

使用NVIDIA DGX SuperPOD训练SOTA大规模视觉模型
描述
最近的研究表明,在语义分割和目标检测等计算机视觉任务中,大型 transformer 模型可以实现或提高 SOTA 。然而,与只能使用标准公共数据集的卷积网络模型不同,它需要一个更大的专有数据集。
VOLO 模型体系结构
新加坡 SEA AI 实验室最近的项目 VOLO ( Vision Outlooker )展示了一种高效且可扩展的 Vision transformer 模式体系结构,该体系结构仅使用 ImageNet-1K 数据集就大大缩小了差距。
VOLO 引入了一种新颖的 outlook attention ,并提出了一种简单而通用的架构,称为 Vision Outlooker 。与自我关注不同,自我关注侧重于粗略级别的全局依赖关系建模, outlook 关注有效地将更精细级别的功能和上下文编码为标记。这对识别性能极为有利,但在很大程度上被自我注意所忽视。
实验表明, VOLO 在 ImageNet-1K 分类上达到了 87.1% 的 top-1 精度,这是第一个在这个竞争基准上超过 87% 精度的模型,无需使用任何额外的训练数据。
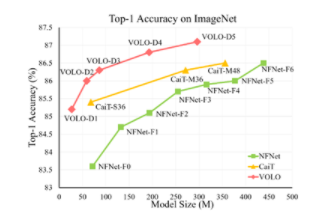
图 1 :不同尺寸级别的 VOLO 模型的 Top-1 精度
此外,经过预训练的 VOLO 可以很好地转移到下游任务,例如语义切分。
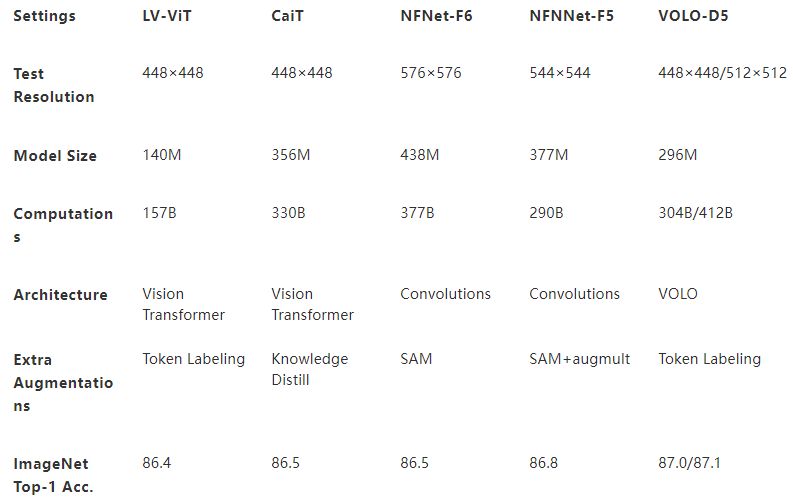
表 1 :对比 ViT 、 CNN 基线模型概述
尽管 VOLO 模型显示出了出色的计算效率,但训练 SOTA 性能模型并非易事。
在这篇文章中,我们将介绍我们在 NVIDIA DGX SuperPOD 上基于 NVIDIA ML 软件堆栈和 Infiniband 群集技术培训 VOLO 模型所获得的技术和经验。
培训方法
培训 VOLO 模型需要考虑培训策略、基础设施和配置规划。在本节中,我们将讨论此解决方案中应用的一些技术。
培训策略
始终使用原始 ImageNet 样本质量数据训练模型,并在细粒度上执行神经网络( NN )架构搜索,使理论上的研究更加巩固。然而,这需要计算资源预算的很大一部分。
在这个项目的范围内,我们采用了一种粗粒度的训练方法,它不像细粒度的方法那样能够访问尽可能多的神经网络体系结构。然而,它能够以更少的时间和更低的资源预算显示 EIOF 。在这种替代策略中,我们首先使用分辨率较低的图像样本训练潜在的神经网络候选,然后使用高分辨率图像进行微调。
在早期的工作中,这种方法在降低边际模型性能损失的计算成本方面被证明是有效的。
基础设施
实际上,我们在本次培训中使用了两种类型的集群:
一个用于基础模型预训练,它是一个基于 NVIDIA DGX A100 的 DGX 吊舱,由使用 NVIDIA Mellanox HDR Infiniband 网络集群的 5 个 NVIDIA DGX A100 系统组成。
一个用于微调,即 NVIDIA DGX SuperPOD ,由 DGX A100 系统和 NVIDIA Mellanox HDR Infiniband 网络组成。

图 2 :本项目使用的基于 NVIDIA 技术的软件栈
软件基础设施在这一过程中也发挥了重要作用。图 2 显示,除了基础的标准深度学习优化 CUDA 库(如 cuDNN 和 cuBLAS )外,我们还广泛利用 NCCL 、 enroot 、 PyXis 、 APEX 和 DALI 来实现培训性能的亚线性可扩展性。
DGX A100 POD 集群主要用于使用较小尺寸图像样本的基础模型预训练。这是因为基本模型预训练的内存限制较少,可以利用 NVIDIA A100 GPU 的计算能力优势。
相比之下,微调是在 NVIDIA DGX-2 的 NVIDIA DGX SuperPOD 上执行的,因为微调过程使用更大的图像,每台计算能力需要更多的内存。
培训配置
需要引入句子
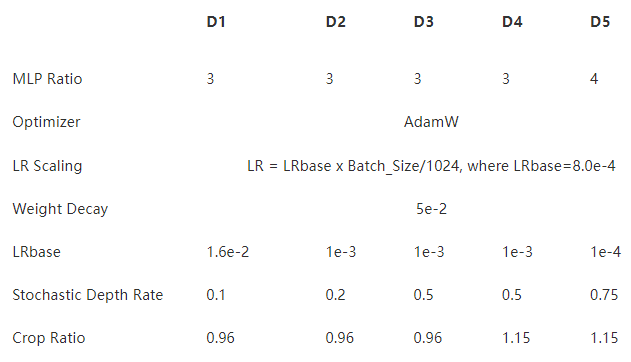
表 2 :模型设置(对于所有模型,批大小设置为 1024 )
我们在 ImageNet 数据集上评估了我们提出的 VOLO 模型。在培训期间,没有使用额外的培训数据。我们的代码基于 PyTorch 、令牌标记工具箱和 PyTorch 图像模型( timm )。我们使用带有标记的 LV-ViT-S 模型作为基线。
安装说明
我们使用了 AdamW 优化器和线性学习率缩放策略 LR = LR基础x Batch \ u 大小/ 1024 和 5 × 10 − 2 先前工作建议的重量衰减率,表 3 中给出了所有 VOLO 模型的 LRbase 。
使用随机深度。
我们在 ImageNet 数据集上训练了 300 个时代的模型。
对于数据扩充方法,我们使用 CutOut 、 RandAug 和 MixToken 的标记目标。
我们没有使用 MixUp 或 CutMix ,因为它们与 MixToken 冲突。
训练前
在本节中,我们以 VOLO-D5 为例来演示如何训练模型。
图 3 显示,使用单个 DGX A100 的 VOLO-D5 的训练吞吐量约为 500 图像/秒。据估计,完成一个完整的预训练周期大约需要 170 个小时,这需要使用 ImageNet-1K 进行 300 个阶段。这相当于 100 万张图片的一周。
为了加快速度,基于一个由五个 DGX A100 节点组成的简单参数服务器架构集群,我们大致实现了 2100 个图像/秒的吞吐量,这可以将预训练时间减少到约 52 小时。
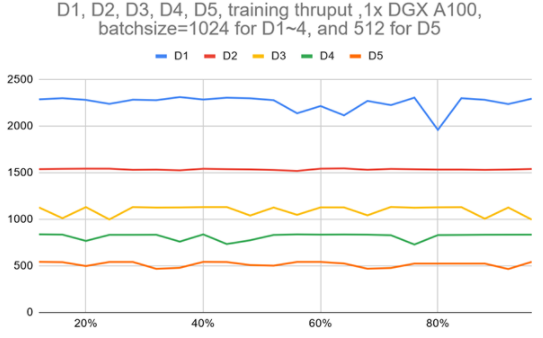
图 3 :D1 ~ D5 模型在一个 DGX A100 上跨一个完整历元的训练吞吐量
VOLO-D5 模型预训练可以使用以下代码示例在单个节点上启动:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet \ --model volo_d5 --img-size 224 \ -b 44 --lr 1.0e-4 --drop-path 0.75 --apex-amp \ --token-label --token-label-size 14 --token-label-data /path/to/token_label_data
对于 MNMG 培训案例,它需要将培训集群详细信息作为命令行输入的一部分。首先,我们根据节点和集群架构设置 CPU 、 MEM 、 IB 绑定。预训练阶段的集群是 DGX A100 POD ,每个 CPU 插槽有四个 NUMA 域,每个 A100 GPU 有一个 IB 端口,因此我们将每个列组绑定到 NUMA 节点中距离其 GPU 最近的所有 CPU 核。
对于内存绑定,我们将每个列组绑定到最近的 NUMA 节点。
对于 IB 绑定,我们为每个 GPU 绑定一个 IB 卡,或者尽可能接近这样的设置。
由于 VOLO 模型培训基于 PyTorch ,并且简单地利用了默认的 PyTorch 分布式培训方法,因此我们的多节点多 GPU 培训基于一个简单的参数服务器架构,该架构适合 NVIDIA DGX SuperPOD 的 fat 树网络拓扑。
为了简化调度,分配节点列表中的第一个节点始终用作参数服务器和工作节点,而所有其他节点都是工作节点。为了避免潜在的存储 I / O 开销,数据集、所有代码、中间/里程碑检查点和结果都保存在一个基于 DDN 的高性能分布式存储后端。它们通过 100G NVIDIA Mellanox EDR Infiniband 网络装载到所有工作节点。
为了加速数据预处理和流水线数据加载, NVIDIA DALI 配置为每个 GPU 进程使用一个专用数据加载程序。
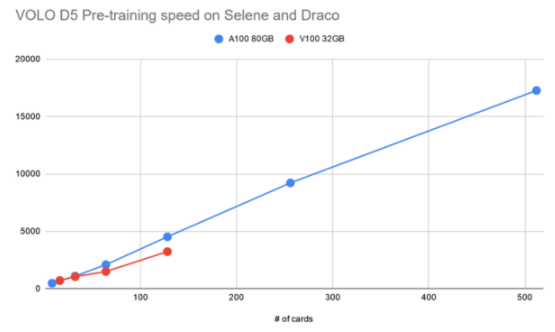
图 4 :训练前阶段训练吞吐量相对于 A100 和 V100 的速度提高 GPU
微调
使用以下代码示例,在单个节点上运行 VOLO-D5 模型微调非常简单:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet \ --model volo_d5 --img-size 512 \ -b 4 --lr 2.3e-5 --drop-path 0.5 --apex-amp --epochs 30 \ --weight-decay 1.0e-8 --warmup-epochs 5 --ground-truth \ --token-label --token-label-size 24 --token-label-data /path/to/token_label_data \ --finetune /path/to/pretrained_224_volo_d5/
如前所述,由于用于微调的图像大小远远大于预训练阶段使用的图像大小,因此必须相应地减小批量大小。将工作负载放入 GPU 内存中,这使得进一步扩展训练到更大数量的 GPU 并行任务是必须的。
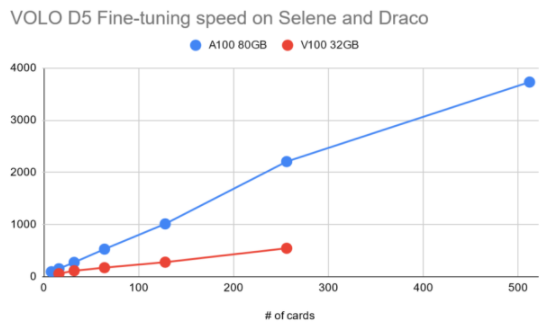
图 5 :针对 A100 和 V100 的数量提高微调阶段训练吞吐量 GPU
大多数微调配置类似于预训练阶段。
结论
在这篇文章中,我们展示了在大规模人工智能超级计算机上训练 SOTA 大规模视觉 transformer 模型(如 VOLO \ u D5 )的主要技术和程序,如基于 NVIDIA DGX A100 的 DGX SuperPOD 。经过训练的 VOLO \ u D5 模型在图像分类模型排名中取得了最佳的 Top-1 精度,无需使用 ImageNet-1k 数据集以外的任何其他数据。
这项工作的代码资源(包括用于运行实验的 Docker 映像和 Slurm 调度程序脚本)在 sail-sg/volo GitHub repo 中是开源的,以便将来可以在 VOLO \ u D5 上进行更广泛的研究。
未来,我们希望进一步扩展这项工作,以培训更智能、自我监督、更大规模的模型,使用更大的公共数据集和更现代化的基础设施,例如, NVIDIA DGX SuperPOD 和 NVIDIA H100 GPU。
关于作者
Terry Yin 目前是 NVIDIA AI 技术中心的高级深度学习解决方案架构师。他分别于 2009 年和 2012 年在中国华南理工大学和韩国延世大学获得学士和硕士学位。 2012 年至 2016 年,他是南洋理工大学新加坡分校的研究员,期间他获得了东盟 ICT 金奖、数据中心动态奖、 ACM SIGCOMM 2013 年旅游奖和 GTC 2015 年演讲者奖。他的研究兴趣包括云计算系统、深度学习系统、高性能计算系统等。
Yuan Lin 是 NVIDIA 编译团队的首席工程师。他对所有使程序更高效、编程更高效的技术感兴趣。在加入 NVIDIA 之前,他是 Sun Microsystems 的一名高级职员工程师。
审核编辑:郭婷
-
NVIDIA DGX SuperPOD为Rubin平台横向扩展提供蓝图2026-01-14 1256
-
Cadence 借助 NVIDIA DGX SuperPOD 模型扩展数字孪生平台库,加速 AI 数据中心部署与运营2025-09-15 1858
-
NVIDIA推出搭载GB200 Grace Blackwell超级芯片的NVIDIA DGX SuperPOD™2024-03-21 2399
-
NVIDIA 推出 Blackwell 架构 DGX SuperPOD,适用于万亿参数级的生成式 AI 超级计算2024-03-19 1332
-
NVIDIA DGX SuperPOD 助力京东探索研究院 Vega-MT 模型大赛夺魁!2023-01-18 1305
-
KT利用NVIDIA AI平台训练大型语言模型2022-09-27 2518
-
NVIDIA联合构建大规模模拟和训练 AI 模型2022-06-14 2750
-
DGX SuperPOD助力助力织女模型的高效训练2022-04-13 1790
-
NVIDIA DGX SuperPOD 方案满足服务大模型的计算需求2022-01-04 2747
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2554
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4237
-
如何向大规模预训练语言模型中融入知识?2021-06-23 6415
全部0条评论

快来发表一下你的评论吧 !
