

讲解霍夫曼编码提出的思路历程
描述
该视频详细讲解了霍夫曼编码提出的思路历程。
目录
故事背景
思路历程
通信系统示意
衡量信息量
编码和熵的关系
香农-冯诺编码
霍夫曼的改进
故事背景1951 年,麻省理工学院的一名研究生 David Huffman 在 Robert Fano 的信息论课程上名列前茅。Fano 教授让学生们在期末考试和学期论文间做出选择,年轻的 Huffman 在一开始就选择了学期论文。论文的题目如图 1 所示,给定一组数字或符号,找到最有效的方法来使用二进制码表示它们。

图 1 Huffman 的学期论文题目
在基础层面上,这是一个数据压缩问题。事实上你在计算机上看到的文本和图像本质上都是一组字母、数字或符号,如果将其归结为最简单的表示形式,那么它们其实都是一组 0 和 1 的组合,每个标准的数据类型都有一个标准的位表示。这个问题的本质是将它们压缩成尽可能少的位数。这是一个自计算出现以来就存在的问题,但 Fano 没有告诉学生的是,这在当时是信息论和数据压缩领域的一个未解决的问题。Huffman 在研究生时解决了这个问题,他的解决方案就是大名鼎鼎的霍夫曼编码算法。

图 2 数据压缩问题
思路历程通信系统示意在一个通信系统中,我们通常有一个信息发送方和信息接受方。发送方想要通过网络向接受方发送一些原始信息,但在网络中唯一有意义的信息是二进制比特。因此,发送方必须根据符号和二进制代码间的某种映射对原始信息进行编码。而接收方需要对二进制代码进行解码以恢复原始信息。
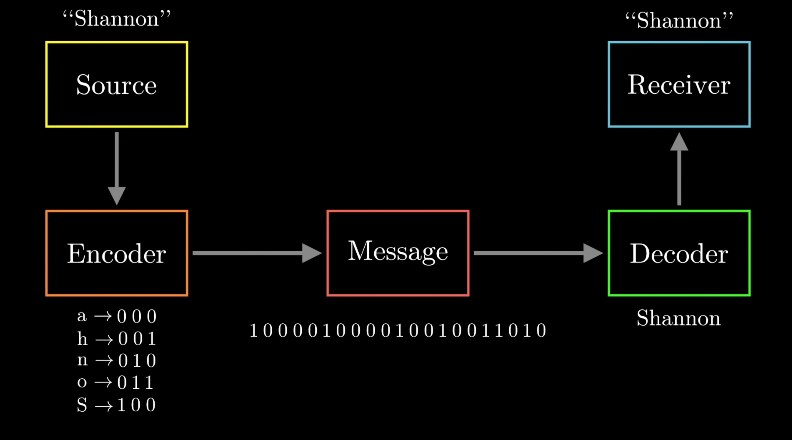
图 3 通信系统示意图
编码方法一般针对从原始信息到二进制码的映射进行优化,从原始信息到二进制码的映射有一些内在要求。一是每个符号必须被映射到唯一的二进制码,二是接收方必须能够准确解码出原始信息。霍夫曼编码算法完全符合这些要求。
衡量信息量对数据进行压缩时,我们需要考虑一种平衡。如果使用太多的比特表示符号,那么会导致冗余;如果使用太少的比特表示,则会导致信息丢失,因此最优的无损压缩算法应该在两者之间找到平衡。那么我们首先需要知道在不丢失原始信息的情况下,最大的压缩率是多少。对于这个问题,我们可以理解为,需要找到在原始信息中包含的真正的信息量是多少。那我们如何衡量信息量的多少呢?
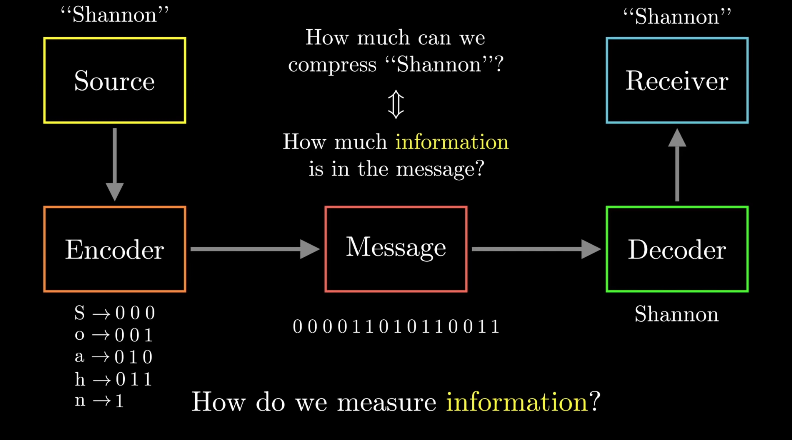
图 4 如何衡量信息量
一句话中包含的信息量与文字的长度并没有直接的关联。如图 5 所示,对于这两句话来说,显然在沙哈拉沙漠下雪所包含的信息量更大,因为在沙漠下雪的概率极小。因此可以想到,事件相关的信息量与事件发生的概率有很大的关系。

图 5 信息量例子
香农根据信息的性质总结了四个定律:
信息量的大小跟事件发生的概率反相关
信息量永远大于等于 0,因为事件的发生不会导致信息损失
如果一件事发生的概率是 100%,那么它不包含任何信息量
如果两个不相关事件被分别观察到,那么它包含的信息量应该是这两个事件单独信息量的和
香农根据这四个定律给出了自信息的定义。当信息以 bit 为单位时,log 函数的底数取 2。

图 6 自信息定义
但香农更伟大的贡献在于将自信息推广到了更广的分布上,给出了信息熵的概念,也就是著名的香农定理。香农定理作为信息论的基础,给出了衡量信息量的标准公式。

图 7 香农定理
编码和熵的关系当衡量不同编码方式的性能时,我们需要计算不同编码方式的平均字符长度。在信息论中,我们通常将符号编码的长度根据符号出现的概率进行加权求和得到平均的符号长度。香农发现,无论对符号进行哪种方式的无损压缩编码,它的长度总是大于等于信息熵,这就是香农的源编码定理。

图 8 香农源编码定理
香农-冯诺编码香农-冯诺编码首先对符号按照概率进行升序排列。然后找到最好的分割方法将符号分为两组,使得两组的符号概率和尽可能接近。之后对每个组进行递归划分,直到每个符号都被单独分为一组。
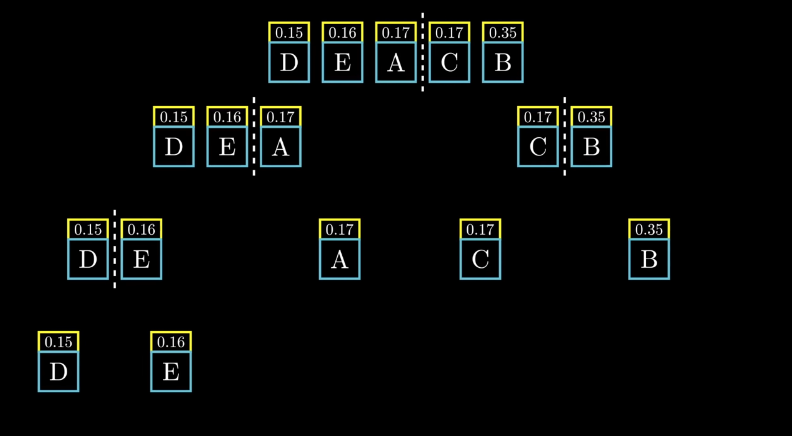
图 9 香农-冯诺编码分组
分完组之后,编码就变得很简单了。从头部向下,如果向左,那么对符号编码添加 0,向右走则添加 1,最终可以得到所有符号的二进制编码。而且对于这个树形图的表示,在解码端是不会存在歧义的。
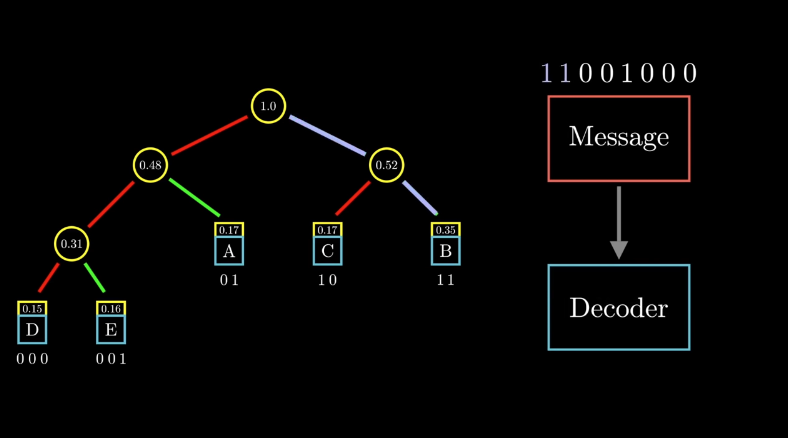
图 10 香农-冯诺编码树形图
霍夫曼的改进但是香农-冯诺编码并不总是最优的,在思考最小化平均符号长度时,可以想到,两个最不可能出现的符号应该出现在二叉树的最底部,也就是编码长度最长的地方。这符合我们的直觉,那就是最不常出现的符号应该具有更长的编码长度。因此我们可以想到,先将两个最不可能出现的符号放在最底部去构建一个二叉树,然后将这个二叉树的根节点视作一个新的符号节点,该符号节点的概率是两个子节点的和。然后对剩余的符号节点做相同的操作,直到构建出一个完整的二叉树,这就是霍夫曼编码。
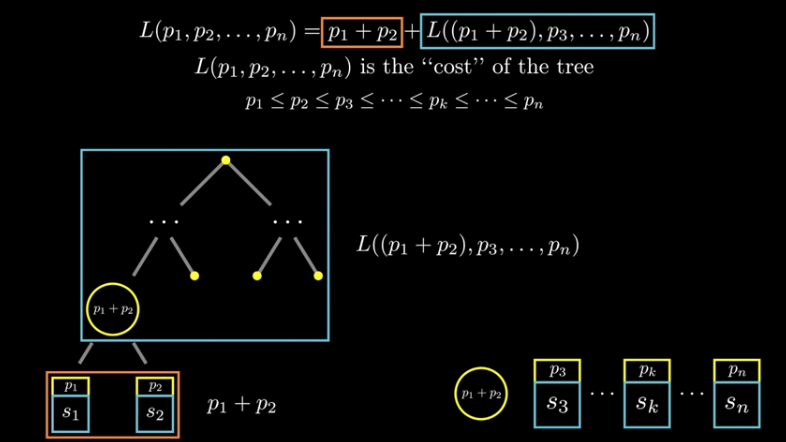
图 11 霍夫曼的改进1

图 12 霍夫曼的改进2
原文标题:[基础知识] 霍夫曼编码
文章出处:【微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
-
表示学习中7大损失函数的发展历程及设计思路2022-07-08 3762
-
使用定时器的编码器功能采集旋转编码器的信号并处理2022-01-12 1265
-
STM32——编码器测速原理及STM32编码器模式2021-11-26 4120
-
正交编码解码原理及解码思路2021-08-16 2859
-
求ucos2的相关历程和视屏讲解?2020-05-07 1534
-
如何使用霍夫曼编码原理和图像特征降低数字水印算法的复杂度2019-11-26 1249
-
什么是哈夫曼树?哈夫曼树的详细资料讲解2019-05-08 1516
-
算法科普:有趣的霍夫曼编码2019-03-14 4200
-
霍夫曼压缩算法概念解析2017-12-01 4877
-
PMSM控制中编码器UVW信号作用讲解2015-12-17 22784
-
LV仪器控制讲解带历程2012-08-11 8652
-
扬声器的霍夫曼铁定原则及讨论2011-02-21 789
-
电池的发展历程2009-10-23 3331
-
H.264视频编码基本知识2008-12-29 3566
全部0条评论

快来发表一下你的评论吧 !
