

基于嵌入向量的全新设备端搜索库
描述
在今年的 I/O 大会上,我们很高兴宣布推出一个基于嵌入向量的全新设备端搜索库,让您在几毫秒的时间内即可从数百万个数据样本中快速找到相似的图像、文本或音频。

此搜索库通过使用模型,将搜索查询嵌入到表示查询语义的高维向量中来执行搜索。随后搜索库使用 ScaNN(可扩容最近邻算法)从预定义的数据库中搜索相似项目。为将搜索库应用到您的数据集,您需要使用 Model Maker Searcher API(教程)构建自定义 TFLite Searcher 模型,然后使用 Task Library Searcher API(视觉/文本)将其部署到设备上。
-
ScaNN
https://github.com/google-research/google-research/tree/master/scann
-
教程
https://tensorflow.google.cn/lite/tutorials/model_maker_text_searcher
-
视觉
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/image_searcher
-
文本
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/text_searcher
例如,使用在 COCO 上训练的 Searcher 模型,搜索查询:“A passenger plane on the runway”,系统将返回以下图像:
-
COCO
https://cocodataset.org/#home

图 1:所有图像均来自 COCO 2014 训练和验证数据集。图像 1 由 Mark Jones Jr. 依据《版权归属许可证》提供。图像 2 由 305 Seahill 依据《版权归属-禁止演绎许可证》提供。图像 3 由 tataquax 依据《版权归属-相同方式共享许可证》提供。
在本文中,我们将向您介绍使用新 TensorFlow Lite Searcher Library 构建文本到图像搜索功能的端到端示例(根据给定文本查询检索图像)。以下是主要步骤:
1. 使用 COCO 数据集训练用于图像和文本查询编码的双编码器模型。
2. 使用 Model Maker Searcher API 创建文本到图像 Searcher 模型。
3. 使用 Task Library Searcher API 检索带有文本查询的图像。
训练双编码器模型
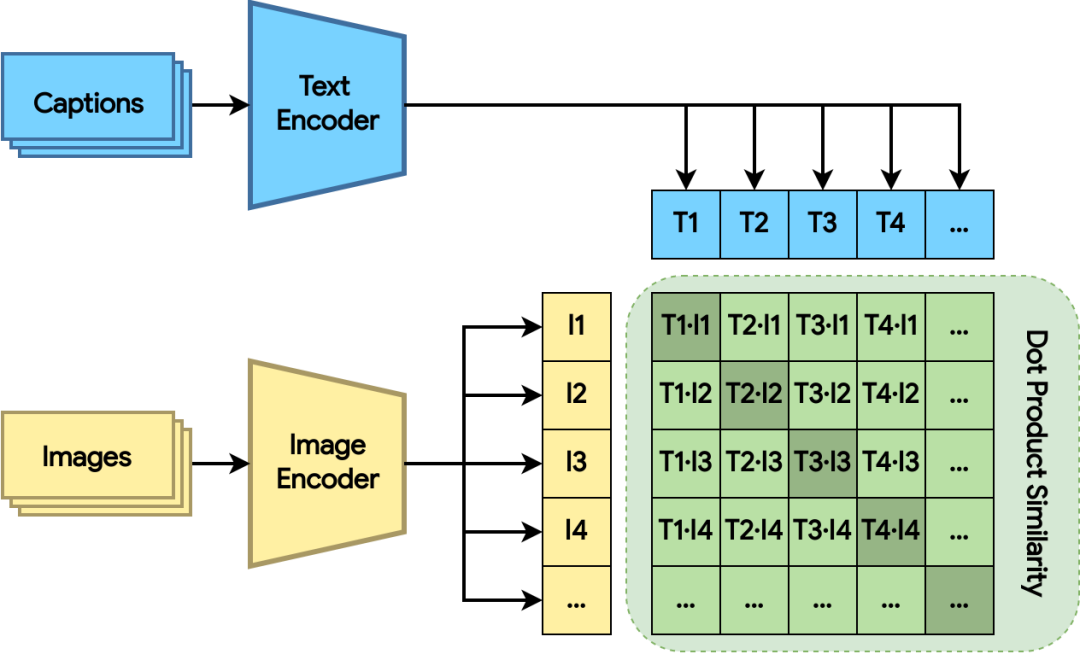
图 2:用点积相似距离训练双编码器模型。损失函数可为相关图像和文本赋予更大的点积(阴影绿色方块)
双编码器模型由图像编码器和文本编码器组成。两个编码器分别将图像和文本映射到高维空间中的嵌入向量。双编码器模型计算图像和文本嵌入向量之间的点积,同时损失函数可为相关图像和文本赋予更大的点积(更接近),而为不相关的图像和文本赋予更小的点积(更远)。
整个训练过程受到了 CLIP 论文和本 Keras 示例的启发。图像编码器是在预训练 EfficientNet 模型的基础上构建而成,而文本编码器则是基于预训练通用语句编码器模型。
-
CLIP
https://arxiv.org/abs/2103.00020
-
Keras 示例
https://keras.io/examples/nlp/nl_image_search/
-
EfficientNet
https://hub.tensorflow.google.cn/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2
-
通用语句编码器
https://hub.tensorflow.google.cn/google/universal-sentence-encoder-lite/2
系统随后会将两个编码器的输出投影到 128 维空间并进行 L2 归一化。对于数据集,我们选择使用 COCO,因为该数据集的训练和验证分块会为每个图像人工生成字幕。请查看配套的 Colab notebook,了解训练过程的详细信息。
-
Colab notebook
https://colab.sandbox.google.com/github/tensorflow/tflite-support/blob/master/tensorflow_lite_support/examples/colab/on_device_text_to_image_search_tflite.ipynb
双编码器模型可以从没有字幕的数据库中检索图像,因为在经过训练后,图像嵌入器可以直接从图像中提取语义,而无需人工生成的字幕。
使用 Model Maker 创建文本
到图像 Searcher 模型
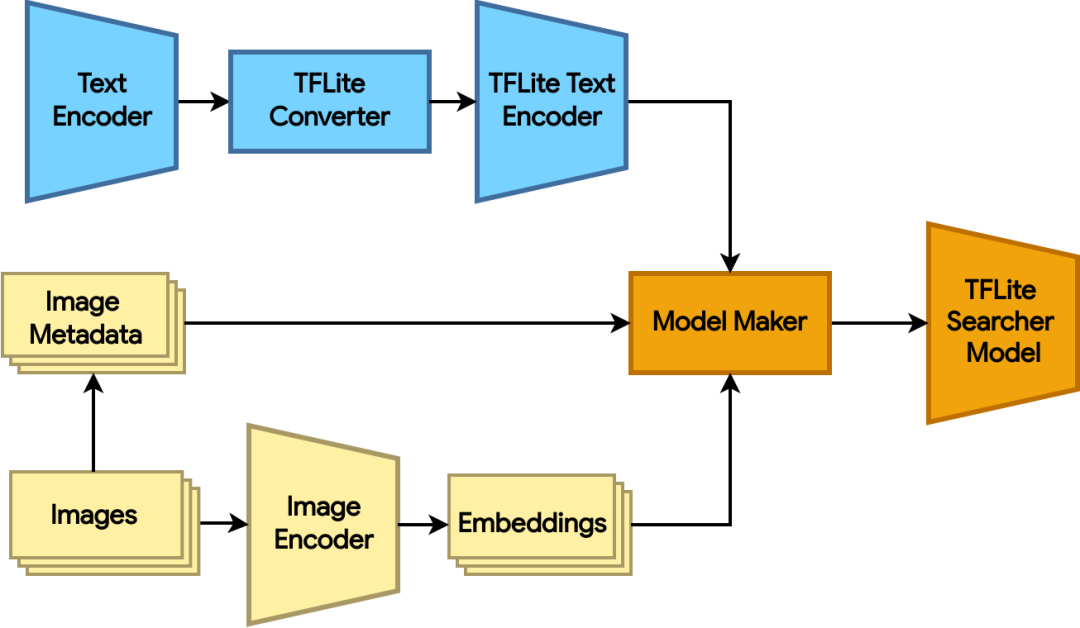
图 3:使用图像编码器生成图像嵌入向量,并使用 Model Maker 创建 TFLite Searcher 模型
完成对双编码器模型的训练后,我们可以使用它来创建 TFLite Searcher 模型,该模型可根据文本查询,从图像数据集中搜索最相关的图像。模型创建分为以下三大步骤:
1. 使用 TensorFlow 图像编码器生成图像数据集的嵌入向量。ScaNN 能够搜索非常庞大的数据集,因此我们结合了 COCO 2014 的训练和验证分块(总计超过 12.3 万张图像),以展示其搜索性能。相关代码请查阅此处(1)。
2. 将 TensorFlow 文本编码器模型转换为 TFLite 格式。相关代码请查阅此处(2)。
3. 使用 Model Maker,通过 TFLite 文本编码器和使用以下代码的图像嵌入向量创建 TFLite Searcher 模型:
-
此处(1)
https://colab.sandbox.google.com/github/tensorflow/tflite-support/blob/master/tensorflow_lite_support/examples/colab/on_device_text_to_image_search_tflite.ipynb#scrollTo=Bp0qBKkyu4jA
-
此处(2)
https://colab.research.google.com/github/tensorflow/tflite-support/blob/master/tensorflow_lite_support/examples/colab/on_device_text_to_image_search_tflite.ipynb#scrollTo=6Dzye66Xc8vE
#Configure ScaNN options. See the API doc for how to configure ScaNN.
scann_options = searcher.ScaNNOptions(
distance_measure='dot_product',
tree=searcher.Tree(num_leaves=351, num_leaves_to_search=4),
score_ah=searcher.ScoreAH(1, anisotropic_quantization_threshold=0.2))
# Load the image embeddings and corresponding metadata if any.
data = searcher.DataLoader(tflite_embedder_path, image_embeddings, metadata)
# Create the TFLite Searcher model.
model = searcher.Searcher.create_from_data(data, scann_options)
# Export the TFLite Searcher model.
model.export(
export_filename='searcher.tflite',
userinfo='',
export_format=searcher.ExportFormat.TFLITE)
请在此处查阅上方代码中提到的 API doc。
-
API doc
https://tensorflow.google.cn/lite/api_docs/python/tflite_model_maker/searcher/ScaNNOptions
在创建 Searcher 模型时,Model Maker 利用 ScaNN 将嵌入向量编入索引。嵌入向量数据集首先被分为多个子集。在每个子集中,ScaNN 存储嵌入向量的量化表征。在检索时,ScaNN 会选择一些最相关的分区,并按照快速近似距离对量化表征进行评分。这个过程既(通过量化)节省了模型大小又(通过分区选择)实现了加速。请参阅深入研究资料,详细了解 ScaNN 算法。
在上方示例中,我们将数据集划分为 351 个分区(约是我们拥有的嵌入向量数量的平方根),并在检索期间搜索其中的 4 个分区,即大约是数据集的 1%。我们还将 128 维浮点嵌入向量量化为 128 个 int8 值,以节省空间。
使用 Task Library 运行推理
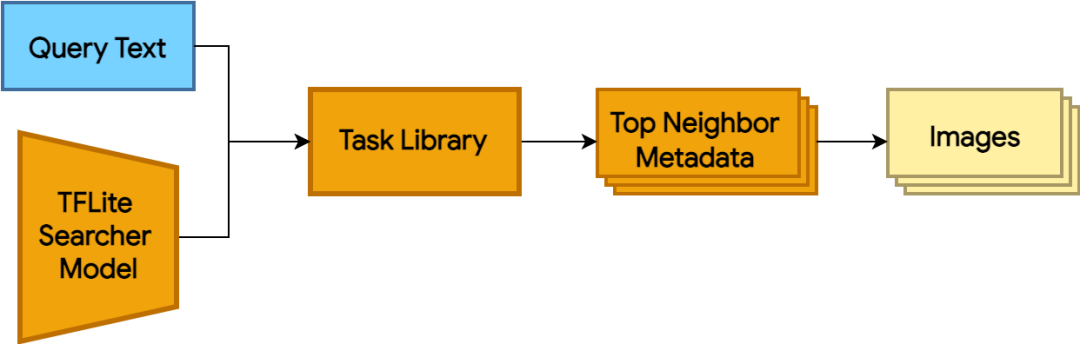
图 4:使用带有 TFLite Searcher 模型的 Task Library 运行推理。推理接收查询文本并返回最近邻的元数据。我们可以在此找到对应的图像
如要使用 Searcher 模型查询图像,您只需使用 Task Library 的几行代码即可,具体如下所示:
from tflite_support.task import text
# Initialize a TextSearcher object
searcher = text.TextSearcher.create_from_file('searcher.tflite')
# Search the input query
results = searcher.search(query_text)
# Show the results
for rank in range(len(results.nearest_neighbors)):
print('Rank #', rank, ':')
image_id = results.nearest_neighbors[rank].metadata
print('image_id: ', image_id)
print('distance: ', results.nearest_neighbors[rank].distance)
show_image_by_id(image_id)
可以尝试一下 Colab 的代码。此外,欢迎查看更多信息,了解如何使用 Task Library Java 和 C++ API 集成模型,尤其是在 Android 上的用法。在 Pixel 6 上,每个查询通常只需要 6 毫秒。
-
更多信息
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/text_searcher
以下是一些示例结果:
查询:A man riding a bike
根据估算的相似距离对结果进行排序。以下是检索到的图像示例。请注意,我们仅会显示附有图像使用许可的图像。

图 5:所有图像均来自 COCO 2014 训练和验证数据集。图像 1 由 Reuel Mark Delez 依据《版权归属许可证》提供。图像 2 由 Richard Masoner/Cyclelicious 依据《版权归属-相同方式共享许可证》提供。图像 3 由 Julia 依据《版权归属-相同方式共享许可证》提供。图像 4 由 Aaron Fulkerson 依据《版权归属-相同方式共享许可证》提供。图像 5 由 Richard Masoner/Cyclelicious 依据《版权归属-相同方式共享许可证》提供。图像 6 由 Richard Masoner/Cyclelicious 依据《版权归属-相同方式共享许可证》提供。
研究展望
我们将致力于启用除图像和文本之外的更多搜索类型,如音频片段。
审核编辑 :李倩
-
基于搜索机制密度聚类的支持向量预选取算法2009-04-15 535
-
高通发布全新设计DragonBoard板2011-10-03 5585
-
嵌入式消费设备的本机搜索2017-11-06 507
-
支持向量机网络搜索优化应用程序下载2021-04-20 1171
-
使用嵌入来做个性化的搜索推荐:来自Airbnb2022-02-07 398
-
向量数据库是如何工作的?2023-06-18 1666
-
增强AI能力:谷歌云在托管数据库中集成向量搜索2023-07-19 1116
-
什么是向量数据库?关系数据库和向量数据库之间的区别是什么?2023-08-16 4376
-
搭载英伟达GPU,全球领先的向量数据库公司Zilliz发布Milvus2.4向量数据库2024-04-01 1930
-
大模型卷价格,向量数据库“卷”什么?2024-05-23 3087
-
科技云报到:大模型时代下,向量数据库的野望2024-10-14 1021
-
Redis 8 向量搜索实测:轻松扩展至 10 亿向量2025-05-13 1000
-
KIOXIA单服务器实现48亿高维向量搜索数据库,借助GPU实现索引构建时间加速7.8倍2026-03-18 1166
-
Oracle和NVIDIA合作加速向量搜索和企业数据处理2026-03-23 589
全部0条评论

快来发表一下你的评论吧 !
