

基于CORTEX-M3硬件加速的目标跟踪锁定系统
描述
1.项目概述
1.1 系统实现功能介绍
在当下,很多应用场景都要用到视频目标跟踪的功能,诸如商业产品、工程实践亦或者军事技术中。它们都提出了高帧率、高精度、高鲁棒性、低功耗的硬性要求,这在当前的技术实现上仍然是一个挑战。此时就需要专用硬件加速器进行目标跟踪算法的部署,以实现低功耗、超高帧率以及高精度的需求。
在本设计中,采取Cortex-M3软核挂载大规模专用硬件加速器,在DIGILENT的NEXYS-VIDEO开发板中通过FPGA来部署硬件级别的多特征融合相关滤波目标跟踪算法加速器,做到最高每秒1000帧的运算速度,若配合高速视频传入,可以达到极高的跟踪实时性。硬件加速器挂载在软核总线中,可以通过寄存器值控制硬件加速器,进行参数设置、回传坐标以及部署智能算法。所设计的硬件加速器深度定制,可以调节从算法运算原理到跟踪模式、搜索范围等多维度的参数。同时在硬件中前置了智能目标检测算法,当有移动的目标出现在视野中,可以自动实现捕捉,传输初始坐标值至跟踪算法。
同时本设计还将通过软核操控云台、触摸屏、8路选择器,串口,按键阵列等外设,进行人机交互,优化跟踪效果,实现跟踪可视化、易操作化以及智能跟踪化。系统通过云台来使得目标始终在视频中央区域,从而进行持续的目标锁定。系统还可以通过四线电阻触摸屏进行初始信息的标定、切换任务。同时通过HDMI屏幕显示目标的实时位置,为系统操作员提供更直观的目标信息。
软核与硬件加速器通过总线寄存器控制,而软核与PC端则通过串口上位机通信,本组基于QT5.9编写专用控制端上位机,通过上位机可以更轻松的操控整套系统,方便的输入XYWH等参数,设置跟踪模式等等功能。

在本项目输入输出环路为:触摸屏和上位机作为输入设备,也可以通过智能目标检测功能自动输入坐标,上位机通过Uart串口进行系统参数及状态指令的传输。通过在FPGA内部编写触摸屏的硬件驱动来实现触摸屏坐标的解析传递。上位机与软核相连,软核的应用程序中编写与上位机相适配的程序,对跟踪器进行完全的控制,输出设备为HDMI显示屏和二维云台。在HDMI显示屏中输出目标跟踪框,同时FPGA控制二维云台进行目标的锁定。闭环系统示意图如图1-2所示:
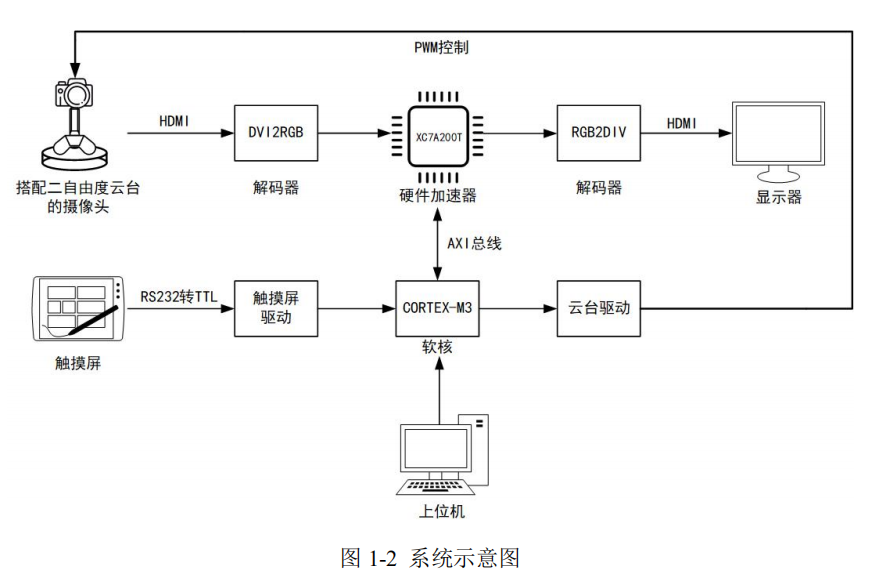
1.2 方案设计
本设计综合考虑多种图像特征,选用灰度、饱和度和HoG三种特征融合进行相关滤波,它们三者的优缺点形成互补。

我们采用CORTEX-M3加硬件加速器联合设计,系统架构图如下所示:
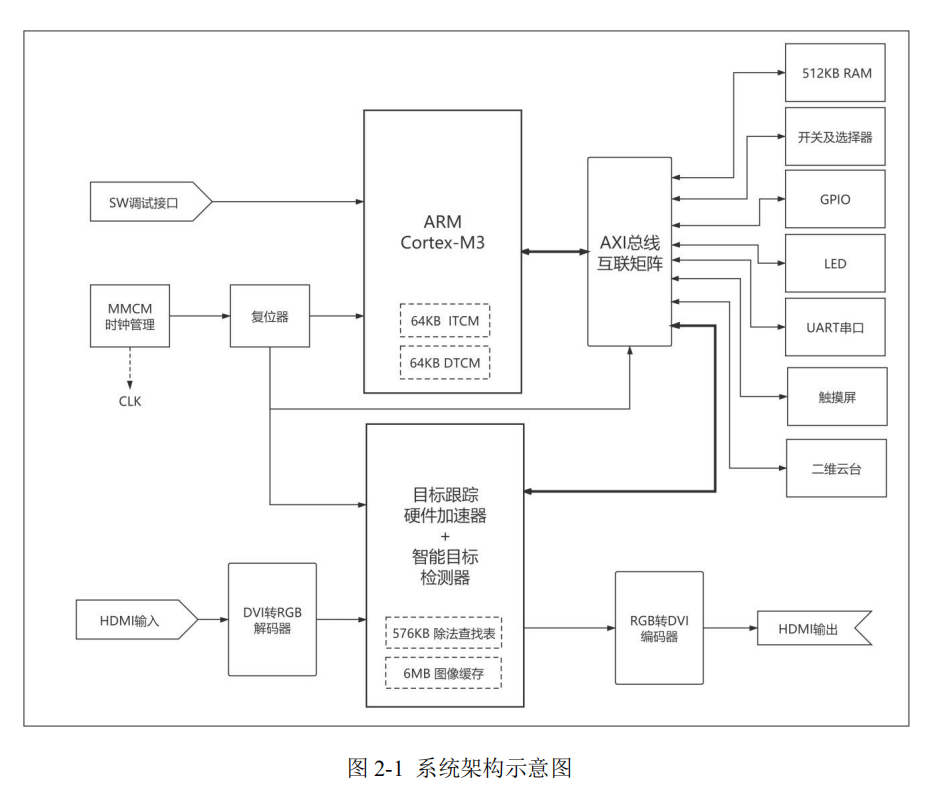
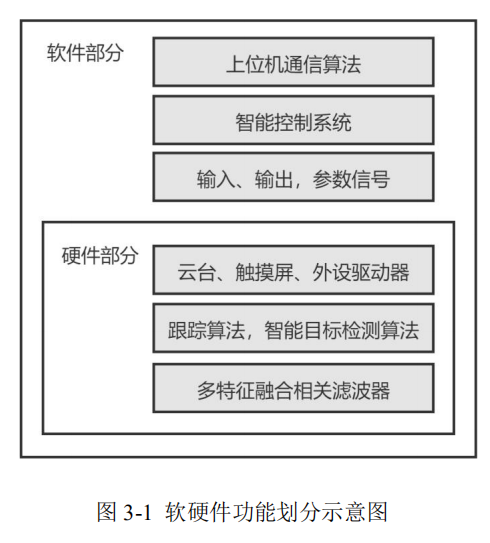
本项目采用Cortex-M3软核做控制部分,大规模专用硬件加速器做滤波跟踪计算和智能目标检测部分,视频输入输出通过HDMI直接进入硬件加速器,绕过软核实现更快的数据处理速度。整个项目的软硬件功能划分如图所示:
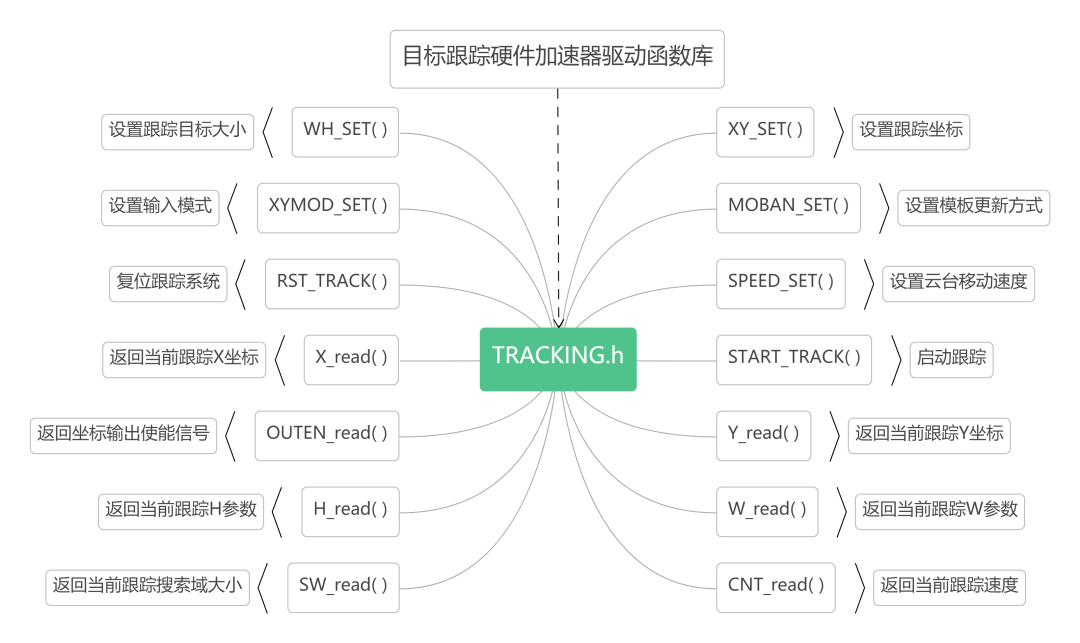
在软核中,可以通过调用我们编写的TRACKING.h库函数,使用为硬件加速器所写的驱动函数,实现硬件加速器跟踪算法的配置和运行,进行个性化算法配置。其中TRACKING.h库函数中所拥有的驱动函数如图所示。
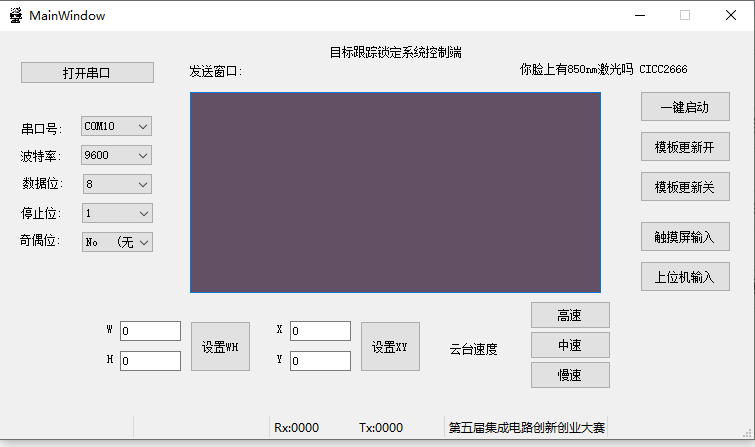
我们设计了控制端上位机,上位机为目标跟踪锁定系统控制端,由QT5软件编写完成。
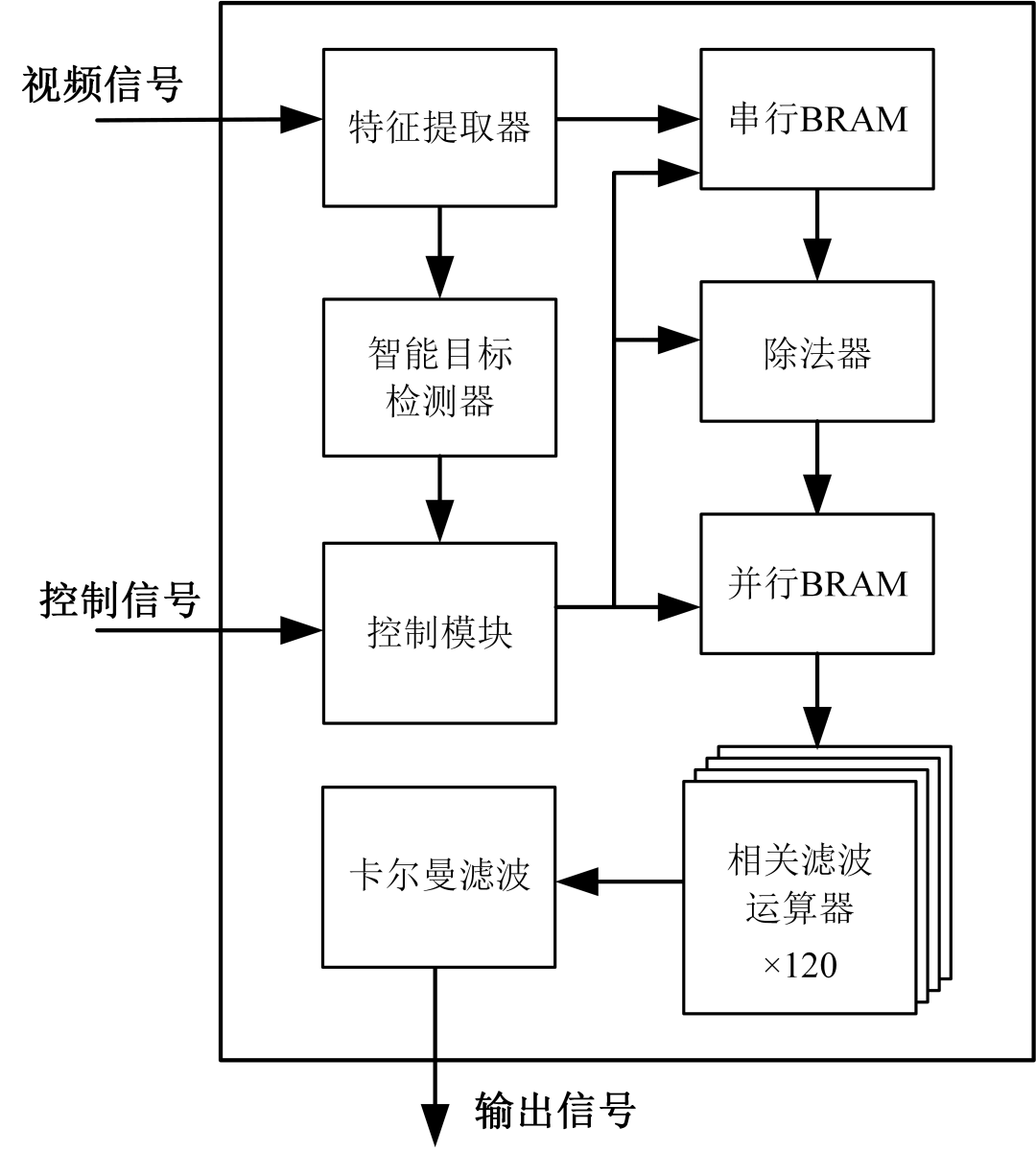
在硬件加速器中,使用多个模块共同配合完成工作,其模块图如下所示:
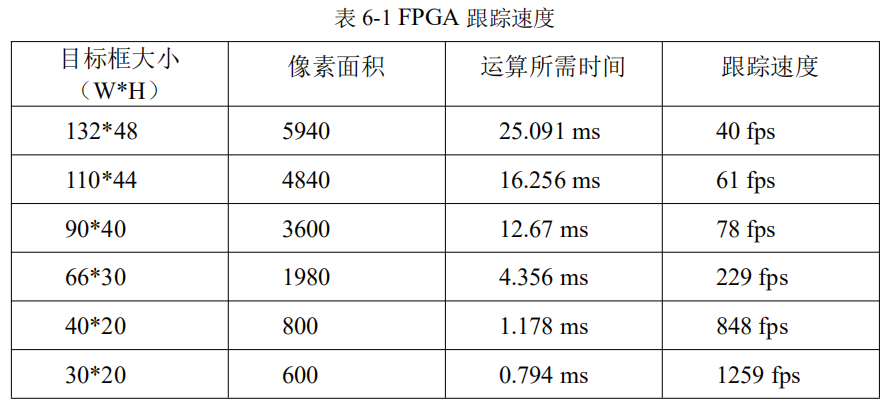
2.测试结果

算法运行在 40MHz,通过 FPGA 内部 32 位计数器实测的滤波循环速度
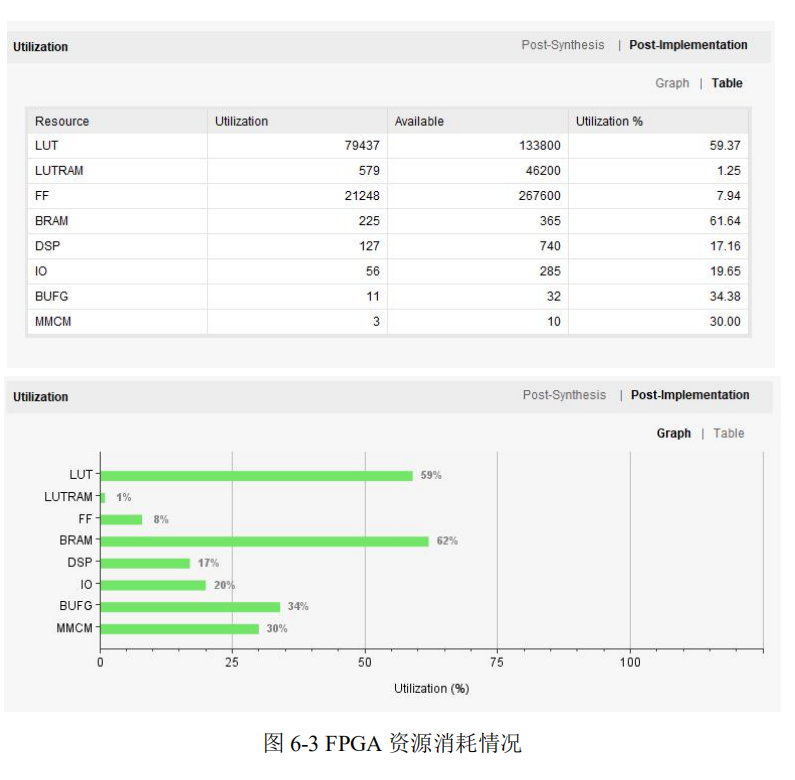
本项目在 NEXYS-VIDEO 开发板中部署,所需的 FPGA 资源如下图所示:
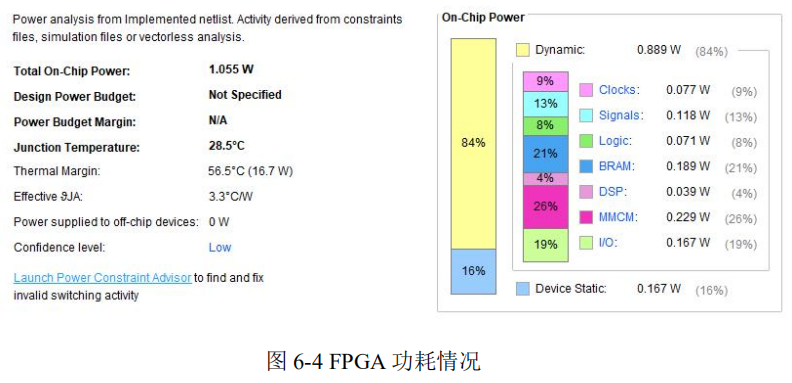
所占用的功耗较低,如下图所示:
3. 总结与展望
本组使用FPGA硬件加速器 + Cortex-M3软核所实现的基于灰度、饱和度和HoG特征融合的相关滤波跟踪算法,运行稳定,帧率较高,鲁棒性强,功率消耗低,配合摄像头可以在多个应用场景使用。例如机场检测,工地监测,无人机机载跟踪等等。同时使用灰度特征、饱和度特征和HoG特征,对摄像头要求较低,对像素要求较低。在常规目标跟踪中精度很好,超常规算法。
由于多特征融合互补,加卡尔曼滤波轨迹预测,在复杂环境中,即使一个特征受到干扰失效,也能成功通过融合响应跟踪到目标位置。即使两个特征同时受到干扰失效,比如80%以上大面积遮挡,卡尔曼滤波器也能输出预测位置,抗干扰能力较强。
在系统中使用二维云台和触摸屏外设,同时使用智能目标检测算法,实现了目标跟踪和锁定的功能,可以很方便的观察目标跟踪的情况。即可以通过触摸屏,快捷实现跟踪选点,更可以通过智能目标检测算法智能自动捕捉,人机交互方便易用。自主编写的上位机控制系统和可移植驱动函数库,使项目更适应专业的应用场景,而不拘泥于常规应用。
同时设计的系统仅需BRAM缓存,不需要DDR3内存进行缓存,整体使用纯Verilog代码编写,对外设要求较低。同时可以通过软核AXI总线扩展所需的应用。硬件加速器中参数全部引出,且设计了应用函数库,大大降低嵌入式开发所需的工作,很方便的移植到不同平台。
最后,由于硬件加速器的设计工作全部自主完成,根据逻辑分模块编写,所以能很方便的进行改进工作,在其他目标识别,视频跟踪领域,也可以对硬件加速器进行一定的改进来适配不同的场景,可塑性强。
4. 参赛体会
我们组在参加本次集创赛的过程中,踩过很多坑,赶过很多DDL,最后终于一步一步做出想要的系统。如果说最值得分享的经验,就是集创赛是一个比赛周期漫长的竞赛项目,不同于数模的三天,电赛的一周,集创赛拥有大半年的时间来完成题目。有些队伍只花费一个月来完成作品,有些队伍花费几个月,有些队伍甚至有前置的技术铺垫,这对每个队来说都是未知的。相对来说,有付出就会有回报,做的时间越长,在这道题中的感受就越深,所学到的东西就越多。
竞赛是对自己的提升,将时间放在集创赛上绝对是一个很好的选择。但与此同时,也要有效率的进行比赛,尽可能的少出BUG,三个人的团队协作要密切互补,一个人的单打独斗肯定没有团队的力量大。
在集创赛的过程中,由于参加的项目是FPGA数字方向,还要求做软核及上层应用程序,所以对我们参赛队伍的要求是很高的,不仅要会掌握Verilog的编写,FPGA的使用,还要掌握嵌入式软核的交叉编译工作,CPU的调试,总线的知识等等,在我们队伍中由于还要使用上位机,我们还学习了QT程序开发的内容。比赛所涉及的知识广度和深度都很大,需要认真努力的去学习。
审核编辑 :李倩
-
cortex-m3的操作模式及特权级别2023-03-01 8038
-
基于arm Cortex-M3处理器与深度学习加速器的实时人脸口罩检测SoC设计方案2022-08-26 4202
-
Cortex-M3处理器内核与基于Cortex-M3的MCU关系2021-11-05 2208
-
米尔科技ARM Cortex-M3教程指南2019-11-25 4222
-
致命错误:选定的核心(Cortex-M3)与目标核心(Cortex-M0)不同2019-01-14 5873
-
Cortex-M3的矿井车循迹系统设计2017-10-31 1174
-
Cortex-M3的技术参考手册2017-10-30 1631
-
Cortex-M3技术参考手册2016-12-27 1112
-
Cortex-m3内核STM32芯片的硬件库程序2015-12-29 867
-
ARM Cortex-M3权威指南2015-12-14 1087
-
Cortex-M3权威指南介绍2015-11-23 884
-
基于Cortex-m3的指纹识别考勤系统硬件设计2015-11-10 3867
-
Cortex-M3 技术参考手册2010-07-08 873
全部0条评论

快来发表一下你的评论吧 !
