

基于语音识别技术用于录音应用
描述
在一个痴迷于互联网隐私的世界里,令人惊讶的是,我们很少谈论像 Amazon Echo 这样的始终在听的设备。毕竟,一家想要了解你生活中的私密细节以便向你推销更多东西的公司会在你的厨房里永久打开一个麦克风。
如果您拥有 Echo 并且不知道此功能,请打开您的 Alexa 应用程序,选择“设置”菜单,然后选择“历史记录”。听一听。所有这些录音都是为 Echo 准备的吗?
我想隐私是现代消费主义中便利的代价。事情将变得更加方便。
杂音、鸡尾酒会、便利和圣诞节
XMOS 是一家从布里斯托大学分离出来的无晶圆半导体公司,专注于语音和音乐处理 IC。在这些 IC 中,基于 32 位 xCORE MCU 架构的设备在语音识别市场上取得了显着的成功,提供了 16 个可编程内核(分为 8 个内核的两个区块,每个内核共享一个地址空间),DSP 功能集成在相同的芯片。
XMOS 将 xCORE 架构加入到用于亚马逊 Alexa 语音服务 (AVS) 的 VocalFusion 4-Mic 开发套件中。该套件围绕英飞凌的 VocalFusion XVF3000 集成远场语音处理器和四个高信噪比 (SNR) MEMS 麦克风而设计。XMOS 声称该套件是市场上第一个远场线性麦克风阵列解决方案。
在范围之外,在解决“鸡尾酒会”问题或平台需要将单个扬声器的声音与嘈杂环境隔离的情况时,远场语音处理变得非常有趣。在 5 m 或更远的距离处,VocalFusion 4-Mic 开发套件使用声学回声消除 (AEC)、自适应波束形成、动态去混响和自动增益控制 (AGC) 的组合来隔离和提取声音信号主讲者。除此之外,事情开始变得令人毛骨悚然。
今年早些时候,XMOS 收购了马萨诸塞州波士顿的 Setem Technologies, Inc.,该公司开发了用于盲源信号分离的大规模傅立叶变换。这些盲源分离算法在数学上从一组信号中分解源信号的元素,然后单独或作为组重构它们(图 1)。在语音识别中,这可以应用于单个说话者,甚至是对话。
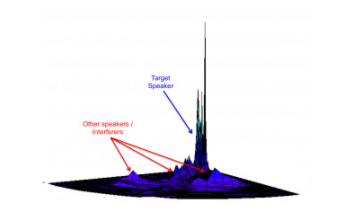
图 1.现在隶属于 XMOS 的 Setem Technologies 开发了盲源分离算法,可用于隔离嘈杂环境中的一个或多个扬声器。
现在,在理论上(或许在实践中),盲源分离可用于隔离房间内多个说话者的语音频率,从而为每个说话者建立生物识别身份。正如你可以想象的那样,这种技术的应用可能会很广泛,不仅仅是亚马逊想知道你的每个家庭成员想要什么圣诞节。例如,监视立即浮现在脑海中。
这让我们回到了 VocalFusion 4-Mic Dev Kit 的线性麦克风阵列。虽然 Amazon Echo 和 Google Home 等许多平台使用圆形阵列的全向麦克风来提供 360 度的房间覆盖,但线性阵列设计用于 180 度的弧度。这很有趣,因为语音识别领域的领导者设想了一个未来,今天基于塔的虚拟助手将退居电视、冰箱、沙发、墙壁等日常物品中——你可以说出来。
这个未来被设计为超级方便,通过音节提供服务。但小心点。你可能不知道谁或什么在听。
审核编辑:郭婷
-
【语音识别】你知道什么是离线语音识别和在线语音识别吗?2021-04-01 7161
-
语音识别技术的基本原理及应用是什么?2021-05-31 5145
-
如何通过LD3320语音识别模块识别我们预定的短语2022-01-12 2624
-
怎样去解决RK3328 Android 7.1录音出现偶现语音无法识别的问题2022-03-09 2144
-
离线语音识别及控制是怎样的技术?2023-11-24 2215
-
语音识别技术,语音识别技术是什么意思2010-03-06 3252
-
国内语音识别技术上市公司汇总_语音识别技术现状_语音识别原理及应用2017-12-13 10873
-
语音芯片怎么录音2019-03-27 9159
-
语音识别芯片的原理_语音识别芯片有哪些2019-10-01 5999
-
语音识别芯片的分类及应用2021-10-21 3506
-
情感语音识别技术及其应用2023-06-24 2370
-
语音识别技术的应用及优化2023-10-10 4256
-
ASR语音识别技术应用2024-11-18 3779
-
语音识别技术的应用与发展2024-11-26 2858
-
语音识别IC分类,语音识别芯片的工作原理2026-01-14 558
全部0条评论

快来发表一下你的评论吧 !
