

DASK适用于Python中的并行和分布式计算
描述
Dask 是一个灵活的开源库,适用于 Python 中的并行和分布式计算。
什么是 DASK ?
Dask 是一个开源库,旨在为现有 Python 堆栈提供并行性。Dask 与 Python 库(如 NumPy 数组、Pandas DataFrame 和 scikit-learn)集成,无需学习新的库或语言,即可跨多个核心、处理器和计算机实现并行执行。
Dask 由两部分组成:
用于并行列表、数组和 DataFrame 的 API 集合,可原生扩展 Numpy 、NumPy 、Pandas 和 scikit-learn ,以在大于内存环境或分布式环境中运行。Dask 集合是底层库的并行集合(例如,Dask 数组由 Numpy 数组组成)并运行在任务调度程序之上。
一个任务调度程序,用于构建任务图形,协调、调度和监控针对跨 CPU 核心和计算机的交互式工作负载优化的任务。
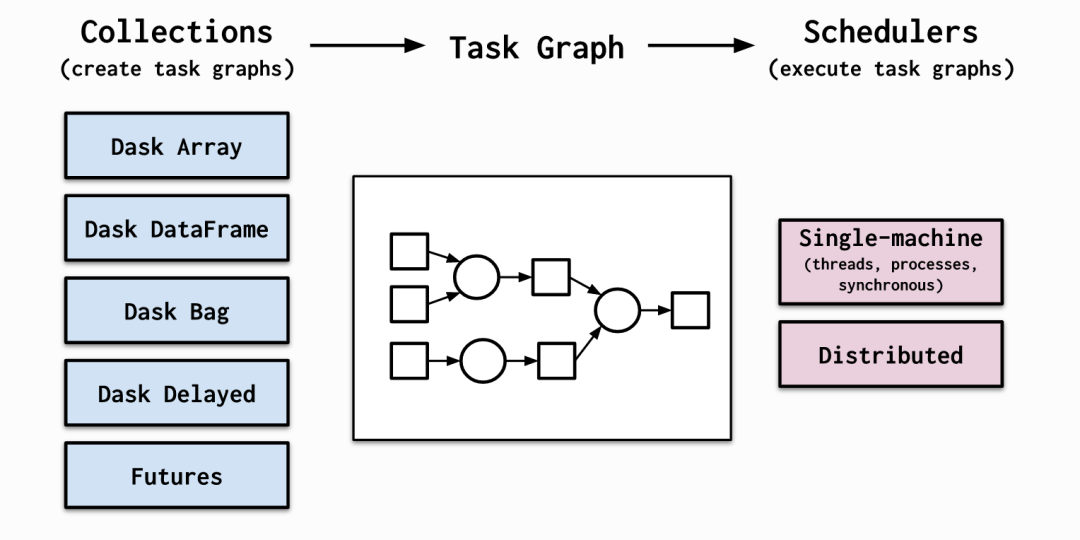
Dask 包含三个并行集合,即 DataFrame 、Bag 和数组,每个均可自动使用在 RAM 和磁盘之间分区的数据,以及根据资源可用性分布在集群中多个节点之间的数据。对于可并行但不适合 Dask 数组或 DataFrame 等高级抽象的问题,有一个“延迟”函数使用 Python 装饰器修改函数,以便它们延迟运行。这意味着执行被延迟,并且函数及其参数被放置到任务图形中。
Dask 的任务调度程序可以扩展至拥有数千个节点的集群,其算法已在一些全球最大的超级计算机上进行测试。其任务调度界面可针对特定作业进行定制。Dask 可提供低用度、低延迟和极简的序列化,从而加快速度。
在分布式场景中,一个调度程序负责协调许多工作人员,将计算移动到正确的工作人员,以保持连续、无阻塞的对话。多个用户可能共享同一系统。此方法适用于 Hadoop HDFS 文件系统以及云对象存储(例如 Amazon 的 S3 存储)。
该单机调度程序针对大于内存的使用量进行了优化,并跨多个线程和处理器划分任务。它采用低用度方法,每个任务大约占用 50 微秒。
为何选择 DASK?
Python 的用户友好型高级编程语言和 Python 库(如 NumPy 、Pandas 和 scikit-learn)已经得到数据科学家的广泛采用。
这些库是在大数据用例变得如此普遍之前开发的,没有强大的并行解决方案。Python 是单核计算的首选,但用户不得不为多核心或多计算机并行寻找其他解决方案。这会中断用户体验,还会让用户感到非常沮丧。
过去五年里,对 Python 工作负载扩展的需求不断增加,这导致了 Dask 的自然增长。Dask 是一种易于安装、快速配置的方法,可以加速 Python 中的数据分析,无需开发者升级其硬件基础设施或切换到其他编程语言。启动 Dask 作业所使用的语法与其他 Python 操作相同,因此可将其集成,几乎不需要重新写代码。
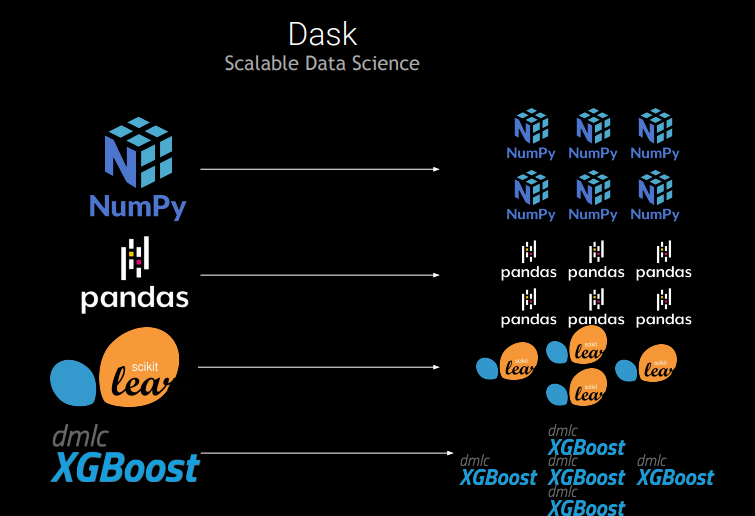
此外,由于拥有强大的网络建设堆栈,Python 受到网络开发者的青睐,Dask 可利用该堆栈构建一个灵活、功能强大的分布式计算系统,能够扩展各种工作负载。Dask 的灵活性使其能够从其他大数据解决方案(如 Hadoop 或 Apache Spark)中脱颖而出,而且它对本机代码的支持使得 Python 用户和 C/C++/CUDA 开发者能够轻松使用。
Dask 已被 Python 开发者社区迅速采用,并且随着 Numpy 和 Pandas 的普及而增长,这为 Python 提供了重要的扩展,可以解决特殊分析和数学计算问题。
Dask 的扩展性远优于 Pandas,尤其适用于易于并行的任务,例如跨越数千个电子表格对数据进行排序。加速器可以将数百个 Pandas DataFrame 加载到内存中,并通过单个抽象进行协调。
如今, Dask 由一个开发者社区管理,该社区涵盖数十家机构和 PyData 项目,例如 Pandas 、Jupyter 和 Scikit-Learn 。Dask 与这些热门工具的集成促使采用率迅速提高,在需要 Pythonic 大数据工具的开发者中采用率约达 20%。
为何 DASK 在应用 GPU 后表现更出色
在架构方面,CPU 仅由几个具有大缓存内存的核心组成,一次只可以处理几个软件线程。相比之下,GPU 由数百个核心组成,可以同时处理数千个线程。
GPU 可提供曾经深奥难测的并行计算技术。
| Dask + NVIDIA:推动可访问的加速分析
NVIDIA 了解 GPU 为数据分析提供的强大性能。因此,NVIDIA 致力于帮助数据科学、机器学习和人工智能从业者从数据中获得更大价值。鉴于 Dask 的性能和可访问性,NVIDIA 开始将其用于 RAPIDS 项目,目标是将加速数据分析工作负载横向扩展到多个 GPU 和基于 GPU 的系统。
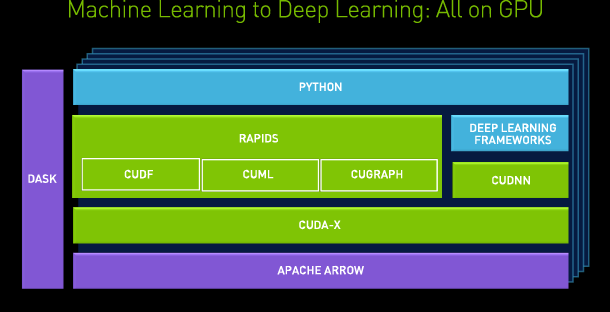
得益于可访问的 Python 界面和超越数据科学的通用性,Dask 发展到整个 NVIDIA 的其他项目,成为从解析 JSON 到管理端到端深度学习工作流程等新应用程序的不二选择。以下是 NVIDIA 使用 Dask 正在进行的许多项目和协作中的几个:
| RAPIDS
RAPIDS 是一套开源软件库和 API,用于完全在 GPU 上执行数据科学流程,通常可以将训练时间从几天缩短至几分钟。RAPIDS 基于 NVIDIA CUDA-X AI 构建,并结合了图形、机器学习、高性能计算 (HPC)等方面的多年开发经验。
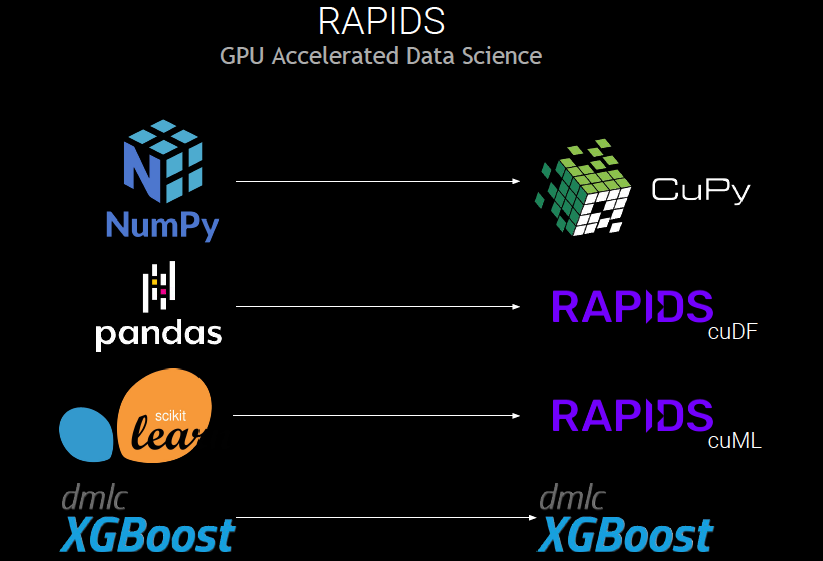
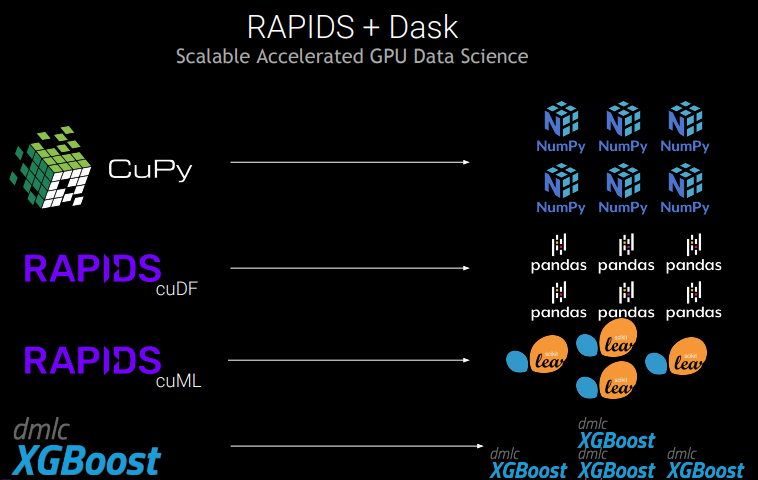
虽然 CUDA-X 功能强大,但大多数数据分析从业者更喜欢使用 Python 工具集(例如前面提到的 NumPy、Pandas 和 Scikit-learn)来试验、构建和训练模型。Dask 是 RAPIDS 生态系统的关键组件,使数据从业者能够更轻松地通过基于 Python 的舒适用户体验利用加速计算。
| NVTabular
NVTabular 是一个特征工程和预处理库,旨在快速轻松地处理 TB 级表格数据集。它基于 Dask-cuDF 库构建,可提供高级抽象层,从而简化大规模高性能 ETL 运算的创建。NVTabular 能够利用 RAPIDS 和 Dask 扩展至数千个 GPU ,消除等待 ETL 进程完成这一瓶颈。
| BlazingSQL
BlazingSQL 是一个在 GPU 上运行的速度超快的分布式 SQL 引擎,也是基于 Dask-cuDF 构建的。它使数据科学家能够轻松将大规模数据湖与 GPU 加速的分析连接在一起。借助几行代码,从业者可以直接查询原始文件格式(例如 HDFS 和 AWS S3 等数据湖中的 CSV 和 Apache Parquet),并直接将结果传输至 GPU 显存。
BlazingSQL 背后的公司 BlazingDB Inc 是 RAPIDS 的核心贡献者,并与 NVIDIA 进行了大量合作。
| cuStreamz
在 NVIDIA 内部,我们正在使用 Dask 为我们的部分产品和业务运营提供动力。我们使用 Streamz、Dask 和 RAPIDS 构建了 cuStreamz ,这是一个 100% 使用原生 Python 的加速流数据平台。借助 cuStreamz,我们能够针对某些要求严苛的应用程序(例如 GeForce NOW、NVIDIA GPU Cloud 和 NVIDIA Drive SIM)进行实时分析。虽然这是一个新兴项目,但与使用支持 Dask 的 cuStreamz 的其他流数据平台相比,TCO 已显著降低。
DASK 用例
Dask 能够高效处理数百 TB 的数据,因此成为将并行性添加到 ML 处理、实现大型多维数据集分析的更快执行以及加速和扩展数据科学制作流程或工作流程的强大工具。因此,它可以用于 HPC 、金融服务、网络安全和零售行业的各种用例。例如,Dask 与 Numpy 工作流程一起使用,在地球科学、卫星图像、基因组学、生物医学应用程序和机器学习算法中实现多维数据分析。
借助 Pandas DataFrame ,Dask 可以在时间序列分析、商业智能和数据准备方面启用应用程序。Dask-ML 是一个用于分布式和并行机器学习的库,可与 Scikit-Learn 和 XGBoost 一起使用,以针对大型模型和数据集创建可扩展的训练和预测。开发者可以使用标准的 Dask 工作流程准备和设置数据,然后将数据交给 XGBoost 或 Tensorflow 。
DASK + RAPIDS:在企业中实现创新
许多公司正在同时采用 Dask 和 RAPIDS 来扩展某些重要的业务。NVIDIA 的一些大型合作伙伴都是各自行业的领导者,他们正在使用 Dask 和 RAPIDS 来为数据分析提供支持。以下是最近一些令人兴奋的例子:
| Capital One
Capital One 的使命是“变革银行业务”,投入巨资进行大规模数据分析,为客户提供更好的产品和服务,并提高整个企业的运营效率。凭借一大群对 Python 情有独钟的数据科学家,Capital One 使用 Dask 和 RAPIDS 来扩展和加速传统上难以并行化的 Python 工作负载,并显著减少大数据分析的学习曲线。
| 美国国家能源研究科学计算中心 (NERSC)
NERSC 致力于为基础科学研究提供计算资源和专业知识,是通过计算加速科学发现的世界领导者。该使命的一部分是让研究人员能够使用超级计算来推动科学探索。借助 Dask 和 RAPIDS ,超级计算背景有限的研究人员和科学家可以轻松访问其新的超级计算机“Perlmutter”的惊人功能。他们利用 Dask 创建一个熟悉的界面,让科学家掌握超级计算能力,推动各领域取得潜在突破。
| 沃尔玛实验室
作为零售领域巨头,沃尔玛利用海量数据集更好地服务客户、预测产品需求并提高内部效率。借助大规模数据分析来实现这些目标,沃尔玛实验室转而使用 Dask 、XGBoost 和 RAPIDS,将训练时间缩短 100 倍,实现快速模型迭代和准确性提升,从而进一步发展业务。借助 Dask ,数据科学家可以利用 NVIDIA GPU 的能力解决他们最棘手的问题。
DASK 在企业中的应用:日益壮大的市场
随着其在大型机构中不断取得成功,越来越多的公司开始满足企业对 Dask 产品和服务的需求。以下是一些正在满足企业 Dask 需求的公司,它们表明市场已进入成熟期:
| Anaconda
像 SciPy 生态系统的大部分内容一样,Dask 从 Anaconda Inc 开始,在那里受到关注并发展为更大的开源社区。随着社区的发展和企业开始采用 Dask ,Anaconda 开始提供咨询服务、培训和开源支持,以简化企业的使用。作为开源软件的主要支持者,Anaconda 还聘请了许多 Dask 维护人员,为企业客户提供对该软件的深入理解。
| Coiled
由 Dask 维护人员(例如 Dask 项目主管和前 NVIDIA 员工 Matthew Rocklin)创立的 Coiled 提供围绕 Dask 的托管解决方案,以在云和企业环境中轻松运行,还提供帮助优化机构内 Python 分析的企业支持。他们公开托管的托管部署产品为同时使用 Dask 和 RAPIDS 提供了一种强大而直观的方式。
| Quansight
Quansight 致力于帮助企业从数据中创造价值,提供各种服务,推动各行各业的数据分析。与 Anaconda 类似,Quansight 为使用 Dask 的企业提供咨询服务和培训。借助 PyData 和 NumFOCUS 生态系统,Quansight 还为需要在开源软件中增强功能或修复问题的企业提供支持。
为何 DASK 对数据科学团队很重要
这一切都与加速和效率有关。开发交互式算法的开发者希望快速执行,以便对输入和变量进行修补。在运行大型数据集时,内存有限的台式机和笔记本电脑可能会让人感到沮丧。Dask 功能开箱即用,即使在单个 CPU 上也可以提高处理效率。当应用于集群时,通常可以通过单一命令在多个 CPU 和 GPU 之间执行运算,将处理时间缩短 90% 。Dask 可以启用非常庞大的训练数据集,这些数据集通常用于机器学习,可在无法支持这些数据集的环境中运行。
Dask 拥有低代码结构、低用度执行模型,并且可轻松集成到 Python、Pandas 和 Numpy 工作流程中,因此 Dask 正迅速成为每个 Python 开发者的必备工具。
原文标题:NVIDIA 大讲堂 | 什么是 DASK ?
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
常见的分布式供电技术有哪些?2023-04-10 1522
-
HDC2021技术分论坛:跨端分布式计算技术初探2021-11-15 2470
-
又一个数据分析神器并行的计算库——dask横空出现!2021-06-26 4214
-
适用于分布式MIMO系统中的时间频率同步算法研究2021-06-17 4261
-
分布式系统的优势是什么?2020-03-31 3180
-
如何利用FPGA设计无线分布式采集系统?2019-10-14 2517
-
适用于Keysight分布式仿真环境的C调试器接口和Keysight 64700系列2019-03-01 1640
-
浅谈分布式缓存技术2018-11-16 2736
-
并行计算和分布式计算的区别和联系2017-12-08 38571
-
《无线通信FPGA设计》分布式FIR的并行改写2017-02-26 3827
-
基于P2P的电力系统分布式并行计算平台设计2011-06-30 1150
-
分布式软件系统2009-07-22 5441
-
分布式计算机监测系统在火电厂中的应用2009-06-13 1008
-
基于DSP的分布式并行遗传算法2009-05-08 464
全部0条评论

快来发表一下你的评论吧 !
