

使用NVIDIA Triton模型分析器确定最佳AI模型服务配置
描述
模型部署是 机器学习 生命周期的一个关键阶段,在此阶段,经过培训的模型将集成到现有的应用程序生态系统中。这往往是最繁琐的步骤之一,在这些步骤中,目标硬件平台应满足各种应用程序和生态系统约束,所有这些都不会影响模型的准确性。
NVIDIA Triton 推理服务器 是一个开源的模型服务工具,它简化了推理,并具有多个功能以最大限度地提高硬件利用率和推理性能。这包括以下功能:
并发模型执行 ,使同一模型的多个实例能够在同一系统上并行执行。
Dynamic batching ,其中客户端请求在服务器上分组,以形成更大的批。
优化模型部署时,需要做出几个关键决策:
为了最大限度地提高利用率, NVIDIA Triton 应在同一 CPU / GPU 上同时运行多少个模型实例?
应将多少传入的客户端请求动态批处理在一起?
模型应采用哪种格式?
应以何种精度计算输出?
这些关键决策导致了组合爆炸,每种型号和硬件选择都有数百种可能的配置。通常,这会导致浪费开发时间或代价高昂的低于标准的服务决策。
在本文中,我们将探讨 NVIDIA Triton 型号分析仪 可以自动浏览目标硬件平台的各种服务配置,并根据应用程序的需要找到最佳型号配置。这可以提高开发人员的生产率,同时提高服务硬件的利用率。
NVIDIA Triton 型号分析仪
NVIDIA Triton Model Analyzer 是一个多功能 CLI 工具,有助于更好地了解通过 NVIDIA Triton 推理服务器提供服务的模型的计算和内存需求。这使您能够描述不同配置之间的权衡,并为您的用例选择最佳配置。
NVIDIA Triton 模型分析器可用于 NVIDIA Triton 推理服务器支持的所有模型格式: TensorRT 、 TensorFlow 、 PyTorch 、 ONNX 、 OpenVINO 和其他。
您可以指定应用程序约束(延迟、吞吐量或内存),以找到满足这些约束的服务配置。例如,虚拟助理应用程序可能有一定的延迟预算,以便最终用户能够实时感受到交互。脱机处理工作流应针对吞吐量进行优化,以减少所需硬件的数量,并尽可能降低成本。模型服务硬件中的可用内存可能受到限制,并且需要针对内存优化服务配置。
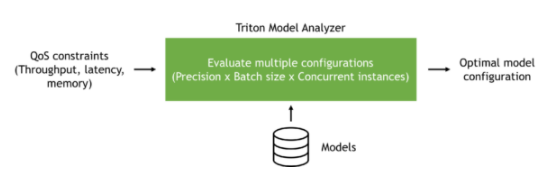
图 1 :NVIDIA Triton 型号分析器概述。
我们以一个预训练模型为例,展示了如何使用 NVIDIA Triton 模型分析器,并在 Google 云平台上的 VM 实例上优化该模型的服务。然而,这里显示的步骤可以在任何公共云上使用,也可以在具有 NVIDIA Triton 推理服务器支持的任何模型类型的前提下使用。
创建模型
在这篇文章中,我们使用预训练 BERT Hugging Face 的大型模型,采用 PyTorch 格式。 NVIDIA Triton 推理服务器可以使用其LibTorch后端为TorchScript模型提供服务,也可以使用其 Python 后端为纯 PyTorch 模型提供服务。为了获得最佳性能,我们建议将 PyTorch 模型转换为TorchScript格式。为此,请使用PyTorch的跟踪功能。
首先从 NGC 中拉出 PyTorch 容器,然后在容器中安装transformers包。如果这是您第一次使用 NGC ,请创建一个帐户。在本文中,我们使用了 22.04 版本的相关工具,这是撰写本文时的最新版本。 NVIDIA ( NVIDIA ) Triton 每月发布一次 cadence ,并在每个月底发布新版本。
docker pull nvcr.io/nvidia/pytorch:22.04-py3 docker run --rm -it -v $(pwd):/workspace nvcr.io/nvidia/pytorch:22.04-py3 /bin/bash pip install transformers
安装transformers包后,运行以下 Python 代码下载预训练的 BERT 大型模型,并将其跟踪为 TorchScript 格式。
from transformers import BertModel, BertTokenizer
import torch
model_name = "bert-large-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, torchscript=True) max_seq_len = 512
sample = "This is a sample input text"
tokenized = tokenizer(sample, return_tensors="pt", max_length=max_seq_len, padding="max_length", truncation=True) inputs = (tokenized.data['input_ids'], tokenized.data['attention_mask'], tokenized.data['token_type_ids'])
traced_model = torch.jit.trace(model, inputs)
traced_model.save("model.pt")
构建模型存储库
使用 NVIDIA Triton 推理服务器为您的模型提供服务的第一步是创建模型存储库。在此存储库中,您将包括一个模型配置文件,该文件提供有关模型的信息。模型配置文件至少必须指定后端、模型的最大批大小以及输入/输出结构。
对于这个模型,下面的代码示例是模型配置文件。
platform: "pytorch_libtorch"
max_batch_size: 64
input [ { name: "INPUT__0" data_type: TYPE_INT64 dims: [ 512 ] }, { name: "INPUT__1" data_type: TYPE_INT64 dims: [ 512 ] }, { name: "INPUT__2" data_type: TYPE_INT64 dims: [ 512 ] }
]
output [ { name: "OUTPUT__0" data_type: TYPE_FP32 dims: [ -1, 1024 ] }, { name: "OUTPUT__1" data_type: TYPE_FP32 dims: [ 1024 ] }
]
将模型配置文件命名为config.pbtxt后,按照 存储库布局结构 创建模型存储库。模型存储库的文件夹结构应类似于以下内容:
. └── bert-large ├── 1 │ └── model.pt └── config.pbtxt
运行 NVIDIA Triton 型号分析器
建议使用 Model Analyzer 的方法是自己构建 Docker 映像:
git clone https://github.com/triton-inference-server/model_analyzer.git cd ./model_analyzer git checkout r22.04 docker build --pull -t model-analyzer .
现在已经构建了 Model Analyzer 映像,请旋转容器:
docker run -it --rm --gpus all \ -v /var/run/docker.sock:/var/run/docker.sock \ -v:/models \ -v :/output \ -v :/config \ --net=host model-analyzer
不同的硬件配置可能会导致不同的最佳服务配置。因此,在最终提供模型的目标硬件平台上运行模型分析器非常重要。
为了重现我们在这篇文章中给出的结果,我们在公共云中进行了实验。具体来说,我们在 Google 云平台上使用了一个 a2-highgpu-1g 实例,并使用了一个 NVIDIA A100 GPU 。
A100 GPU 支持多实例 GPU ( MIG ),它可以通过将单个 A100 GPU 拆分为七个分区来最大限度地提高 GPU 利用率,这些分区具有硬件级隔离,可以独立运行 NVIDIA Triton 服务器。为了简单起见,我们在这篇文章中没有使用 MIG 。
Model Analyzer 支持 NVIDIA Triton 型号的自动和手动扫描不同配置。自动配置搜索是默认行为,并为所有配置启用 dynamic batching 。在这种模式下,模型分析器将扫描不同的批大小和可以同时处理传入请求的模型实例数。
扫掠的默认范围是最多五个模型实例和最多 128 个批次大小。这些 可以更改默认值 。
现在创建一个名为sweep.yaml的配置文件,以分析前面准备的 BERT 大型模型,并自动扫描可能的配置。
model_repository: /models checkpoint_directory: /output/checkpoints/ output-model-repository-path: /output/bert-large profile_models: bert-large perf_analyzer_flags: input-data: "zero"
使用前面的配置,您可以分别获得模型吞吐量和延迟的顶行号和底行号。
分析时,模型分析器还将收集的测量值写入检查点文件。它们位于指定的检查点目录中。您可以使用分析的检查点创建数据表、摘要和结果的详细报告。
配置文件就绪后,您现在可以运行 Model Analyzer 了:
model-analyzer profile -f /config/sweep.yaml
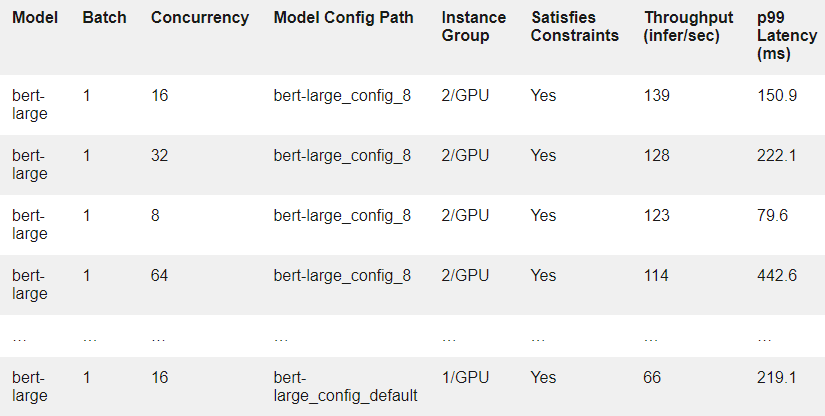
作为示例,表 1 显示了结果中的几行。每一行对应于在假设的客户端负载下在模型配置上运行的实验。
要获得测试的每个模型配置的更详细报告,请使用model-analyzer report命令:
model-analyzer report --report-model-configs bert-large_config_default,bert-large_config_1,bert-large_config_2 --export-path /output --config-file /config/sweep.yaml --checkpoint-directory /output/checkpoints/
这将生成一个详细说明以下内容的报告:
运行分析的硬件
吞吐量与延迟的关系图
GPU 内存与延迟的关系图
CLI 中所选配置的报告
对于任何 MLOps 团队来说,在将模型投入生产之前开始分析都是一个很好的开始。
不同的利益相关者,不同的约束条件
在典型的生产环境中,有多个团队应该协同工作,以便在生产中大规模部署 AI 模型。例如,可能有一个 MLOps 团队负责为管道稳定性服务的模型,并处理应用程序强加的服务级别协议( SLA )中的更改。另外,基础架构团队通常负责整个 GPU / CPU 场。
假设一个产品团队要求 MLOps 团队在 30 毫秒的延迟预算内处理 99% 的请求,为 BERT 大型服务器提供服务。 MLOps 团队应考虑可用硬件上的各种服务配置,以满足该要求。使用 Model Analyzer 可以消除执行此操作时的大部分摩擦。
下面的代码示例是一个名为latency_constraint.yaml的配置文件的示例,其中我们在测得的延迟值的 99% 上添加了一个约束,以满足给定的 SLA 。
model_repository: /models checkpoint_directory: /output/checkpoints/ analysis_models: bert-large: constraints: perf_latency_p99: max: 30 perf_analyzer_flags: input-data: "zero"
因为您有上一次扫描中的检查点,所以可以将它们重新用于 SLA 分析。运行以下命令可以提供满足延迟约束的前三种配置:
model-analyzer analyze -f latency_constraint.yaml
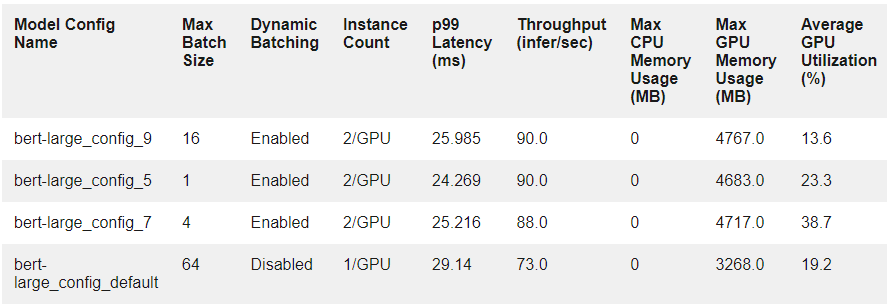
表 2 显示了前三种配置的测量结果,以及它们与默认配置的比较情况。

在大规模生产中,软件和硬件约束会影响生产中的 SLA 。
假设应用程序的约束已更改。该团队现在希望满足同一型号的 p99 延迟为 50 ms ,吞吐量为每秒 30 多个推断。还假设基础设施团队能够为其使用留出 5000 MB 的 GPU 内存。随着约束数量的增加,手动查找服务配置以满足涉众变得越来越困难。这就是对模型分析器这样的解决方案的需求变得更加明显的地方,因为您现在可以在单个配置文件中同时指定所有约束。
以下名为multiple_constraint.yaml的示例配置文件结合了吞吐量、延迟和 GPU 内存约束:
model_repository: /models checkpoint_directory: /output/checkpoints/ analysis_models: bert-large-pytorch: constraints: perf_throughput: min: 50 perf_latency_p99: max: 30 gpu_used_memory: max: 5000 perf_analyzer_flags: input-data: "zero"
使用此更新的约束,运行以下命令:
model-analyzer analyze -f multiple_constraint.yaml
Model Analyzer 现在将以下提供的服务配置作为前三个选项,并显示它们与默认配置的比较情况。

总结
随着企业发现自己在生产中提供越来越多的模型,手动或基于启发式做出模型服务决策变得越来越困难。手动执行此操作会导致浪费开发时间或模型服务决策不足,这需要自动化工具。
在本文中,我们探讨了 NVIDIA Triton 模型分析器如何能够找到满足应用程序 SLA 和各种涉众需求的模型服务配置。我们展示了如何使用模型分析器扫描各种配置,以及如何使用它来满足指定的服务约束。
尽管我们在这篇文章中只关注一个模型,但仍有计划让模型分析器同时对多个模型执行相同的分析。例如,您可以在相同的 GPU 上运行的不同模型上定义约束,并对每个约束进行优化。
我们希望您能分享我们对 Model Analyzer 将节省多少开发时间的兴奋,并使您的 MLOps 团队能够做出明智的决策。
关于作者
Arun Raman 是 NVIDIA 的高级解决方案架构师,专门从事消费互联网行业的 edge 、 cloud 和 on-prem 人工智能应用。在目前的职位上,他致力于端到端 AI 管道,包括预处理、培训和推理。除了从事人工智能工作外,他还研究了一系列产品,包括网络路由器和交换机、多云基础设施和服务。他拥有达拉斯德克萨斯大学电气工程硕士学位。
Burak Yoldeir 是 NVIDIA 的高级数据科学家,专门为消费互联网行业生产人工智能应用程序。除了前端和后端企业软件开发之外, Burak 还从事广泛的 AI 应用程序开发。他拥有加拿大不列颠哥伦比亚大学电气和计算机工程博士学位。
审核编辑:郭婷
-
NVIDIA 借助超大规模 AI 语言模型为全球企业赋能2021-11-10 1293
-
NVIDIA Triton推理服务器帮助Teams使用认知服务优化语音识别模型2022-01-04 2508
-
Microsoft使用NVIDIA Triton加速AI Transformer模型应用2022-04-02 2713
-
使用NVIDIA Triton推理服务器简化边缘AI模型部署2022-04-18 3797
-
基于NVIDIA Triton的AI模型高效部署实践2022-06-28 3244
-
NVIDIA Triton的概念、特性及主要功能2022-07-18 5497
-
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求2022-09-05 3564
-
NVIDIA Triton 系列文章(4):创建模型仓2022-11-15 2367
-
NVIDIA Triton 系列文章(9):为服务器添加模型2022-12-27 2837
-
NVIDIA Triton 系列文章(10):模型并发执行2023-01-05 2755
-
NVIDIA Triton 系列文章(11):模型类别与调度器-12023-01-11 2087
-
如何使用NVIDIA Triton 推理服务器来运行推理管道2023-07-05 2336
-
使用NVIDIA Triton推理服务器来加速AI预测2024-02-29 1943
-
NVIDIA助力提供多样、灵活的模型选择2024-09-09 1714
-
Triton编译器在机器学习中的应用2024-12-24 2144
全部0条评论

快来发表一下你的评论吧 !
