

分享一个采用MLX90640的消防感官解决方案
描述
这个项目能够为消防员提供红外视觉感,以帮助他们从燃烧的建筑物中营救人员。
背景
热像仪 (TIC) 已被证明是消防员的宝贵工具。它们使消防员能够更快地找到受害者,更一致地成功驶出燃烧的房屋,并减少令人满意地完成搜索所需的时间。然而,一些问题仍然存在。寻找受害者时,需要花费时间拉出 TIC,进行设置并读取显示。手持 TIC 显示器在浓烟中难以准确看到,导致受害者定位较慢。使用显示器需要操作员将他们的眼睛和注意力从周围的环境中移开,从而导致意识丧失并增加隧道视力的风险。
利用机器学习为消防员提供红外线 (IR) 感觉的感官替代设备将是一个有用的工具。这将减少消防员在显示器上将视线从周围环境中移开的次数(也降低了隧道视力的风险),因为他们将不再觉得需要不断地监控 TIC 显示器,因为他们将不断地获得重要的 IR 信息。当感觉到适当的刺激时,他们将能够更快地做出反应,而不是不得不参考显示器,从而减少受害者的救援时间。直接将关键信息流式传输给消防员将减少显示器在浓烟中的低能见度成为问题的情况。总体而言,具有 IR 意识的消防员在搜救行动中会更有效。
如何设置项目
我们将 Qwiic 电缆(面包板跳线(4 针))连接到 MLX90640 SparkFun IR Array Breakout (MLX)。四根线(黑、红、黄、蓝)分别代表GND、VIN(3.3V)、SCL、SDA。

因为我们的 Qwiic 电缆不是母跳线,所以我们使用四根 ff 面包板线将 Qwiic 电缆引脚连接到 Raspberry Pi (Pi)。在下图中,可以看到黑色、红色、黄色和蓝色 Qwiic 引脚分别连接到棕色、红色、黄色和橙色 ff 面包板线。

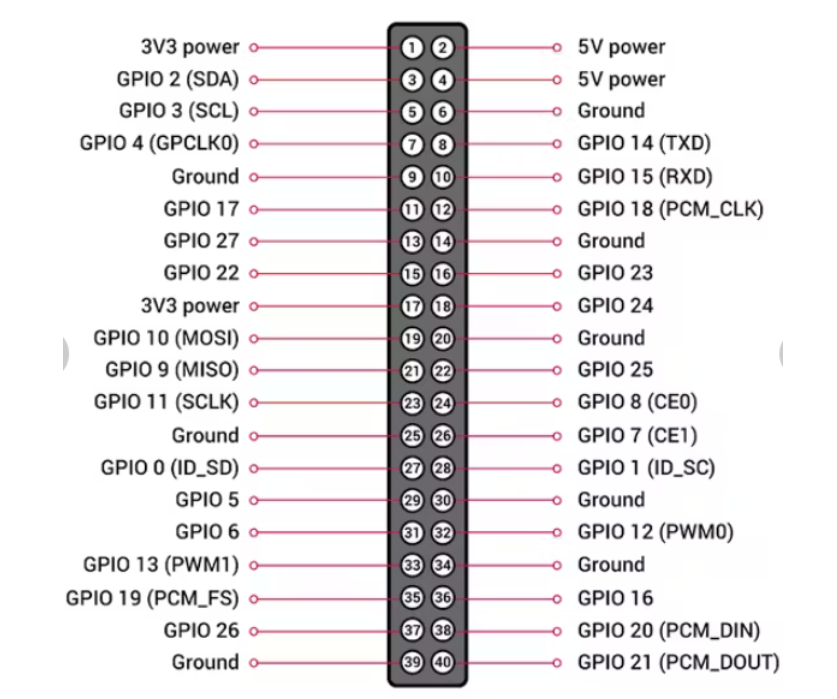
ff 面包板线的颜色并不重要,但关键是 Qwiic 电缆 GND、VIN、SCL 和 SDA 引脚连接到适当的 Pi 引脚(分别为引脚 6、1、5 和 3)。下面可以看到 Pi 引脚分配指南以及我们与 Pi 的连接。
完成后,我们创建了一个小纸板相机支架,通过切掉披萨盒的一侧来帮助支撑相机。此步骤不是必需的,因此请随意跳过它或自己制作。

实施概述
将相机连接到树莓派
使用 Adafruit 库,我们能够从 MLX90640 热像仪中读取数据。
import adafruit_mlx90640
import time,board,busio
i2c = busio.I2C(board.SCL, board.SDA, frequency=1000000) # setup I2C
mlx = adafruit_mlx90640.MLX90640(i2c) # begin MLX90640 with I2C comm
mlx.refresh_rate = adafruit_mlx90640.RefreshRate.REFRESH_2_HZ # set refresh rate
frame = [0]*768 # setup array for storing all 768 temperatures
mlx.getFrame(frame)
此时,我们将温度数据存储在一个数组中,准备好进行预处理。
预处理原始温度数据并提供给分类服务
我们的预处理步骤需要将温度数据转换为稍后可以输入到我们的边缘脉冲模型中的图像。这是使用Matplotlib 库完成的,然后将图像保存到 Buffer Stream 并编码为 base64 字符串。
mlx.getFrame(frame)
mlx_shape = (24,32)
fig = plt.figure(frameon=False)
ax = plt.Axes(fig, [0., 0., 1., 1.])
ax.set_axis_off()
fig.add_axes(ax)
thermal_image = ax.imshow(np.zeros(mlx_shape), aspect='auto')
MIN= 18.67
MAX= 43.68
data_array = (np.reshape(frame,mlx_shape)) # reshape to 24x32
thermal_image.set_data(np.fliplr(data_array)) # flip left to right
thermal_image.set_clim(vmin=MIN,vmax=MAX) # set bounds
buf = io.BytesIO()
fig.savefig(buf,format='jpg',facecolor='#FCFCFC',bbox_inches='tight')
img_b64 = base64.b64encode(buf.getvalue()).decode()
buf.close()
plt.close(fig)
使用 http post 请求将 base64 字符串和原始帧数据发送到我们的分类微服务。微服务将通过 Edge Impulse 模型运行图像,并经过一些后处理(如下所述)返回一个标志,说明是否在帧中检测到一个人,如果是,那么他们是什么方向,即左、中、右。
分类服务
分类服务接受一个 post 请求,请求中包含两个数据对象:原始数据数组和以 base64 表示的图像。图像在被传递到分类器之前需要进行预处理。首先,我们必须提取图像的原始特征。图像被解码为图像缓冲区,然后将其转换为图像的十六进制表示。这个十六进制字符串被分割成单独的 RGB 值并转换成整数,准备处理到分类器中。
let raw_features = [];
let img_buf = Buffer.from(request.body.image, 'base64')
try{
let buf_string = img_buf.toString('hex');
// store RGB pixel value and convert to integer
for (let i=0; i raw_features.push(parseInt(buf_string.slice(i, i+6), 16));
}
} catch(error) {
throw new Error("Error Processing Incoming Image");
}
原始特征被输入到分类器中,并返回一个由两个标签组成的对象。标签是图像中的人和不在图像中的人的置信度等级。
let result = {"hasPerson":false}
let classifier_result = classifier.classify(raw_features);
no_person_value = 0
person_value = 0
if(classifier_result["results"][0]["label"] === "no person"){
no_person_value = classifier_result["results"][0]["value"]
} else {
throw new Error("Invalid Model Classification Post Processing")
}
if(classifier_result["results"][3]["label"] === "person"){
person_value = classifier_result["results"][3]["value"]
} else {
throw Error("Invalid Model Classification Post Processing")
}
然后将这两个标签值与我们的置信度阈值进行比较,以确定是否有人在帧中看到过。如果没有,分类器服务会使用一个包含一个字段的对象来响应发布请求:
“hasPerson”=假。
然而,如果置信值达到或超过阈值标准,则使用原始温度数据来确定热源来自帧中的哪个位置。
if(person_value > person_threshold
&& no_person_value < no_person_threshold){
result["hasPerson"] = true
// If is person find brightspot in the image
let frame_data = request.body.frame
let column_average = new Array(32)
index_count = 0;
for(let j = 0; j < 24; j++){
for (let i = 0; i < 32; i ++){
column_average[i] = (column_average[i] || 0)
+ parseFloat(frame_data[index_count])
index_count++
}}
left_avg = 0
centre_avg = 0
right_avg = 0
for(let i = 0; i < 16; i++){
left_avg = left_avg + column_average[i]
}
for(let i = 8; i < 24; i++){
centre_avg = centre_avg + column_average[i]
}
for(let i = 17; i < 32; i++){
right_avg = right_avg + column_average[i]
}
var direction
if(left_avg > centre_avg && left_avg > right_avg){
direction = 1
} else if (centre_avg > left_avg && centre_avg > right_avg){
direction = 2
} else if (right_avg > left_avg && right_avg > centre_avg){
direction = 3
} else {
direction = 4
}
result["direction"]=direction
一个响应对象从 post 请求中返回,带有两个值:
“hasPerson” = 真
“方向” = <方向值>
我们使用Python 的 Neosensory SDK以便在将 Buzz 与 Pi 配对后向 Buzz 发送电机命令。我们选择使用时空扫描(“在空间和时间上编码的模式”),因为 Novich 和 Eagleman [2] 的一项研究发现,与空间模式和由以下组成的模式相比,它们是将数据编码到皮肤的最佳方法单个电机通过振动刺激皮肤区域。时空扫描的更高识别性能允许通过皮肤进行更大的信息传输 (IT),这意味着消防员可以接收更多有用的信息(以及获得的 IR 感知的更大潜在有效性)。因为我们只关心三个方向值,所以创建了三个扫描数组来描述一个人在框架的左侧、右侧或中心,如下所示:
sweep_left = [255,0,0,0,0,255,0,0,0,0,255,0,0,0,0,255,0,0,0,0]
sweep_right = [0,0,0,255,0,0,255,0,0,255,0,0,255,0,0,0,0,0,0,0]
sweep_centre = [255,0,0,0,0,255,0,0,0,0,0,255,0,0,255,0,0,0,0,0]
当 Pi 接收到一个响应对象,该对象表示框架中有一个人以及他们在框架中的什么位置时,就会向 Buzz 发送一个振动电机命令:
if(response['hasPerson'] == True):
print("has person")
if(response['direction']):
print(response['direction'])
if response['direction'] == 1:
await my_buzz.vibrate_motors(sweep_right)
print("Right")
elif response['direction'] == 2:
await my_buzz.vibrate_motors(sweep_centre)
print("Centre")
elif response['direction'] == 3:
await my_buzz.vibrate_motors(sweep_left)
print("Left")
else:
print("inconclusive")
else:
print("no person")
我们发现每次运行代码时都必须将 Buzz 置于配对模式,以最大程度地减少发送命令时 Buzz 不振动的可能性。
边缘脉冲
数据集收集
当 MLX 指向某人时,768 个温度值的数组被保存在一个 .txt 文件中。这些文件的组织方式是为了便于上传到 Edge Impulse,其中有人在框架中,哪些地方在框架中有物体(例如散热器或狗);哪些地方什么都没有。

数据预处理
我们为训练模型而对数据进行预处理的方法与我们处理来自上述摄像头的实时信息的方法类似,只是数据源是包含温度值的文本文件。我们编写了一个 python 脚本来遍历所有这些文件并将它们输出为图像。在将温度转换为图像时,我们需要有一个最小值和最大值来分配给颜色范围。为了找到这些最小值、最大值,我们在约 400 个温度阵列的数据集中找到了最低和最高温度。
创建模型
使用 Edge Impulse,我们上传了带有适当标签“人员”和“无人”的收集数据,并允许数据在训练和测试之间自动拆分。对于脉冲设计,我们尝试了处理和学习模块的不同组合(例如图像和神经网络 (Keras)),但我们发现使用我们的数据,图像处理模块和迁移学习学习模块的性能最好。
我们使用 RGB 作为颜色深度参数,然后生成特征。
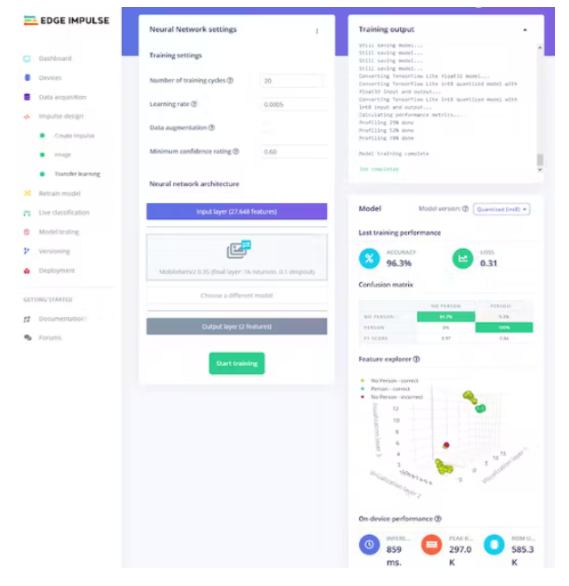
我们将训练周期数设置为 20,学习率为 0.0005,并将最小置信度设置为 0.6。
我们将冲动部署为具有默认优化的 WebAssembly 库。
模型运行
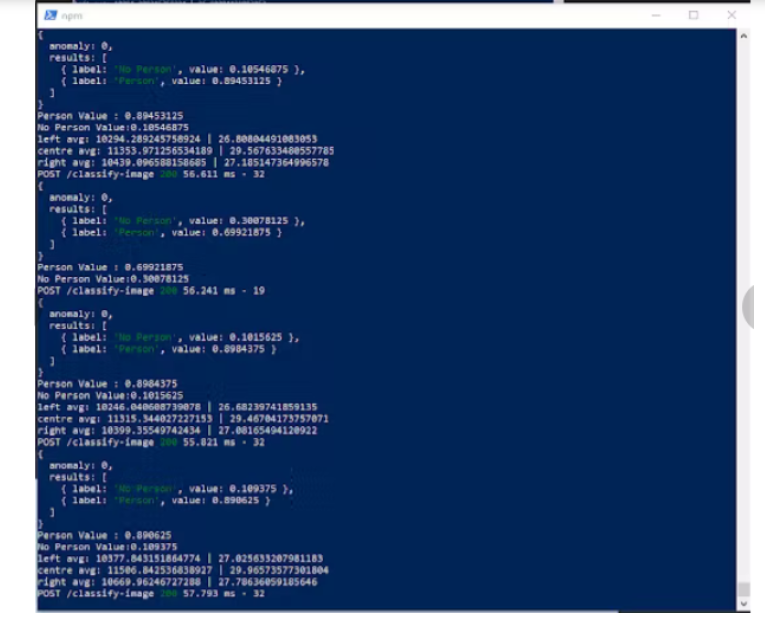
该模型运行良好,但存在一些问题,因为它偶尔会输出误报和漏报。下面是当有人直接坐在 MLX 前面并且模型正确识别出他们位于框架中心时,在我们的节点 js 服务器和 Pi 上的 Python 代码中运行的模型输出的一些屏幕截图:
未来的可能
改进的热成像相机
虽然 MLX 对家庭爱好者来说是一款出色的 TIC,但我们认为它在帮助消防员拯救生命方面并不能胜任。此处可见的像 FLIR K53 这样的“高性能”TIC具有令人印象深刻的 320x240 分辨率(与 MLX 的 768 相比,总像素为 76800)和 60 Hz 的刷新率。更复杂的 TIC(具有更高的分辨率和刷新率)将使模型更容易准确地检测人体形状,并且有必要将这个项目变成产品。
模型的进一步训练
我们还认为需要一个更复杂的模型才能将这个项目变成一个产品。该项目的下一步将是开发一个模型,该模型可以检测同一帧中的多个人,并且不仅输出是否在帧中检测到一个人,还输出他们在帧中的位置。该模型应根据 x 轴和 y 轴给出位置。如果可能,应传达有关人员与摄像机的距离的信息,甚至是有关人员“可见”程度的信息(例如,如果仅检测到手臂,则模型应传达人员“部分可见”是由于障碍物,例如床或瓦砾)。
对于这个项目,我们有一个非常简单的触觉语言,它只需要传达关于三个位置的信息。展望未来,随着模型输出更多信息,需要设计更精细的触觉语言。这可以与位于消防员身体上的更大阵列的执行器一起使用,以促进更丰富的时空扫描。最终产品可能旨在让消防员穿着触觉袖子或背心,而不是一个 Buzz。
-
MLX90640红外热成像仪测温传感器模块PC端操作教程2022-08-12 4827
-
【正点原子STM32H7R3开发套件试用体验】+MLX90640热成像2024-12-17 1272
-
MLX90640新型红外传感器的特点及应用 查看附件规格书2019-10-11 4245
-
RK3288 android7.1 mlx90640温度传感器的驱动调试过程是怎样的?2022-03-03 1478
-
RK3288 mlx90640的驱动开发描述2022-05-16 3137
-
MLX90640在利用IIC读取数据时,读取的数据都是FF的原因?2023-10-24 795
-
MLX90640新型红外传感器的特点及应用2019-05-13 32432
-
基于热电堆的远红外热传感器阵列MLX90640芯片解析2019-09-29 11445
-
远红外热传感器阵列MLX90640的特性和优势分析2019-10-08 7038
-
MLX90640红外阵列传感器的驱动库API免费下载2019-10-12 2490
-
微雪电子MLX90640红外热像仪模块简介2020-01-02 15094
-
MLX90640像素热红外阵列数据手册免费下载2020-01-06 1949
-
MLX90640驱动程序和驱动说明文档免费下载2020-04-02 1006
-
MLX90640红外热成像仪测温模块开发笔记(四)2022-07-22 2215
-
如何利用RT-Thread去开发一种MLX90640热成像仪?2023-08-07 1591
全部0条评论

快来发表一下你的评论吧 !
