

微调前给预训练模型参数增加噪音提高效果的方法
描述
写在前面
昨天看完NoisyTune论文,做好实验就来了。一篇ACL2022通过微调前给预训练模型参数增加噪音提高预训练语言模型在下游任务的效果方法-NoisyTune,论文全称《NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better》。
paper地址:https://aclanthology.org/2022.acl-short.76.pdf
由于仅加两行代码就可以实现,就在自己的数据上进行了实验,发现确实有所提高,为此分享给大家;不过值得注意的是,「不同数据需要加入噪音的程度是不同」,需要自行调参。
模型
自2018年BERT模型横空出世,预训练语言模型基本上已经成为了自然语言处理领域的标配,「pretrain+finetune」成为了主流方法,下游任务的效果与模型预训练息息相关;然而由于预训练机制以及数据影响,导致预训练语言模型与下游任务存在一定的Gap,导致在finetune过程中,模型可能陷入局部最优。
为了减轻上述问题,提出了NoisyTune方法,即,在finetune前加入给预训练模型的参数增加少量噪音,给原始模型增加一些扰动,从而提高预训练语言模型在下游任务的效果,如下图所示,
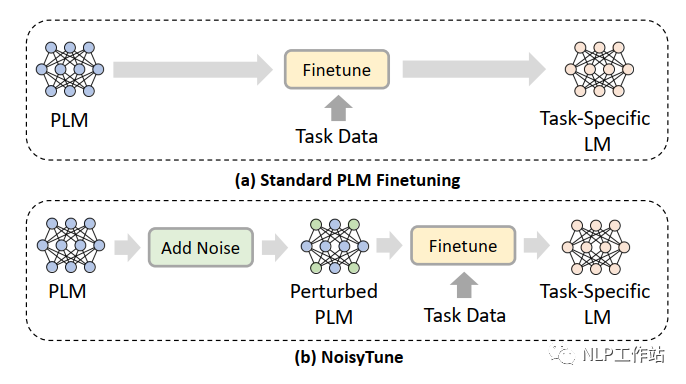
通过矩阵级扰动(matrix-wise perturbing)方法来增加噪声,定义预训练语言模型参数矩阵为,其中,表示模型中参数矩阵的个数,扰动如下:
其中,表示从到范围内均匀分布的噪声;表示控制噪声强度的超参数;表示标准差。
代码实现如下:
for name ,para in model.named parameters ():
model.state dict()[name][:] +=(torch.rand(para.size())−0.5)*noise_lambda*torch.std(para)
这种增加噪声的方法,可以应用到各种预训练语言模型中,可插拔且操作简单。
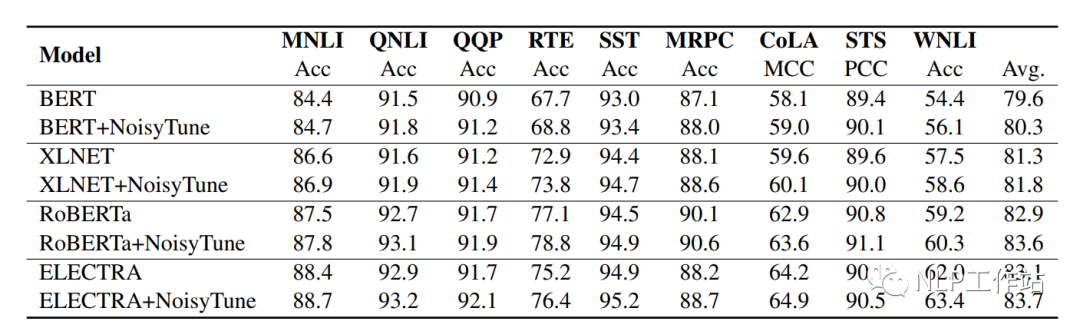
如下表所示,在BERT、XLNET、RoBERTa和ELECTRA上均取得不错的效果。
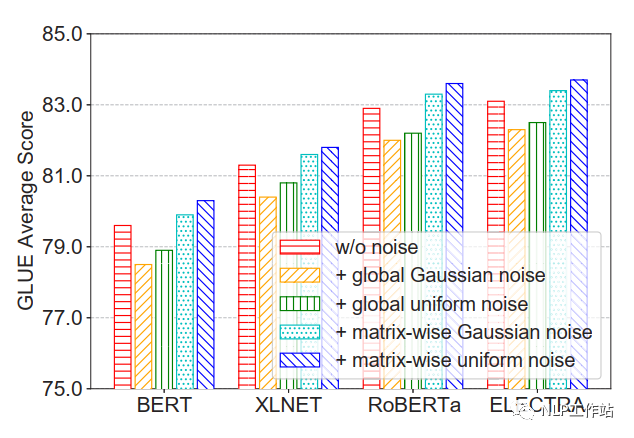
并且比较的四种不同增加噪声的方法,发现在矩阵级均匀噪声最优。
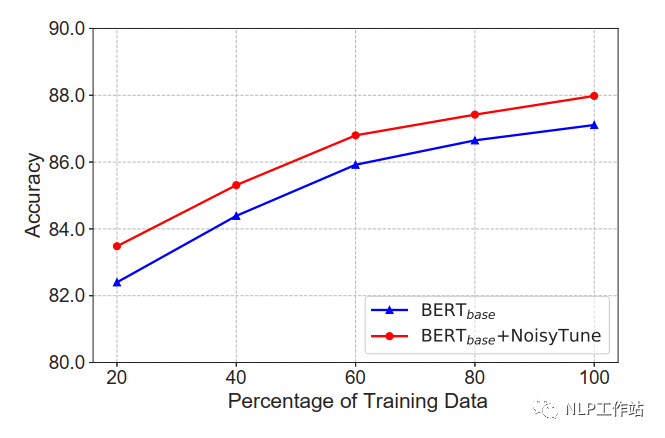
在不同数据量下,NoisyTune方法相对于finetune均有所提高。
在不同噪声强度下,效果提升不同,对于GLUE数据集,在0.1-0.15间为最佳。
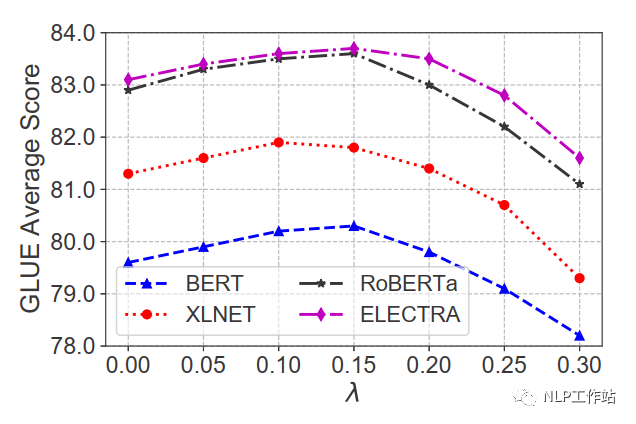
总结
蛮有意思的一篇论文,加入少量噪音,提高下游微调效果,并且可插拔方便易用,可以纳入到技术库中。
本人在自己的中文数据上做了一些实验,发现结果也是有一些提高的,一般在0.3%-0.9%之间,但是噪声强度在0.2时最佳,并且在噪声强度小于0.1或大于0.25后,会比原始效果差。个人实验结果,仅供参考。
审核编辑 :李倩
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读2025-01-14 2335
-
AI大模型微调企业项目实战课2026-04-16 936
-
为什么要使用预训练模型?8种优秀预训练模型大盘点2019-04-04 24677
-
关于语言模型和对抗训练的工作2020-11-02 3005
-
小米在预训练模型的探索与优化2020-12-31 4071
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2608
-
如何更高效地使用预训练语言模型2022-07-08 2104
-
利用视觉语言模型对检测器进行预训练2022-08-08 2451
-
介绍大模型高效训练所需要的主要技术2022-11-08 6409
-
使用 NVIDIA TAO 工具套件和预训练模型加快 AI 开发2022-12-15 2284
-
基于多任务预训练模块化提示2023-06-20 1644
-
四种微调大模型的方法介绍2024-01-03 27100
-
预训练模型的基本原理和应用2024-07-03 6063
-
大语言模型的预训练2024-07-11 1928
全部0条评论

快来发表一下你的评论吧 !
