射
(以下代码均来自内核版本2.6.11.)
2.1 与RM(Reverse Mapping)相关的结构
page, address_space, vm_area_struct, mm_struct, anon_vma.
以下均显示部分成员:
struct page{
struct address_space *mapping; /* address_space类型,为对齐需要,其值为4的位数,所以最低两位无用,为充分利用资源,所以此处利用此最低位。
* 最低位为1表示该页为匿名页,并且它指向anon_vma对象。
* 最低为0表映射页,此时mapping指向文件节点地址空间。
*/
atomic_t _mapcount; /* 取值-1时表示没有指向该页框的引用,
取值0时表示该页框不可共享
取值大于0时表示该页框可共享表示有几个PTE引用
*/
pgoff_t index;
};
struct mm_struct {
pgd_t * pgd;
}
truct vm_area_struct {
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
}
struct anon_vma {
spinlock_t lock; /* Serialize access to vma list */
struct list_head head; /* List of private "related" vmas */
};
2.2 进程地址空间
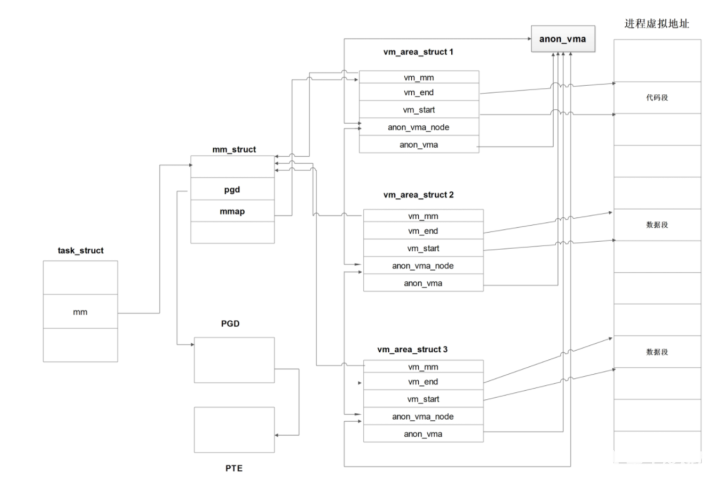
每个进程有个进程描述符task_struct,其中有mm域指向该进程的内存描述符mm_struct。
每个进程都拥有一个内存描述符,其中有PGD域,指向该进程地址空间的全局页目录;mmap域指向第一个内存区域描述符vm_area_strut1。
进程通过内存区域描述符vm_area_struct管理内存区域,每个内存区域描述符都有vm_start和vm_end域指向该内存区域的在虚拟内存中的起始位置;vm_mm域指向该进程的内存描述符;每个vm_area_struct都有一个anon_vma域指向该进程的anon_vma;
每个进程都有一个anon_vma,是用于链接所有vm_area_struct的头结点,通过vm_area_struct的anon_vma_node构成双循环链表。
最终形成了上图。
现在假设我们要回收一个页,我们要做的是访问所有与该页相关联的PTE并修改之取消二者之间的关联。与之相关联的函数为:try_to_unmap。
2.3 try_to_unmap
2.3.1 try_to_unmap函数及PageOn宏 分析
int try_to_unmap(struct page *page)
{
int ret;
BUG_ON(PageReserved(page));
BUG_ON(!PageLocked(page));
/*判断是不是匿名页,若是的话执行try_to_unmap_anon函数,否则的话执行try_to_unmap_file函数*/
if (PageAnon(page)) // PageAnon函数分析在下面
ret = try_to_unmap_anon(page);
else
ret = try_to_unmap_file(page);
if (!page_mapped(page))
ret = SWAP_SUCCESS;
return ret;
}
static inline int PageAnon(struct page *page)
{
return ((unsigned long)page->mapping & PAGE_MAPPING_ANON) != 0;
/* #define PAGE_MAPPING_ANON 1 此函数非常easy,就是判断page的mapping成员的末位是不是1,是的话返回1,不是的话返回0*/
}
2.3.2 try_to_unmap_anon函数及page_lock_anon_vma函数及list_for_each_entry宏 分析
还没开始看文件系统一节,所以try_to_unmap_file没看懂,所以此处只分析 try_to_unmap_anon函数,等看完vfs后再来补充吧。
static int try_to_unmap_anon(struct page *page)
{
struct anon_vma *anon_vma;
struct vm_area_struct *vma;
int ret = SWAP_AGAIN;
anon_vma = page_lock_anon_vma(page); /* 获取该匿名页的anon_vma结构
* page_lock_anon_vma函数分析在下面。
*/
if (!anon_vma)
return ret;
list_for_each_entry(vma, &anon_vma->head, anon_vma_node) { /* 循环遍历
* list_for_each_entry分析在下面
* anon_vma就是上图中anon_vma的指针,anon_vma->head得到其head成员(是list_head)类型,
* 其next值便对应上图中vm_area_struct1中的anon_vma_node中的head。
* vma 是vm_area_struct类型的指针,anon_vma_node为typeof(*vma)即vm_area_struct中的成员。
* 到此便可以开始双链表循环
*/
ret = try_to_unmap_one(page, vma); // 不管是调用try_to_unmap_anon还是try_to_unmap_file最终还是回到try_to_unmap_one上
if (ret == SWAP_FAIL || !page_mapped(page))
break;
}
spin_unlock(&anon_vma->lock);
return ret;
}
static struct anon_vma *page_lock_anon_vma(struct page *page)
{
struct anon_vma *anon_vma = NULL;
unsigned long anon_mapping;
rcu_read_lock();
anon_mapping = (unsigned long) page->mapping;
if (!(anon_mapping & PAGE_MAPPING_ANON))
goto out;
if (!page_mapped(page))
goto out;
// 前面已经提到,mapping最低位为1时表匿名页,此时mapping是指向anon_vma指针,故此处-1后强制转化为struct anon_vma指针类型,并返回该值。
anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
spin_lock(&anon_vma->lock);
out:
rcu_read_unlock();
return anon_vma;
}
/* 参数含义:
* head是list_head指针,无非此处需要的第一个list_head是head->next
* pos是个指向包含list_head的结构体的指针,可以用typeof(*pos)解引用来得到此结构体
* member 是list_head在typeof(*pos)中的名称
* 这样pos = list_entry((head)->next, typeof(*pos), member)第一次便初始化pos为指向包含head->next指向的那个结构体的指针。
* 之后便是双循环链表遍历了
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \ // list_entry分析在下面
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/* list_entry函数其实非常简单,其各参数的意义:
* ptr 指向list_head类型的指针
* type 包含list_head类型的结构体
* member list_head在type中的名称
* 返回值:包含ptr指向的list_head的类型为type的指针,即由list_head指针得到包含此list_head结构体的指针,实现也很简单,ptr减去member在type中的偏移即可
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
2.3.3 try_to_unmap_one函数及vma_address函数及pdg_offset宏 分析
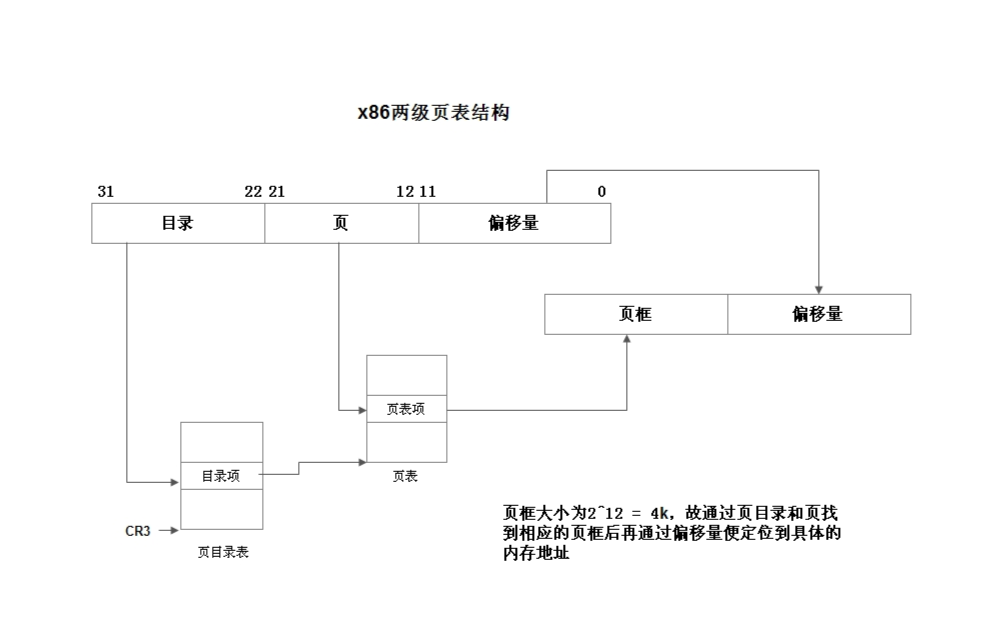
Linux采用三级页表:
PGD:顶级页表,由pgd_t项组成的数组,其中第一项指向一个二级页表。
PMD:二级页表,由pmd_t项组成的数组,其中第一项指向一个三级页表(两级处理器没有物理的PMD)。
PTE:是一个页对齐的数组,第一项称为一个页表项,由pte_t类型表示。一个pte_t包含了数据页的物理地址。
static int try_to_unmap_one(struct page *page, struct vm_area_struct *vma)
{
struct mm_struct *mm = vma->vm_mm;
unsigned long address;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
pte_t pteval;
int ret = SWAP_AGAIN;
if (!mm->rss)
goto out;
address = vma_address(page, vma); /* 通过页和vma得到线性地址
* vm_address函数解析在下面
*/
if (address == -EFAULT)
goto out;
/*
* We need the page_table_lock to protect us from page faults,
* munmap, fork, etc...
*/
spin_lock(&mm->page_table_lock); // 页表锁
pgd = pgd_offset(mm, address); /* 获得pdg
* pdg_offset通过内存描述符和线性地址得到pgd
* 该函数解析在下面
*/
if (!pgd_present(*pgd))
goto out_unlock;
pud = pud_offset(pgd, address); /* 获得pud
i386上应该是0吧?
*/
if (!pud_present(*pud))
goto out_unlock;
pmd = pmd_offset(pud, address); /* 获得pmd */
if (!pmd_present(*pmd))
goto out_unlock;
pte = pte_offset_map(pmd, address); /* 获得pte */
if (!pte_present(*pte))
goto out_unmap;
/* 有了pgd pmd pte 后我们便达到我们目的了 ===> 查找与页相关联系的页表项,找到后便可以进行修改了(如果是要换出该页的话则应该解除映射pte_unmap()函数)
* 但修改之前还要做些判断和处理
*/
//
if (page_to_pfn(page) != pte_pfn(*pte))
goto out_unmap;
/*
* If the page is mlock()d, we cannot swap it out.
* If it's recently referenced (perhaps page_referenced
* skipped over this mm) then we should reactivate it.
*/
if ((vma->vm_flags & (VM_LOCKED|VM_RESERVED)) ||
ptep_clear_flush_young(vma, address, pte)) {
ret = SWAP_FAIL;
goto out_unmap;
}
/*
* Don't pull an anonymous page out from under get_user_pages.
* GUP carefully breaks COW and raises page count (while holding
* page_table_lock, as we have here) to make sure that the page
* cannot be freed. If we unmap that page here, a user write
* access to the virtual address will bring back the page, but
* its raised count will (ironically) be taken to mean it's not
* an exclusive swap page, do_wp_page will replace it by a copy
* page, and the user never get to see the data GUP was holding
* the original page for.
*
* This test is also useful for when swapoff (unuse_process) has
* to drop page lock: its reference to the page stops existing
* ptes from being unmapped, so swapoff can make progress.
*/
if (PageSwapCache(page) &&
page_count(page) != page_mapcount(page) + 2) {
ret = SWAP_FAIL;
goto out_unmap;
}
/* Nuke the page table entry. */
flush_cache_page(vma, address);
pteval = ptep_clear_flush(vma, address, pte);
/* Move the dirty bit to the physical page now the pte is gone. */
if (pte_dirty(pteval))
set_page_dirty(page);
if (PageAnon(page)) {
swp_entry_t entry = { .val = page->private };
/*
* Store the swap location in the pte.
* See handle_pte_fault() ...
*/
BUG_ON(!PageSwapCache(page));
swap_duplicate(entry);
if (list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
list_add(&mm->mmlist, &init_mm.mmlist);
spin_unlock(&mmlist_lock);
}
set_pte(pte, swp_entry_to_pte(entry));
BUG_ON(pte_file(*pte));
mm->anon_rss--;
}
mm->rss--;
acct_update_integrals();
page_remove_rmap(page);
page_cache_release(page);
out_unmap:
pte_unmap(pte);
out_unlock:
spin_unlock(&mm->page_table_lock);
out:
return ret;
}
static inline unsigned long
vma_address(struct page *page, struct vm_area_struct *vma)
{
pgoff_t pgoff = page->index << (PAGE_CACHE_SHIFT - PAGE_SHIFT); /* PAGE_CACHE_SHIFT - PAGE_SHIFT值为0,其实就是把page->index赋给pgoff
* 至于为什么要这样右移一下,我也不清楚
*/
unsigned long address;
address = vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT); /* page->index是页的偏移
* vma->vm_pgoff是内存区域首地址的偏移,都是以页为单位
* 相减后再vm_start || address >= vma->vm_end)) { /* 得到的地址应该在vm->vm_start和vm_end之间,否则报错 */
/* page should be within any vma from prio_tree_next */
BUG_ON(!PageAnon(page));
return -EFAULT;
}
return address;
}
#define PGDIR_SHIFT 22 // 在i386机子上线性地址0-11位表PTE,12-21表PMD,22-31位表PGD,即线性地址右移22位的结果为其在全局页目录的偏移
#define PTRS_PER_PGD 1024 // 因PGD共10位,所以其最多可以有2^10=1024个全局描述符项
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD-1)) // 得到线性地址address在全局页目录里面的偏移
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address)) // 再加上全局描述符基地址(存储在内存描述符mm_struct中的pdg域)后便得到其在全局描述符中的具体位置便得到页在内存区域的中的偏移>便得到页在内存区域中的地址>
-
Linux内核之内存映射原理分析2022-07-21 3049
-
Linux内核地址映射模型与Linux内核高端内存详解2018-05-08 3954
-
linux系统内核中ioremap映射分析2014-08-05 2928
-
Linux如何配置本地端口映射2019-07-22 1738
-
Linux2.6在内存管理有哪些问题需要注意?2020-04-09 2106
-
Linux2.6与2.4内核驱动程序的区别是什么2021-04-25 1250
-
Linux2.4和Linux2.6的调度器对比分析,Linux2.6对调度器的改进有哪些方面?2021-04-27 1293
-
Linux2.6环境下USB设备的驱动实现2010-04-09 1583
-
编译Linux2.6内核并添加一个系统调用2011-12-01 688
-
低消耗的QAM映射与转换的电路2011-12-15 1442
-
浅析linux内存映射原理2019-08-24 2138
-
让我们一起来探索反向映射这个知识点2020-09-18 4157
-
Linux内核反向映射基础知识详解2020-11-26 3056
-
Linux或Windows上实现端口映射2023-04-07 2107
-
LabVIEW中的映射表是什么?2023-07-21 8463
全部0条评论

快来发表一下你的评论吧 !
