

KITTI 3D检测数据集
描述

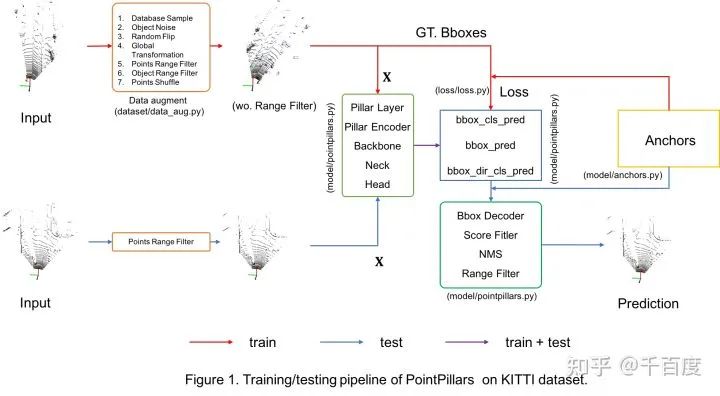
基于Lidar的object检测模型包括Point-based [PointRCNN(CVPR19), IA-SSD(CVPR22)等], Voxel-based [PointPillars(CVPR19), CenterPoint(CVPR21)等],Point-Voxel-based [PV-RCNN(CVPR20), HVPR(CVPR21)等]和Multi-view-based[PIXOR(CVPR18)等]等。本博客主要记录,作为菜鸟的我,在KITTI数据集上(3类)基于PyTorch实现PointPillars的一些学习心得, 训练和测试的pipeline如Figure 1所示。这里按照深度学习算法的流程进行展开: 数据 + 网络结构 + 预测/可视化 + 评估,和实现的代码结构是一一对应的,完整代码已更新于github//github.com/zhulf0804/PointPillars
[说明 - 代码的实现是通过阅读mmdet3dv0.18.1源码, 加上自己的理解完成的。因为不会写cuda, 所以cuda代码和少量代码是从mmdet3dv0.18.1复制过来的。]
一、KITTI 3D检测数据集
1.1 数据集信息:
·KITTI数据集论文: Are we ready for autonomous driving? the kitti vision benchmark suite [CVPR 2012] 和 Vision meets robotics: The kitti dataset [IJRR 2013]·KITTI数据集下载(下载前需要登录): point cloud(velodyne, 29GB), images(image_2, 12 GB), calibration files(calib, 16 MB)和labels(label_2, 5 MB)。数据velodyne, calib 和 label_2的读取详见utils/io.py。1.2 ground truth label信息 [file]
对每一帧点云数据, label是 n个15维的向量, 组成了8个维度的信息。
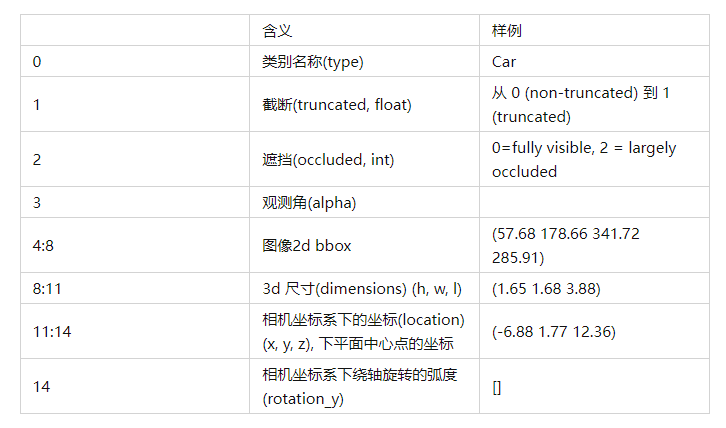
1)训练时主要用到的是类别信息(type) 和3d bbox 信息 (location, dimension, rotation_y).2)观测角(alpha)和旋转角(rotation_y)的区别和联系可以参考博客blog.csdn.net/qq_161375。
1.3 坐标系的变换
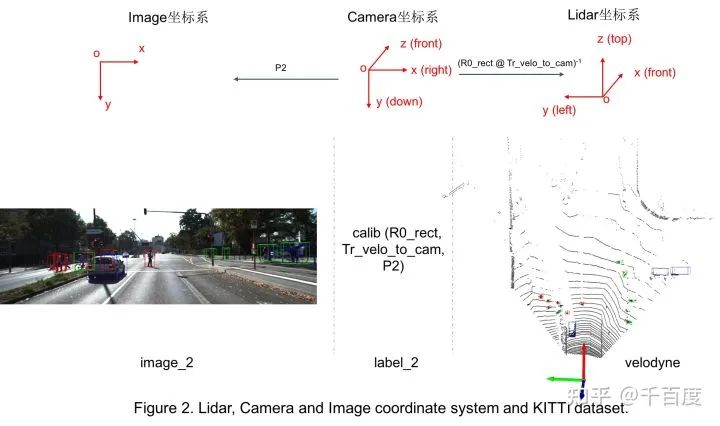
因为gt label中提供的bbox信息是Camera坐标系的,因此在训练时需要使用外参等将其转换到Lidar坐标系; 有时想要把3d bbox映射到图像中的2d bbox方便可视化,此时需要内参。具体转换关系如Figure 2。坐标系转换的代码见utils/process.py。
1.4 数据增强
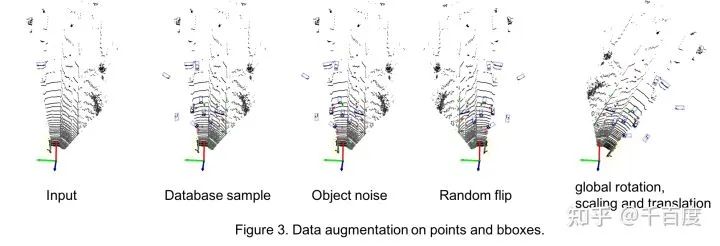
数据增强应该是Lidar检测中很重要的一环。发现其与2D检测中的增强差别较大,比如3D中会做database sampling(我理解的是把gt bbox进行cut-paste), 会做碰撞检测等。在本库中主要使用了采用了5种数据增强, 相关代码在dataset/data_aug.py。-
采样gt bbox并将其复制到当前帧的点云
- 从Car, Pedestrian, Cyclist的database数据集中随机采集一定数量的bbox及inside points, 使每类bboxes的数量分别达到15, 10, 10.
- 将这些采样的bboxes进行碰撞检测, 通过碰撞检测的bboxes和对应labels加到gt_bboxes_3d, gt_labels
- 把位于这些采样bboxes内点删除掉, 替换成bboxes内部的点.
-
bbox 随机旋转平移
- 以某个bbox为例, 随机产生num_try个平移向量t和旋转角度r, 旋转角度可以转成旋转矩阵(mat).
- 对bbox进行旋转和平移, 找到num_try中第一个通过碰撞测试的平移向量t和旋转角度r(mat).
- 对bbox内部的点进行旋转和平移.
- 对bbox进行旋转和平移.
-
随机水平翻转
- points水平翻转
- bboxes水平翻转
-
整体旋转/平移/缩放
- object旋转, 缩放和平移
- point旋转, 缩放和平移
- 对points进行shuffle: 打乱点云数据中points的顺序。
二、网络结构与训练


2.2 GT值生成
Head的3个分支基于anchor分别预测了类别, bbox框(相对于anchor的偏移量和尺寸比)和旋转角度的类别, 那么在训练时, 如何得到每一个anchor对应的GT值呢 ? 相关代码见model/anchors.py


2.3 损失函数和训练
现在知道了类别分类head, bbox回归head和朝向分类head的预测值和GT值, 接下来介绍损失函数。相关代码见loss/loss.py。

总loss = 1.0*类别分类loss + 2.0*回归loss + 2.0*朝向分类loss。模型训练: 优化器
torch.optim.AdamW(), 学习率的调整torch.optim.lr_scheduler.OneCycleLR(); 模型共训练160epoches。三、单帧预测和可视化
基于Head的预测值和anchors, 如何得到最后的候选框呢 ? 相关代码见model/pointpillars.py。一般经过以下几个步骤:基于预测的类别分数的scores, 选出nms_pre (100) 个anchors: 每一个anchor具有3个scores, 分别对应属于每一类的概率, 这里选择这3个scores中最大值作为该anchor的score; 根据每个anchor的score降序排序, 选择anchors。

3. 逐类进行以下操作:
- 过滤掉类别score 小于 score_thr (0.1) 的bboxes
- 基于nms_thr (0.01), nms过滤掉重叠框:

另外, 基于Open3d实现了在Lidar和Image里3d bboxes的可视化, 相关代码见
test.py和utils/vis_o3d.py。下图是对验证集中id=000134的数据进行可视化的结果。
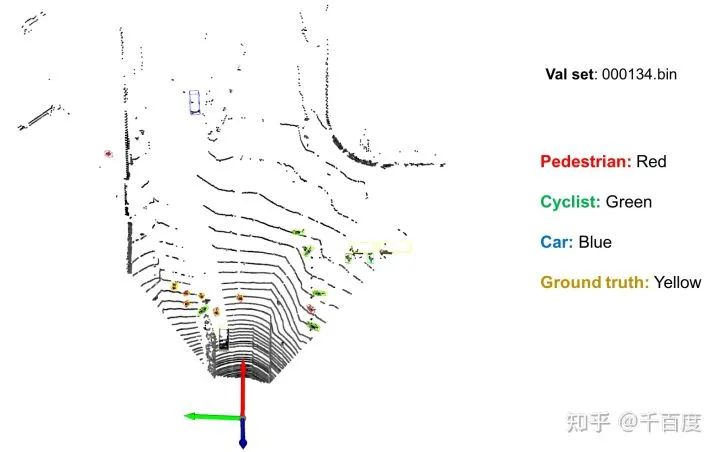

四、模型评估
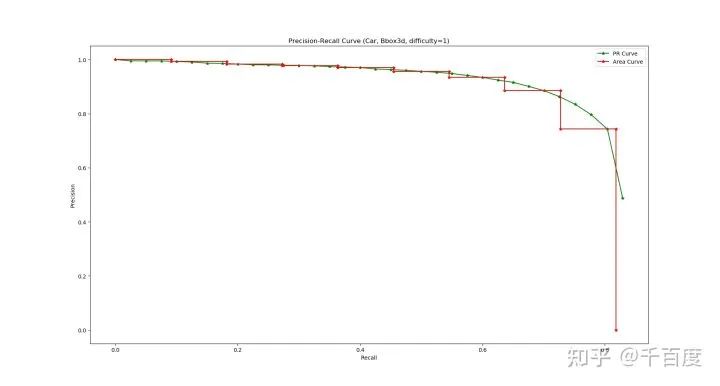
评估指标同2D检测类似, 也是采用AP, 即Precison-Recall曲线下的面积。不同的是, 在3D中可以计算3D bbox, BEV bbox 和 (2D bbox, AOS)的AP。先说明一下AOS指标和Difficulty的定义。
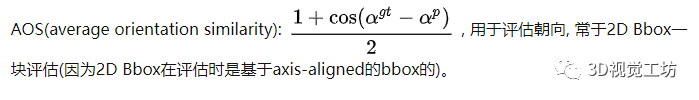
Difficulty: 根据2d框的高度, 遮挡程度和截断程度, 把bbox分为 difficulty=0, 1, 2 或 其它。相关定义具体查看代码
pre_process_kitti.py#L16-32。这里以3D bbox为例, 介绍类别=Car, difficulty=1 AP的计算。注意, difficulty=1的数据实际上是指difficulty<=1的数据; 另外这里主要介绍大致步骤, 具体实现见evaluate.py。1.计算3D IoU (utils/process.py iou3d(bboxes1, bboxes2)), 用于判定一个det bbox是否和gt bbox匹配上 (IoU > 0.7)。2.根据类别=Car, difficulty=1选择gt bboxes和det bboxes。-
gt bboxes: 选择
类别=Car,difficulty<=1的bboxes; -
det bboxes: 选择
预测类别=Car的bboxes。

五、总结点云检测, 相比于点云中其它任务(分类, 分割和配准等), 逻辑和代码都更加复杂, 但这并不是体现在网络结构上, 更多的是体现在数据增强, Anchors和GT生成, 单帧推理等。点云检测, 相比于2D图像检测任务, 不同的是坐标系变换, 数据增强(碰撞检测, 点是否在立方体判断等), 斜长方体框IoU的计算等; 评估方式因为考虑到DontCare, difficulty等, 也更加复杂一些.初次接触基于KITTI的3D检测, 如有理解错误的, 还请指正; 内容太多了, 如有遗漏, 待以后补充。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
3D检测系统可检测PCB板针脚高度2016-01-05 5613
-
基于ToF的3D活体检测算法研究2021-01-06 3299
-
浩辰3D的「3D打印」你会用吗?3D打印教程2021-05-27 8364
-
什么是3D now2010-01-22 1182
-
无人驾驶数据集你只知道Kitti吗?而实际比你想象的多2019-04-22 22667
-
谷歌开发pipeline,在移动设备上可实时计算3D目标检测2020-03-13 3556
-
矩子科技的3D检测业务水平如何?2020-10-09 3559
-
谷歌AI发布3D物体数据集,附带标记边界框、相机位姿、稀疏点云2020-11-13 3075
-
谷歌Objectron数据集:3D目标检测数据集及检测方案2020-11-27 3389
-
设计时空自监督学习框架来学习3D点云表示2022-12-06 1782
-
KITTI数据集解读络!2023-02-27 4768
-
【3D形状分析利器】3D扫描应用案例集分享2023-02-01 2210
-
基于点云的3D障碍物检测介绍2023-06-26 2218
-
如何搞定自动驾驶3D目标检测!2024-01-05 1287
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2789
全部0条评论

快来发表一下你的评论吧 !
