

使用Transformers的企业数据挑战解决方案
描述
大数据、新算法和快速计算是使现代 AI 革命成为可能的三个主要因素。然而,数据给企业带来了许多挑战:数据标记困难、数据治理效率低下、数据可用性有限、数据隐私等。
综合生成的数据是解决这些挑战的潜在解决方案,因为它通过从模型中采样来生成数据点。连续采样可以生成无限多的数据点,包括标签。这允许跨团队或外部共享数据。
生成合成数据还可以在不影响质量或真实性的情况下提供一定程度的数据隐私。成功的合成数据生成涉及在保持隐私的同时捕获分布,并有条件地生成新数据,然后这些数据可用于建立更稳健的模型或用于时间序列预测。
在这篇文章中,我们以 NVIDIA NeMo 为例,解释如何用 transformer 模型人工生成合成数据。我们解释了如何在 machine learning 算法中使用合成生成的数据作为真实数据的有效替代品,以保护用户隐私,同时做出准确的预测。
变压器:更好的合成数据发生器
Deep learning 生成模型自然适合对复杂的现实世界数据建模。两种流行的生成模型在过去取得了一些成功:可变自动编码器( VAE )和生成对抗网络( GAN )。
然而,合成数据生成的 VAE 和 GAN 模型存在已知问题:
GAN 模型中的 模式崩溃问题 会导致生成的数据错过训练数据分布中的某些模式。
由于非自回归损失, VAE 模型难以生成尖锐的数据点。
Transformer Models 最近在自然语言处理( NLP )领域取得了巨大的成功。 transformer 模型的自我注意编码和解码架构已被证明在建模数据分布方面是准确的,并且可扩展到更大的数据集。例如, NVIDIA Megatron-Turing NLG 模型使用 530B 参数获得了优异的结果。
GPT
OpenAI’s GPT3 使用 transformer 模型的解码器部分,具有 175B 参数。 GPT3 已广泛应用于多个行业和领域,从生产力和教育到创意和游戏。
GPT 模型被证明是一种优越的生成模型。如你所知,任何联合概率分布都可以根据 概率链规则 分解成一系列条件概率分布的乘积。 GPT 自回归损失直接模拟图 1 所示的数据联合概率分布。
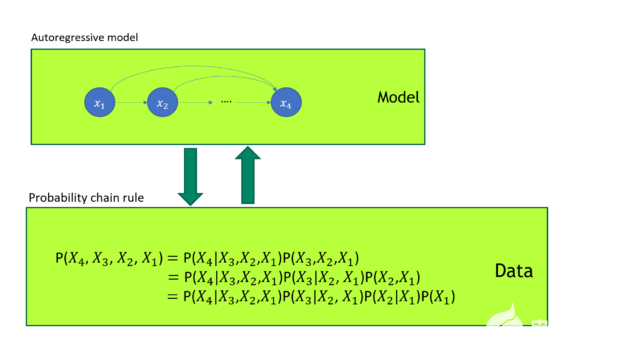
图 1 GPT 模型训练
在图 1 中, GPT 模型训练使用自回归损失。它与概率链规则有一对一的映射。 GPT 直接建模数据的联合概率分布。
由于表格数据由不同类型的数据(如行或列)组成, GPT 可以理解跨多个表格行和列的联合数据分布,并生成合成数据,就好像它是 NLP 文本数据一样。我们的 experiments 表明, GPT 模型确实可以生成更高质量的表格合成数据。
更高质量的表格数据标记器
尽管 GPT 具有优越性,但使用 GPT 对表格数据建模仍存在许多挑战: GPT 模型的数据输入是令牌 ID 序列。对于 NLP 数据集,可以使用 byte-pair encoding ( BPE )标记器将文本数据转换为标记 ID 序列。
对于表格数据集,使用通用 GPT BPE 标记器 是很自然的;然而,这种方法存在一些问题。
首先,当 GPT BPE 标记器将表格数据拆分为标记时,同一列不同行的标记数通常不是固定的,因为标记数是由单个子项的出现频率决定的。这意味着,如果使用普通 NLP 标记器,表中的列信息将丢失。
NLP 标记器的另一个问题是,列中的长字符串将由大量标记组成。考虑到 GPT 对令牌序列建模的能力有限,这是一种浪费。例如,商户名称 三井工程造船公司 需要 7 个令牌来使用 BPE 令牌化器对其进行编码([448969019424122216656168941766])。
正如 TabFormer paper 中所讨论的,一个可行的解决方案是为考虑表的结构信息的表格数据构建一个专门的标记器。 TabFormer 标记化器为每列使用一个标记,如果该列的标记数较小,则可能导致精度损失,如果标记数过大,则可能导致泛化能力较弱。
我们通过使用多个标记对列进行编码来改进它。
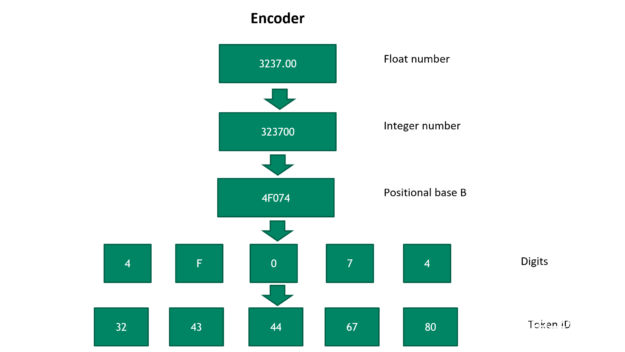
图 2 将浮点数转换为令牌 ID 序列
图 2 显示了将浮点数转换为令牌 ID 序列的步骤。首先,我们可逆地将浮点数转换为正整数。然后,它被转换成一个具有位置基 B 的数字,其中 B 是一个超参数。基 B 号越大,表示该数字所需的令牌就越少。
然而,更大的基数 B 牺牲了新数字的通用性。在最后一步中,数字被映射到唯一的令牌 ID 。要将令牌 ID 转换为浮点数,请按相反顺序运行以下步骤。然后,浮点数解码精度由令牌的数量和位置基的选择决定 B 。
基于 NeMo 框架的伸缩模型训练
NeMo 是用于培训 对话人工智能 模型的框架。在 NeMo 存储库内的 released code 中,我们的表格数据标记器支持整数和分类数据,处理 NaN 值,并支持不同的标量转换以最小化数字之间的差异。有关更多信息,请参阅我们的 源代码实现 。
您可以使用特殊的表格数据标记器来训练任何大小的表格合成数据生成 GPT 模型。由于内存限制,大型模型可能难以训练。 NeMo megatron 是一个用于在 NeMo 中训练大型语言模型的工具包,并提供 张量模型并行和管道模型并行 和 张量模型并行和管道模型并行 。
这使得 transformer 模型的训练具有数十亿个参数。除了模型并行性之外,您还可以在培训期间应用数据并行性,以充分利用集群中的所有 GPU 。根据 OpenAI 的 自然语言的尺度律 和 深度学习模型的过度参数化理论 ,考虑到训练数据的大小,建议训练大型模型以获得合理的验证损失。
将 GPT 模型应用于实际应用
在我们最近的 GTC 谈话 ,我们表明,经过训练的大型 GPT 模型可以生成高质量的合成数据。如果我们继续对经过训练的表格 GPT 模型进行采样,它可以产生无限多个数据点,这些数据点都像原始数据一样遵循联合分布。生成的合成数据提供了与原始数据相同的分析见解,但没有透露个人的私人信息。这使得安全的数据共享成为可能。
此外,如果您根据过去的数据对生成模型进行调整,以生成未来的合成数据,那么该模型实际上是在预测未来。这对金融服务行业中处理金融时间序列数据的客户很有吸引力。 与 Cohen & Steers 合作 ,我们实施了一个表格 GPT 模型,以预测经济和市场指标,包括通货膨胀、波动性和股票市场,并获得高质量的结果。
彭博社在 2022 年 GTC 上介绍了他们如何应用我们提出的合成数据方法来分析信用卡交易数据的模式,同时保护用户数据隐私。
运用你的知识
在本文中,我们介绍了使用 NeMo 生成合成表格数据的想法,并展示了如何将其用于解决实际问题。
关于作者
Yi Dong 是 NVIDIA 的深度学习解决方案架构师,负责提供金融服务业人工智能解决方案。易建联获得了博士学位。来自约翰·霍普金斯大学医学院,研究计算神经科学。易在计算机软件工程、机器学习和金融领域拥有 10 年的工作经验。易建联喜欢阅读深度学习的最新进展,并将其应用于解决财务问题。
Emanuel Scoullos 是 NVIDIA 金融服务和技术团队的数据科学家,他专注于 FSI 内的 GPU 应用。此前,他在反洗钱领域的一家初创公司担任数据科学家,应用数据科学、分析和工程技术构建机器学习管道。他获得了博士学位。普林斯顿大学化学工程硕士和罗格斯大学化学工程学士学位。
审核编辑:郭婷
-
深圳比创达电子|EMI一站式解决方案:提升企业电磁兼容性的路径.2024-05-08 3228
-
无质量损失的数据迁移:Nikon SLM Solutions信赖3Dfindit企业版2025-11-25 1116
-
睿讯企业级机房解决方案创新中心落户深圳2010-05-11 2243
-
企业IP电话解决方案--利用DSP技术与软件2011-04-23 3462
-
DKH企业级大数据解决方案的优势分析2018-11-02 2741
-
超低功光学心率监测解决方案2019-07-15 2815
-
基于射频收发器的探针无线传输数据的解决方案2019-07-19 1932
-
无线传感器网络的挑战和解决方案2019-09-17 1566
-
远程检测应用面临的主要挑战是什么?有什么解决方案吗?2021-04-30 1263
-
面向回路供电应用的数据隔离的解决方案2022-09-14 996
-
多核软件迁移与开发:挑战与解决方案2017-10-31 832
-
企业区块链是解决业务挑战的最佳方案吗2019-05-15 1152
-
企业数据可恢复,华为云数据灾备解决方案守护企业数据资产2022-10-17 1422
-
AI数据采集的挑战和解决方案2023-05-10 3430
-
HTTP海外安全挑战与解决方案:保护跨国数据传输2024-10-15 1170
全部0条评论

快来发表一下你的评论吧 !
