

VMware在vSphere上验证Alveo FPGA性能
描述
硬件加速器已经在数据中心变得司空见惯,大量新的工作负载已经成熟,可以利用 FPGA 加速的优势及其更高的计算效率。对机器学习 (ML) 的快速增长的兴趣正在推动在私有、公共和混合云数据中心环境中越来越多地采用 FPGA 加速器来加速这种计算密集型工作负载。作为促进 IT 基础架构向异构计算转型的一部分,我们最近与 VMware 合作在 vSphere上测试 FPGA 加速,VMware的云计算虚拟化平台。鉴于赛灵思 FPGA 越来越多地用于 ML 推理加速,我们将展示如何将赛灵思 FPGA 与 VMware vSphere 结合使用,以实现虚拟和裸机部署之间几乎相同的高吞吐量和低延迟 ML 推理性能。
自适应计算优势
FPGA 是自适应计算设备,可提供重新编程的灵活性以满足所需应用程序的不同处理和功能要求。这一特性将 FPGA 与 GPU 和 ASIC 等固定架构区分开来——更不用说定制 ASIC 飞涨的成本了。此外,与其他硬件加速器相比,FPGA 在实现高能效和低延迟方面也具有优势,这使得 FPGA 特别适用于 ML 推理任务。与 GPU 从根本上依赖大量并行处理内核来实现高吞吐量不同,FPGA 可以通过定制的硬件内核、数据流管道和互连同时实现 ML 推理的高吞吐量和低延迟。
在 vSphere 上使用 Xilinx FPGA 进行 ML 推理
VMware 在他们的实验室中使用 Xilinx Alveo U250 数据中心卡 进行测试。使用 Vitis AI中提供的 Docker 容器快速配置 ML 模型, Vitis AI是 Xilinx 统一开发堆栈,用于在 Xilinx 硬件平台上从 Edge 到 Cloud 进行 ML 推理。它由优化的工具、库、模型和示例组成。Vitis AI 支持主流框架,包括 Caffe 和 TensorFlow,以及能够执行各种深度学习任务的最新模型。此外,Vitis AI 是开源的,可以在 GitHub 上访问。
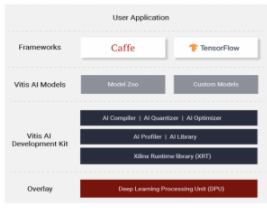
Vitis AI 软件堆栈
目前,Xilinx FPGA 可以通过 DirectPath I/O 模式(直通)在 vSphere 上启用。通过这种方式,我们的 FPGA 可以被运行在 VM 中的应用程序直接访问,绕过虚拟机管理程序层,从而最大限度地提高性能并最大限度地减少延迟。在 DirectPath I/O 模式下配置 FPGA 是一个简单的两步过程:首先,在主机级别启用 ESXi 上的设备,然后将设备添加到目标 VM。详细说明可在此 VMware 知识库文章中找到。请注意,如果您运行的是 vSphere 7,则不再需要重新引导主机。
高吞吐量、低延迟的机器学习推理性能
VMware 与 Xilinx 一起通过使用四个 CNN 模型运行推理来评估我们的 Alveo U250 加速卡在 DirectPath I/O 模式下的吞吐量和延迟性能:Inception_v1;初始_v2;资源网50;和 VGG16。这些模型的模型参数数量不同,因此具有不同的处理复杂性。
测试使用了配备两个 10 核 Intel Xeon Silver 4114 CPU 和 192 GB DDR4 内存的 Dell PowerEdge R740 服务器。我们使用了 ESXi 7.0 管理程序,并将每个模型的端到端性能结果与作为基准的裸机进行了比较。Ubuntu 16.04(内核 4.4.0-116)用作来宾操作系统和本机操作系统。此外,Vitis AI v1.1 和 Docker CE 19.03.4 用于整个测试。使用从 ImageNet2012 派生的 50k 图像数据集,为了进一步避免读取图像的磁盘瓶颈,创建了一个 RAM 磁盘并用于存储 50k 图像。
通过这些设置,虚拟和裸机测试之间的性能比较可以在以下两张图中查看,一张用于吞吐量,另一张用于延迟。y 轴是虚拟机和裸机之间的比率,y=1.0 表示虚拟机和裸机的性能相同。
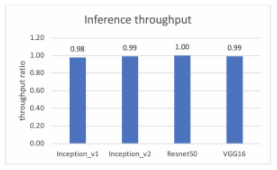
Xilinx Alveo U250 FPGA 机器学习推理的裸机和虚拟机吞吐量性能比较
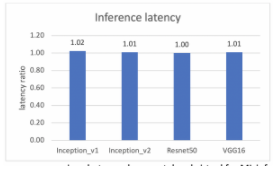
Xilinx Alveo U250 FPGA 机器学习推理的裸机和虚拟机延迟性能比较
测试验证了虚拟机和裸机之间的性能差距上限为 2%,无论是吞吐量还是延迟。这表明在虚拟环境中用于 ML 推理的 vSphere 上的 Alveo U250 的性能几乎与裸机基准相同。
云中的 FPGA 性能
FPGA 加速器在数据中心的采用正变得越来越普遍,并将继续增加以满足对异构计算和性能提升的日益增长的需求。我们很高兴与 VMware 合作,以确保客户能够充分利用 vSphere 平台上的 Xilinx FPGA 加速。我们的 Alveo U250 加速器在 vSphere for ML inference 上的测试成功地向客户展示了通过 DirectPath I/O 模式实现的接近原生的性能。审核编辑:郭婷
-
59/5000 Revit on VMware vSphere Horizon NVIDIA GRID vGPU基准测试2018-09-04 0
-
无法使用vCenter拍摄VMware快照2018-09-12 0
-
怎么获得与VMware vSphere 6.5兼容的Tesla M60 .vib文件/驱动程序?2018-09-27 0
-
GRID 3.0使用M60 GPU在ESXI 6.0.2上成功安装但无法通过nvidia-smi进行验证2018-09-27 0
-
vSphere内存预留上的GRID2018-10-09 0
-
vSphere 6.0 U2 gpumodeswitch失败2018-10-09 0
-
VMware改进vSAN,升级vSphere2018-04-20 3581
-
VMware-vSphere开发配置和VMware-SDK开发环境的资料说明2019-03-01 1076
-
赛灵思FPGA与VMware vSphere相结合实现高吞吐量、低时延ML推断性能2020-09-29 3125
-
搭载NVIDIA DPU的VMware vSphere 8面世2022-09-01 1723
-
使用NVIDIA LaunchPad直接访问VMware的vSphere2022-10-11 527
-
VMware vSphere 6.0 U2上通过32GB光纤通道的存储I/O性能2023-08-16 117
-
VMware vSphere 6.0 U2上的存储I/O性能超过32Gb光纤通道2023-08-21 189
-
使用日立部署VMware vSphere虚拟存储平台IBM x3550 M4服务器和锦网络在可伸缩的环境中2023-08-28 131
-
日立统一计算平台VMware vSphere Pro2023-08-30 163
全部0条评论

快来发表一下你的评论吧 !
