

盘点几种常见的数据结构
电子说
描述
1.几种常见的数据结构
这里主要总结下在工作中常碰到的几种数据结构:Array,ArrayList,List,LinkedList,Queue,Stack,Dictionary。,t>
数组Array:
数组是最简单的数据结构。其具有如下特点:
数组存储在连续的内存上。
数组的内容都是相同类型。
数组可以直接通过下标访问。
数组Array的创建:
1 int size = 5; 2 int[] test = new int[size];
创建一个新的数组时将在 CLR 托管堆中分配一块连续的内存空间,来盛放数量为size,类型为所声明类型的数组元素。如果类型为值类型,则将会有size个未装箱的该类型的值被创建。如果类型为引用类型,则将会有size个相应类型的引用被创建。
由于是在连续内存上存储的,所以它的索引速度非常快,访问一个元素的时间是恒定的也就是说与数组的元素数量无关,而且赋值与修改元素也很简单。
string[] test2 = new string[3];
//赋值
test2[0] = "chen";
test2[1] = "j";
test2[2] = "d";
//修改
test2[0] = "chenjd";
但是有优点,那么就一定会伴随着缺点。由于是连续存储,所以在两个元素之间插入新的元素就变得不方便。而且就像上面的代码所显示的那样,声明一个新的数组时,必须指定其长度,这就会存在一个潜在的问题,那就是当我们声明的长度过长时,显然会浪费内存,当我们声明长度过短的时候,则面临这溢出的风险。这就使得写代码像是投机,很厌恶这样的行为!针对这种缺点,下面隆重推出ArrayList。
ArrayList:
为了解决数组创建时必须指定长度以及只能存放相同类型的缺点而推出的数据结构。ArrayList是System.Collections命名空间下的一部分,所以若要使用则必须引入System.Collections。正如上文所说,ArrayList解决了数组的一些缺点。
不必在声明ArrayList时指定它的长度,这是由于ArrayList对象的长度是按照其中存储的数据来动态增长与缩减的。
ArrayList可以存储不同类型的元素。这是由于ArrayList会把它的元素都当做Object来处理。因而,加入不同类型的元素是允许的。
ArrayList的操作:
ArrayList test3 = new ArrayList();
//新增数据
test3.Add("chen");
test3.Add("j");
test3.Add("d");
test3.Add("is");
test3.Add(25);
//修改数据
test3[4] = 26;
//删除数据
test3.RemoveAt(4);
说了那么一堆”优点“,也该说说缺点了吧。为什么要给”优点”打上引号呢?那是因为ArrayList可以存储不同类型数据的原因是由于把所有的类型都当做Object来做处理,也就是说ArrayList的元素其实都是Object类型的,辣么问题就来了。
ArrayList不是类型安全的。因为把不同的类型都当做Object来做处理,很有可能会在使用ArrayList时发生类型不匹配的情况。
如上文所诉,数组存储值类型时并未发生装箱,但是ArrayList由于把所有类型都当做了Object,所以不可避免的当插入值类型时会发生装箱操作,在索引取值时会发生拆箱操作。这能忍吗?
注:为何说频繁的没有必要的装箱和拆箱不能忍呢?所谓装箱 (boxing):就是值类型实例到对象的转换(百度百科)。那么拆箱:就是将引用类型转换为值类型咯(还是来自百度百科)。下面举个栗子~
//装箱,将String类型的值FanyoyChenjd赋值给对象。
int info = 1989;
object obj=(object)info;
//拆箱,从Obj中提取值给info
object obj = 1;
int info = (int)obj;
那么结论呢?显然,从原理上可以看出,装箱时,生成的是全新的引用对象,这会有时间损耗,也就是造成效率降低。
List泛型List
为了解决ArrayList不安全类型与装箱拆箱的缺点,所以出现了泛型的概念,作为一种新的数组类型引入。也是工作中经常用到的数组类型。和ArrayList很相似,长度都可以灵活的改变,最大的不同在于在声明List集合时,我们同时需要为其声明List集合内数据的对象类型,这点又和Array很相似,其实List内部使用了Array来实现。
List test4 = new List();
//新增数据
test4.Add(“Fanyoy”);
test4.Add(“Chenjd”);
//修改数据
test4[1] = “murongxiaopifu”;
//移除数据
test4.RemoveAt(0);
这么做最大的好处就是
即确保了类型安全。
也取消了装箱和拆箱的操作。
它融合了Array可以快速访问的优点以及ArrayList长度可以灵活变化的优点。
LinkedList
也就是链表了。和上述的数组最大的不同之处就是在于链表在内存存储的排序上可能是不连续的。这是由于链表是通过上一个元素指向下一个元素来排列的,所以可能不能通过下标来访问。如图
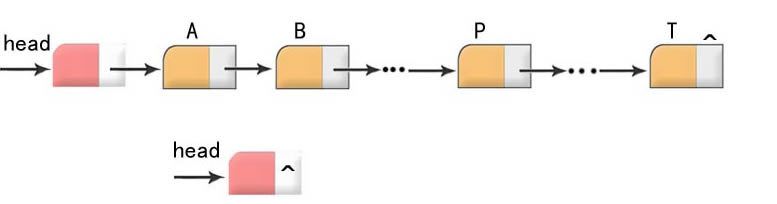
既然链表最大的特点就是存储在内存的空间不一定连续,那么链表相对于数组最大优势和劣势就显而易见了。
向链表中插入或删除节点无需调整结构的容量。因为本身不是连续存储而是靠各对象的指针所决定,所以添加元素和删除元素都要比数组要有优势。
链表适合在需要有序的排序的情境下增加新的元素,这里还拿数组做对比,例如要在数组中间某个位置增加新的元素,则可能需要移动移动很多元素,而对于链表而言可能只是若干元素的指向发生变化而已。
有优点就有缺点,由于其在内存空间中不一定是连续排列,所以访问时候无法利用下标,而是必须从头结点开始,逐次遍历下一个节点直到寻找到目标。所以当需要快速访问对象时,数组无疑更有优势。
综上,链表适合元素数量不固定,需要经常增减节点的情况。
示例:
下面的代码示例演示了类的许多功能LinkedList。
using System;
using System.Text;
using System.Collections.Generic;
public class Example
{
public static void Main()
{
// Create the link list.
string[] words =
{ "the", "fox", "jumps", "over", "the", "dog" };
LinkedList sentence = new LinkedList(words);
Display(sentence, "The linked list values:");
Console.WriteLine("sentence.Contains(\"jumps\") = {0}",
sentence.Contains("jumps"));
// Add the word 'today' to the beginning of the linked list.
sentence.AddFirst("today");
Display(sentence, "Test 1: Add 'today' to beginning of the list:");
// Move the first node to be the last node.
LinkedListNode mark1 = sentence.First;
sentence.RemoveFirst();
sentence.AddLast(mark1);
Display(sentence, "Test 2: Move first node to be last node:");
// Change the last node to 'yesterday'.
sentence.RemoveLast();
sentence.AddLast("yesterday");
Display(sentence, "Test 3: Change the last node to 'yesterday':");
// Move the last node to be the first node.
mark1 = sentence.Last;
sentence.RemoveLast();
sentence.AddFirst(mark1);
Display(sentence, "Test 4: Move last node to be first node:");
// Indicate the last occurence of 'the'.
sentence.RemoveFirst();
LinkedListNode current = sentence.FindLast("the");
IndicateNode(current, "Test 5: Indicate last occurence of 'the':");
// Add 'lazy' and 'old' after 'the' (the LinkedListNode named current).
sentence.AddAfter(current, "old");
sentence.AddAfter(current, "lazy");
IndicateNode(current, "Test 6: Add 'lazy' and 'old' after 'the':");
// Indicate 'fox' node.
current = sentence.Find("fox");
IndicateNode(current, "Test 7: Indicate the 'fox' node:");
// Add 'quick' and 'brown' before 'fox':
sentence.AddBefore(current, "quick");
sentence.AddBefore(current, "brown");
IndicateNode(current, "Test 8: Add 'quick' and 'brown' before 'fox':");
// Keep a reference to the current node, 'fox',
// and to the previous node in the list. Indicate the 'dog' node.
mark1 = current;
LinkedListNode mark2 = current.Previous;
current = sentence.Find("dog");
IndicateNode(current, "Test 9: Indicate the 'dog' node:");
// The AddBefore method throws an InvalidOperationException
// if you try to add a node that already belongs to a list.
Console.WriteLine("Test 10: Throw exception by adding node (fox) already in the list:");
try
{
sentence.AddBefore(current, mark1);
}
catch (InvalidOperationException ex)
{
Console.WriteLine("Exception message: {0}", ex.Message);
}
Console.WriteLine();
// Remove the node referred to by mark1, and then add it
// before the node referred to by current.
// Indicate the node referred to by current.
sentence.Remove(mark1);
sentence.AddBefore(current, mark1);
IndicateNode(current, "Test 11: Move a referenced node (fox) before the current node (dog):");
// Remove the node referred to by current.
sentence.Remove(current);
IndicateNode(current, "Test 12: Remove current node (dog) and attempt to indicate it:");
// Add the node after the node referred to by mark2.
sentence.AddAfter(mark2, current);
IndicateNode(current, "Test 13: Add node removed in test 11 after a referenced node (brown):");
// The Remove method finds and removes the
// first node that that has the specified value.
sentence.Remove("old");
Display(sentence, "Test 14: Remove node that has the value 'old':");
// When the linked list is cast to ICollection(Of String),
// the Add method adds a node to the end of the list.
sentence.RemoveLast();
ICollection icoll = sentence;
icoll.Add("rhinoceros");
Display(sentence, "Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':");
Console.WriteLine("Test 16: Copy the list to an array:");
// Create an array with the same number of
// elements as the linked list.
string[] sArray = new string[sentence.Count];
sentence.CopyTo(sArray, 0);
foreach (string s in sArray)
{
Console.WriteLine(s);
}
// Release all the nodes.
sentence.Clear();
Console.WriteLine();
Console.WriteLine("Test 17: Clear linked list. Contains 'jumps' = {0}",
sentence.Contains("jumps"));
Console.ReadLine();
}
private static void Display(LinkedList words, string test)
{
Console.WriteLine(test);
foreach (string word in words)
{
Console.Write(word + " ");
}
Console.WriteLine();
Console.WriteLine();
}
private static void IndicateNode(LinkedListNode node, string test)
{
Console.WriteLine(test);
if (node.List == null)
{
Console.WriteLine("Node '{0}' is not in the list.\n",
node.Value);
return;
}
StringBuilder result = new StringBuilder("(" + node.Value + ")");
LinkedListNode nodeP = node.Previous;
while (nodeP != null)
{
result.Insert(0, nodeP.Value + " ");
nodeP = nodeP.Previous;
}
node = node.Next;
while (node != null)
{
result.Append(" " + node.Value);
node = node.Next;
}
Console.WriteLine(result);
Console.WriteLine();
}
}
//This code example produces the following output:
//
//The linked list values:
//the fox jumps over the dog
//Test 1: Add 'today' to beginning of the list:
//today the fox jumps over the dog
//Test 2: Move first node to be last node:
//the fox jumps over the dog today
//Test 3: Change the last node to 'yesterday':
//the fox jumps over the dog yesterday
//Test 4: Move last node to be first node:
//yesterday the fox jumps over the dog
//Test 5: Indicate last occurence of 'the':
//the fox jumps over (the) dog
//Test 6: Add 'lazy' and 'old' after 'the':
//the fox jumps over (the) lazy old dog
//Test 7: Indicate the 'fox' node:
//the (fox) jumps over the lazy old dog
//Test 8: Add 'quick' and 'brown' before 'fox':
//the quick brown (fox) jumps over the lazy old dog
//Test 9: Indicate the 'dog' node:
//the quick brown fox jumps over the lazy old (dog)
//Test 10: Throw exception by adding node (fox) already in the list:
//Exception message: The LinkedList node belongs a LinkedList.
//Test 11: Move a referenced node (fox) before the current node (dog):
//the quick brown jumps over the lazy old fox (dog)
//Test 12: Remove current node (dog) and attempt to indicate it:
//Node 'dog' is not in the list.
//Test 13: Add node removed in test 11 after a referenced node (brown):
//the quick brown (dog) jumps over the lazy old fox
//Test 14: Remove node that has the value 'old':
//the quick brown dog jumps over the lazy fox
//Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':
//the quick brown dog jumps over the lazy rhinoceros
//Test 16: Copy the list to an array:
//the
//quick
//brown
//dog
//jumps
//over
//the
//lazy
//rhinoceros
//Test 17: Clear linked list. Contains 'jumps' = False
//
Queue
在Queue这种数据结构中,最先插入在元素将是最先被删除;反之最后插入的元素将最后被删除,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。通过使用Enqueue和Dequeue这两个方法来实现对 Queue 的存取。
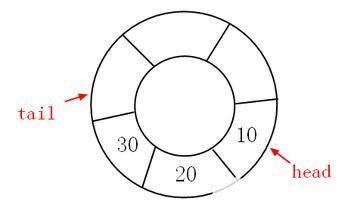
一些需要注意的地方:
先进先出的情景。
默认情况下,Queue的初始容量为32, 增长因子为2.0。
当使用Enqueue时,会判断队列的长度是否足够,若不足,则依据增长因子来增加容量,例如当为初始的2.0时,则队列容量增长2倍。
乏善可陈。
示例:
下面的代码示例演示了泛型类的几个方法 Queue 。 此代码示例创建具有默认容量的字符串队列,并使用 Enqueue 方法将五个字符串进行排队。 枚举队列的元素,而不会更改队列的状态。 Dequeue方法用于取消对第一个字符串的排队。 Peek方法用于查看队列中的下一项,然后 Dequeue 使用方法将其取消排队。
ToArray方法用于创建数组,并将队列元素复制到该数组,然后将数组传递给 Queue 采用的构造函数 IEnumerable ,创建队列的副本。 将显示副本的元素。
创建队列大小两倍的数组,并 CopyTo 使用方法从数组中间开始复制数组元素。 在 Queue 开始时,将再次使用构造函数来创建包含三个 null 元素的队列的第二个副本。
Contains方法用于显示字符串 "四" 位于队列的第一个副本中,在此之后, Clear 方法会清除副本, Count 属性显示该队列为空。
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Queue numbers = new Queue();
numbers.Enqueue("one");
numbers.Enqueue("two");
numbers.Enqueue("three");
numbers.Enqueue("four");
numbers.Enqueue("five");
// A queue can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nDequeuing '{0}'", numbers.Dequeue());
Console.WriteLine("Peek at next item to dequeue: {0}",
numbers.Peek());
Console.WriteLine("Dequeuing '{0}'", numbers.Dequeue());
// Create a copy of the queue, using the ToArray method and the
// constructor that accepts an IEnumerable.
Queue queueCopy = new Queue(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in queueCopy )
{
Console.WriteLine(number);
}
// Create an array twice the size of the queue and copy the
// elements of the queue, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second queue, using the constructor that accepts an
// IEnumerable(Of T).
Queue queueCopy2 = new Queue(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in queueCopy2 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nqueueCopy.Contains(\"four\") = {0}",
queueCopy.Contains("four"));
Console.WriteLine("\nqueueCopy.Clear()");
queueCopy.Clear();
Console.WriteLine("\nqueueCopy.Count = {0}", queueCopy.Count);
}
}
/* This code example produces the following output:
one
two
three
four
five
Dequeuing 'one'
Peek at next item to dequeue: two
Dequeuing 'two'
Contents of the copy:
three
four
five
Contents of the second copy, with duplicates and nulls:
three
four
five
queueCopy.Contains("four") = True
queueCopy.Clear()
queueCopy.Count = 0
*/
Stack
与Queue相对,当需要使用后进先出顺序(LIFO)的数据结构时,我们就需要用到Stack了。
一些需要注意的地方:
后进先出的情景。
默认容量为10。
使用pop和push来操作。
乏善可陈。
示例:
下面的代码示例演示了泛型类的几个方法 Stack 。 此代码示例创建一个具有默认容量的字符串堆栈,并使用 Push 方法将五个字符串推送到堆栈上。 枚举堆栈的元素,这不会更改堆栈的状态。 Pop方法用于弹出堆栈中的第一个字符串。 Peek方法用于查看堆栈上的下一项,然后 Pop 使用方法将它弹出。
ToArray方法用于创建数组,并将堆栈元素复制到该数组,然后将该数组传递给 Stack 采用的构造函数,并 IEnumerable 使用反转元素的顺序创建堆栈副本。 将显示副本的元素。
创建堆栈大小两倍的数组,并 CopyTo 使用方法从数组中间开始复制数组元素。 Stack再次使用构造函数来创建具有反转的元素顺序的堆栈副本; 因此,这三个 null 元素位于末尾。
Contains方法用于显示字符串 "四" 位于堆栈的第一个副本中,在此之后, Clear 方法会清除副本, Count 属性会显示堆栈为空。
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Stack numbers = new Stack();
numbers.Push("one");
numbers.Push("two");
numbers.Push("three");
numbers.Push("four");
numbers.Push("five");
// A stack can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nPopping '{0}'", numbers.Pop());
Console.WriteLine("Peek at next item to destack: {0}",
numbers.Peek());
Console.WriteLine("Popping '{0}'", numbers.Pop());
// Create a copy of the stack, using the ToArray method and the
// constructor that accepts an IEnumerable.
Stack stack2 = new Stack(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in stack2 )
{
Console.WriteLine(number);
}
// Create an array twice the size of the stack and copy the
// elements of the stack, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second stack, using the constructor that accepts an
// IEnumerable(Of T).
Stack stack3 = new Stack(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in stack3 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nstack2.Contains(\"four\") = {0}",
stack2.Contains("four"));
Console.WriteLine("\nstack2.Clear()");
stack2.Clear();
Console.WriteLine("\nstack2.Count = {0}", stack2.Count);
}
}
/* This code example produces the following output:
five
four
three
two
one
Popping 'five'
Peek at next item to destack: four
Popping 'four'
Contents of the first copy:
one
two
three
Contents of the second copy, with duplicates and nulls:
one
two
three
stack2.Contains("four") = False
stack2.Clear()
stack2.Count = 0
*/
Dictionary,t>
提到字典就不得不说Hashtable哈希表以及Hashing(哈希,也有叫散列的),因为字典的实现方式就是哈希表的实现方式,只不过字典是类型安全的,也就是说当创建字典时,必须声明key和item的类型,这是第一条字典与哈希表的区别。关于哈希,简单的说就是一种将任意长度的消息压缩到某一固定长度,比如某学校的学生学号范围从00000~99999,总共5位数字,若每个数字都对应一个索引的话,那么就是100000个索引,但是如果我们使用后3位作为索引,那么索引的范围就变成了000~999了,当然会冲突的情况,这种情况就是哈希冲突(Hash Collisions)了。
回到Dictionary,我们在对字典的操作中各种时间上的优势都享受到了,那么它的劣势到底在哪呢?对嘞,就是空间。以空间换时间,通过更多的内存开销来满足我们对速度的追求。在创建字典时,我们可以传入一个容量值,但实际使用的容量并非该值。而是使用“不小于该值的最小质数来作为它使用的实际容量,最小是3。”(老赵),当有了实际容量之后,并非直接实现索引,而是通过创建额外的2个数组来实现间接的索引,即int[] buckets和Entry[] entries两个数组(即buckets中保存的其实是entries数组的下标),这里就是第二条字典与哈希表的区别,还记得哈希冲突吗?对,第二个区别就是处理哈希冲突的策略是不同的!字典会采用额外的数据结构来处理哈希冲突,这就是刚才提到的数组之一buckets桶了,buckets的长度就是字典的真实长度,因为buckets就是字典每个位置的映射,然后buckets中的每个元素都是一个链表,用来存储相同哈希的元素,然后再分配存储空间。,t>
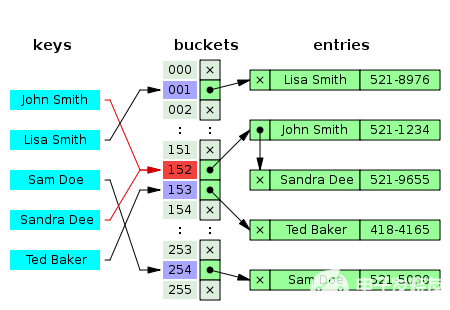
因此,我们面临的情况就是,即便我们新建了一个空的字典,那么伴随而来的是2个长度为3的数组。所以当处理的数据不多时,还是慎重使用字典为好,很多情况下使用数组也是可以接受的。
几种常见数据结构的使用情景
| Array | 需要处理的元素数量确定并且需要使用下标时可以考虑,不过建议使用List |
|---|---|
| ArrayList | 不推荐使用,建议用List |
| List泛型List | 需要处理的元素数量不确定时 通常建议使用 |
| LinkedList | 链表适合元素数量不固定,需要经常增减节点的情况,2端都可以增减 |
| Queue | 先进先出的情况 |
| Stack | 后进先出的情况 |
| Dictionary | 需要键值对,快速操作 |
-
NetApp的数据结构是如何演变的2023-08-25 556
-
嵌入式技术数据结构中常见的树有哪些?2023-05-29 1094
-
算法和数据结构基础知识分享(上)2023-04-06 1644
-
常见的数据结构2020-05-10 2759
-
什么是数据结构?为什么要学习数据结构?数据结构的应用实例分析2018-09-26 1558
-
为什么要学习数据结构?数据结构的应用详细资料概述免费下载2018-09-11 1435
-
java中几种常用数据结构2018-02-08 15480
-
数据结构常见的八大排序算法2018-02-05 2053
-
数据结构是什么_数据结构有什么用2017-11-17 16720
-
数据结构2017-03-04 3386
-
数据结构与算法2016-03-30 687
-
数据结构教程,下载2009-05-14 898
全部0条评论

快来发表一下你的评论吧 !
