

什么是基于深度学习的超分辨率
描述
去年,我在 LinkedIn 上阅读到一篇很有趣的文章,内容涉及使用基于深度学习的超分辨率网络来增加美国宇航局毅力号(Nasa’s Perseverance Rover)发回的图像和视频中包含的细微细节。这篇文章让我回想到,我在 90 年代第一次观看《银翼杀手》时,基于当时可用的技术,诸如“将 15 增强到 23”之类的场景似乎如此难以置信。那时(因为《银翼杀手》之类的电影),我正在攻读为期三年的人工智能学位课程,我无法预测到千禧年初深度学习革命的影响。你不能添加不存在的东西,我一直对自己说。但现在看来,你可以——而且非常有说服力。
超分辨率如何应用于现实世界?
超分辨率的应用非常广泛:从旧照片的怀旧修复和着色到通过对低分辨率源内容进行上采样来减少视频流带宽。正如“放大火星”(Upscaling Mars)一文的作者所解释的那样,升级行星探索飞行器上的摄像头是不可行的,因此,如果需要通过提高分辨率来获得更多细节,或者甚至在机载镜头变得模糊或损坏的灾难性场景中,最先进的超分辨率技术可以提供巨大的价值。也有许多例子表明,很多原始图像是黑白的或是历史图像视频,随着分辨率的提高,通过着色,它们被重新激活。
什么是基于深度学习的超分辨率?
基于深度学习的超分辨率是将学习的上采样(up-sampling)函数应用于图像的过程,目的是增强图像中现有的像素数据或生成合理的新像素数据,从而提高图像的分辨率。事实上,上面提到的着色示例提供了一些关于深度学习如何利用上下文关系和自然图像的统计信息的见解。假设您有一个输入面片(卷积神经网络输入图像的一个区域)“x”,那么在相应的输出面片y的颜色上存在一个条件概率分布 p( y|x ) 。
这种分布在生成输出颜色时基本考虑了上下文关系。着色神经网络通常近似于这种分布模式:它了解到黑白输入图像的特定部分(面片)有可能是特定的颜色或颜色范围,基于网络训练时与类似输入面片对应的先前输出面片。这就是黑白照片或视频的着色方式。
超分辨率网络正在以类似的方式解决一个非常类似的问题:在这种情况下,它已经学会了根据低分辨率输入面片x的上下文生成最有可能的高分辨率输出面片Y。
放大图像的功能已经存在了一段时间,所以你可能会问,为什么我们需要另一种方法?现有技术包括最近邻、双线性和双三次(三次卷积)上采样,这些技术在迄今为止的大多数图像和视频上缩放应用中已经足够了。然而,如下所示的放大输出图像的裁剪,突出显示了以这种方式将图像放大到更大分辨率时产生的一些不良伪影。
如上图所示,输出图像的裁剪包含豹子胡须上称为“锯齿”的伪影,最近邻算法也难以重建皮肤纹理,从而导致像素化。双线性和双三次算法往往会使图像过度柔化,使其看起来失焦,缺乏细节。
这些限制,加上提高显示分辨率能力的宏观趋势,在保持当前功率预算和性能的同时,正在为该领域激发一些非常令人兴奋的创新。
Visidon是一家芬兰公司,成立于 2006 年,擅长使用基于人工智能的软件技术来增强静态图像和视频内容。它开发了一套基于深度学习的超分辨率网络,可以将 1080p分辨率的图像和视频缩放到 4K (2160p) 和 8K (4320p) 分辨率。已经设计和训练了三个基于深度学习的超分辨率网络(VD1、VD2 和 VD3),每个网络的目标分别是:
快速双三次质量推理 (VD1)
快速且优于双三次质量推理 (VD2)
静止图像的最高质量超分辨率推理 (VD3)。
Imagination 如何帮助部署和加速这些算法
在60帧的情况下,使用超分辨率来提高图像和视频内容的分辨率,,这需要大量计算,而这正是 Imagination 可以提供帮助的地方。我们的 IMG 4系列 AI 计算引擎采用张量分片技术,旨在为基于卷积的神经网络提供低系统带宽、高推理率的执行——这是Visidon超分辨率解决方案中的主要算法。
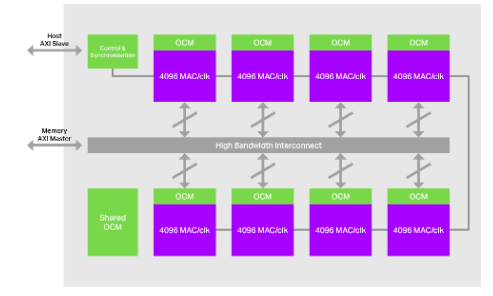
图1: IMG 4NX-MC8,Imagination 的可扩展多核架构。
我们的多核架构和获得专利的张量分片技术相结合,可以在并行处理的同时将大量图像和权重数据保留在芯片上,从而产生可扩展、强大的超分辨率性能,如下图所示:
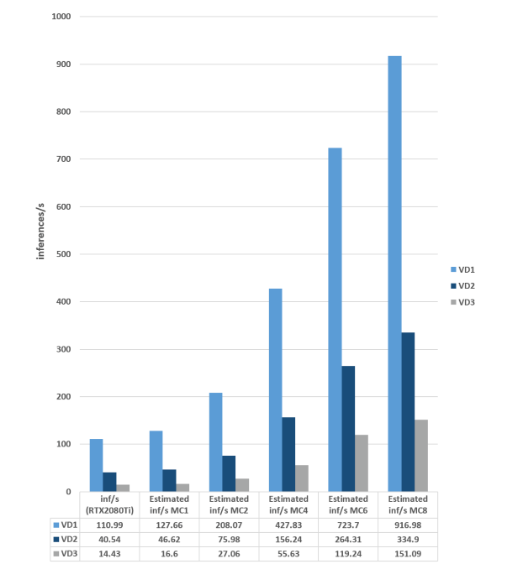
表1:IMG 4系列 NNA计算引擎上的Visidon超分辨率网络性能(将 1080p 视频转换为 4K 分辨率)
Visidon如何衡量视觉质量
Visidon网络的质量由专家和非专家参与者使用随机盲评进行评估,两组评估人员分别为七个输出版本(三个Visidon网络 (VD1-3) 和lanczos4,双三次,双线性和最近邻)进行评分。Visidon的VD 超分辨率网络质量与现有的基于非深度学习的上采样算法的比较如下表所示:
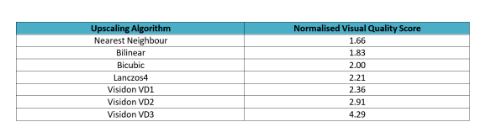
评估人员之前没有看过网络的图像或结果,也不允许讨论结果。然后将分数标准化为 1 到 5,其中双三次曲线的参考分数为2。
现在是你一直在等待的部分——视觉效果!
现在让我们来看看Visidon 的VD1、VD3 和 VD3 网络的结果,它们可以通过张量分片有效地部署在Imaginations 4系列NNA上。
注:样本图像来自Flickr2K 数据集,可免费用于商业用途,OpenCV 库用于 lanczos4、双三次、双线性以及最近邻放大,因此可以验证结果。
上面的图像对比突出了Visidon的VD3超分辨率算法的卓越品质,使花朵的所有部分都清晰、无噪,尤其是花瓣细节和黄色雄蕊。双三次算法无法充分处理边缘,使其不会因平滑而丢失。另请参阅内部花瓣与花的深色中心区域相交的位置。
另一个很好的例子是,通过Visidon网络中的适当锐化,树叶和岩石定义得以保留,而这在双三次上采样的平滑中完全丢失了。
在这个比较中,Visidon 的VD2 网络体现了微羽毛的细节和清晰度,考虑到输入图像在某些地方出现混叠,这令人印象深刻。VD2 网络通过保留羽毛图案的复杂性来从中恢复,而双三次算法无法做到这一点。喙部的细节和掠过它的小羽毛仍然清晰可见,没有明显的阶梯效应——这在双三次输出图像中可以看到,尽管很微妙。
此图像对比突出了Visidon 的VD1 网络的基线目标,即在质量上优于双三次上采样,同时提供非常高的推理性能。因此,虽然 VD1 在评估中产生了最低的感知质量,但其输出比双三次放大更清晰,可以保留了眼睛下方羽毛的细节,并且爪子下方树枝上的纹理明显更清晰。
在这里,我们看到Visidon 的网络巧妙地恢复了双三次放大中丢失的细节。多亏了Visidon 的VD3 网络,原始非常模糊的原始图像的一小部分得以精细的细节呈现出来。此外,请注意VD3 放大中水面的反射细节。难以置信!
结论
在计算能力可用于实时超分辨率图像和视频之前,现有算法已经满足了高达 1080p 分辨率的观众。但随着 4K(和 8K)显示器质量的不断提高,非深度学习算法的软化并不能完全满足新一代高分辨率观看的需要。
因此,如果采用放大技术将低分辨率内容传递到高分辨率屏幕,则必须以智能和上下文的方式保留源图像和视频的细节,以提供最愉悦的视觉体验。
Imagination 的 IMG 4系列NNA AI 计算引擎提高了计算能力,可以提供低功耗、低面积和系统带宽可扩展的卷积神经网络加速,使其成为部署Visidon最先进的基于深度学习的超分辨率解决方案的完美平台。
- 相关推荐
- 热点推荐
- 芯片
- AI
- imagination
-
直接飞行时间(DToF)视频的深度一致超分辨率重建2023-08-30 3156
-
Imagination与Visidon合作共同开辟AI超分辨率技术未来2022-05-19 2259
-
超分辨率技术大热,能不能解决物联网刚需?2022-03-17 3197
-
使用深度学习来实现图像超分辨率2020-12-14 2555
-
如何使用深度残差生成对抗网络设计医学影像超分辨率算法2019-01-02 1407
-
深度学习助攻超分辨率 商汤科技联手vivo X23幻彩版突破画质“高地”2018-12-10 1813
-
深度学习应用在超分辨率领域的9个模型2018-07-13 16023
-
基于图像超分辨率SR极限学习机ELM的人脸识别2017-12-25 1957
-
基于多字典学习超分辨率重建2017-12-19 983
-
深度反卷积神经网络的图像超分辨率算法2017-12-15 1383
-
基于POCS算法的图像超分辨率重建2010-11-08 982
-
超分辨率图像重建方法研究2009-03-14 3653
全部0条评论

快来发表一下你的评论吧 !
