

云原生运行时防护系统Tetragon介绍
电子说
描述
TL;DR
文章较长,代码很多,可直接拖到文末看讲解视频。
背景
在云原生领域中,Cilium是容器管理上最著名的网络编排、可观察性、网络安全的开源软件。基于革命性技术eBPF实现,并用XDP、TC等功能实现了L3、L4层的防火墙、负载均衡软件,具备优秀的网络安全处理能力,但在运行时安全上,Cilium一直是缺失的。
2022年5月,在欧洲举行的KubeCon技术峰会期间,Cilium的母公司Isovalent发布了云原生运行时防护系统Tetragon[1],填补这一空缺。
Tetragon的面世,意味着与falco、tracee、KubeArmor、datadog-agent等几款产品正面竞争,eBPF运行时防护领域愈加内卷。
Tetragon介绍
摘自Tetragon官方仓库[2]的产品介绍。
eBPF实时性
Tetragon 是一个运行时安全实时和可观察性工具。它直接在内核中对事件做相应动作,比如执行过滤、阻止,无需再将事件发送到用户空间处理。
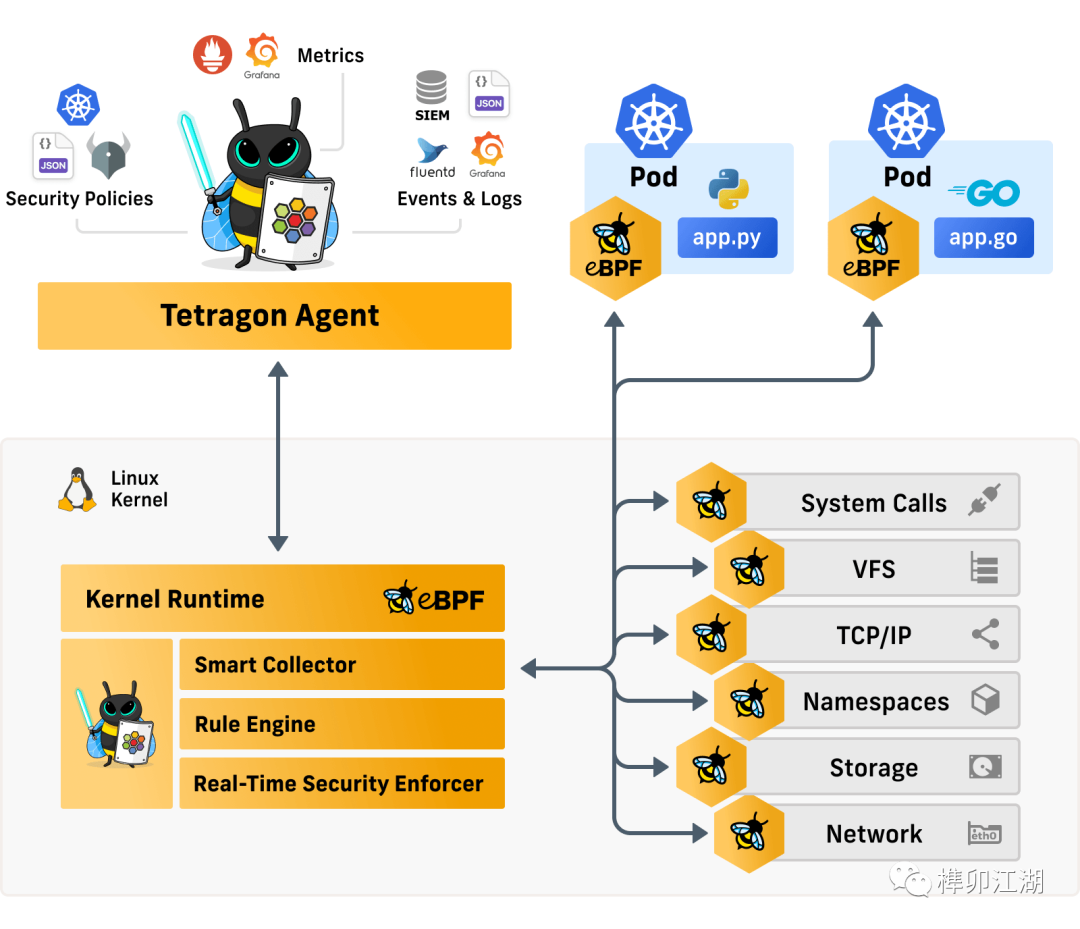
对于可观察性用例,直接在内核中应用过滤器会大大减少观察开销。避免昂贵的上下文切换,尤其是对于高频事件,例如发送、读取或写入操作,减少了大量的内存、CPU等资源。
同时,Tetragon提供了丰富的过滤器(文件、套接字、二进制名称、命名空间等),允许用户筛选重要且相关的事件,并传递给用户空间。
eBPF灵活性
Tetragon 可以挂载到Linux Kernel中的任何函数,并过滤其参数、返回值、进程元数据(例如,可执行文件名称)、文件和其他属性。
跟踪策略通过编写跟踪策略,用户可以解决各种安全性和可观察性用例。Tetragon社区中,提供了一些常见的跟踪策略,可以解决大部分的可观察性和安全用例。
用户也可以创建新的规则策略部署,自定义配置文件,以满足业务需求。
eBPF 内核感知
Tetragon 通过eBPF钩子感知Linux Kernel状态,并将状态与Kubernetes用户策略相结合,以创建由内核实时执行的规则,来增强云原生场景的安全防护功能。例如,当容器内恶意程序更改其权限时,我们可以创建一个策略来触发警报,甚至在进程有机会完成系统调用并可能运行其他系统调用之前终止该进程。
Tetragon阻断实现原理
以上是Tetragon官方的介绍,提到具备阻断能力,并在技术峰会上,展示了相关阻断的截图,有必要了解一下其实现原理。
tetragon的运行原理会在下篇详细介绍,本篇主要讲实时阻断原理。本文分析的代码版本为首次发布的tag v0.8.0[3] ,commit ID:75e49ab。
业界常见方式
LKM的内核模块、LD_PRELOAD的动态链接库修改、基于LSM的selinux、seccomp技术等都是常见做内核态/用户态运行时阻断的技术方案,而缺点就比较明显,系统稳定性、规则灵活性、变更周期等问题比较突出。
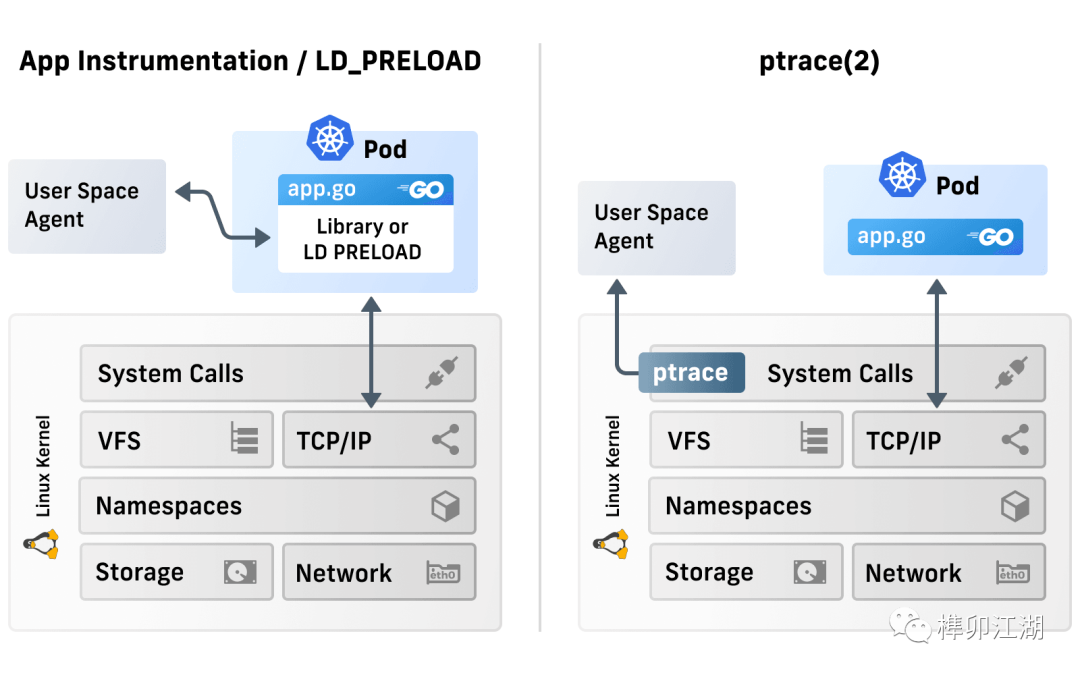
当然,也有使用内核模块方式。方法是把eBPF特性,封装在内核模块里,再安装到老版本的内核上,这样,就可以覆盖更多内核版本了。但backport新特性的做法在社区里很不推荐,维护成本特别高,需要比较大的内核研发团队与深厚的技术功底。。
云原生生态中,CNCF的项目Falco具备内核模块与eBPF探针两套驱动引擎,提供数据收集能力。同类产品Tracee也是,还基于LSM接口,实现了一定的防御阻断能力,同时支持使用者自定义语法配置文件,进行检测、判断、阻断规则的修改快速更新,以达到更好的防御能力。
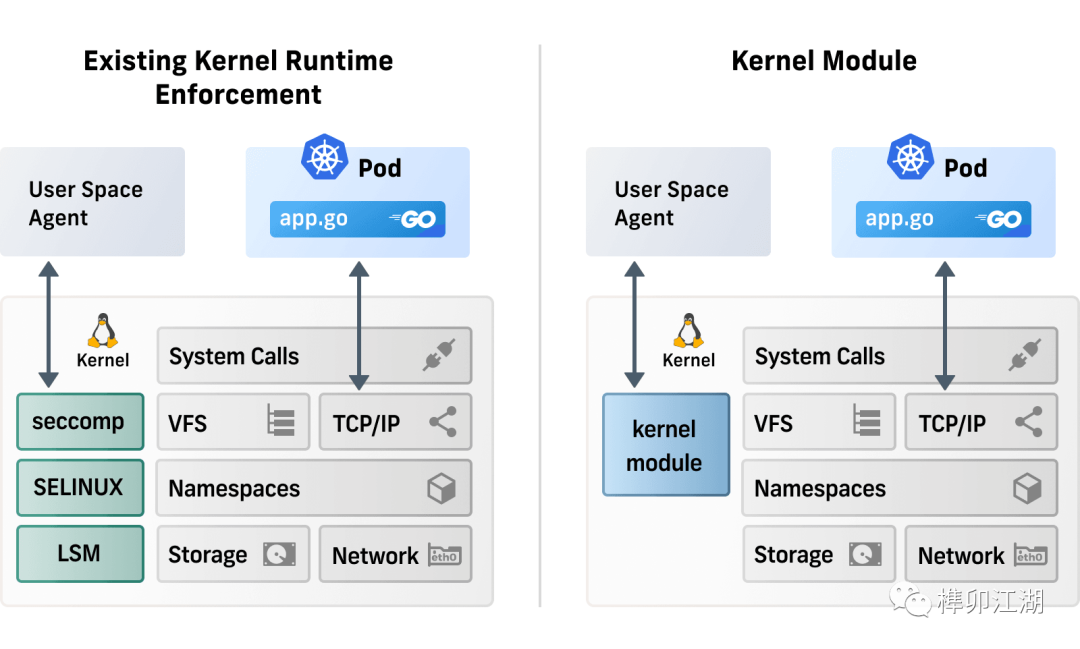
作为云原生领域的容器管理软件领头羊,Cilium也会落后,但Linux Security Module[4]钩子(以下简称LSM)需要Linux Kernel 5.7以上版本,而业界多数内核版本都不会这么新。Cilium有没有使用LSM类HOOK进行阻断呢?我们一起来看一下。
配置文件
前面提到,Tetragon灵活性更高,可以读取配置文件规则,应用到内核态。以代码仓库的crds/examples/open_kill.yaml为例,语法规则分为如下几部分
- kprobe函数名
- 函数原型参数
- 进程过滤配置
- 参数过滤配置
- 执行动作
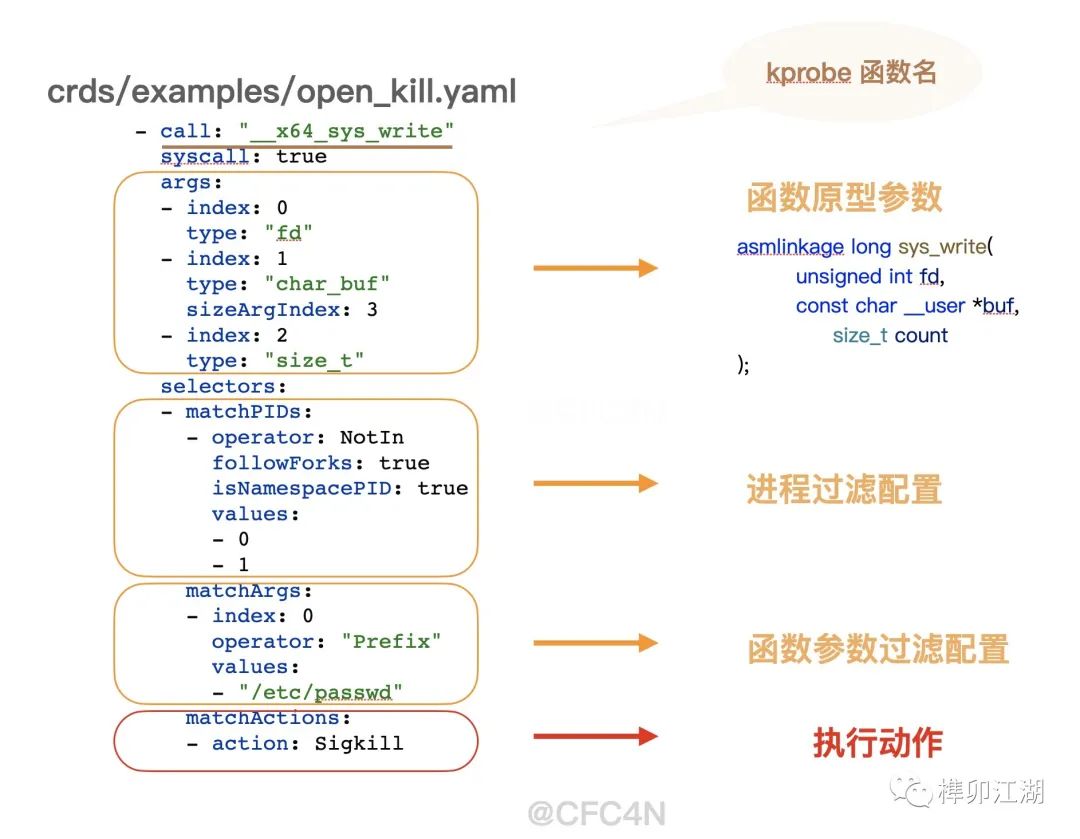
其中,matchActions字段为匹配后的执行动作,比如这里的Sigkill
- call: "__x64_sys_write"
syscall: true
args:
- index: 0
type: "fd"
- index: 1
type: "char_buf"
sizeArgIndex: 3
- index: 2
type: "size_t"
selectors:
- matchPIDs:
- operator: NotIn
followForks: true
isNamespacePID: true
values:
- 0
- 1
matchArgs:
- index: 0
operator: "Prefix"
values:
- "/etc/passwd"
matchActions:
- action: Sigkill
yaml配置文件的解析在pkg/k8s/apis/cilium.io/v1alpha1/types.go中的TracingPolicySpec结构体中,包含KProbeSpec和TracepointSpec, 对应json:"kprobes"和json:"tracepoints"两个json的结构。
type TracingPolicySpec struct {
// +kubebuilderOptional
// A list of kprobe specs.
KProbes []KProbeSpec `json:"kprobes"`
// +kubebuilderOptional
// A list of tracepoint specs.
Tracepoints []TracepointSpec `json:"tracepoints"`
}
同时,Tetragon还支持远程下发配置,配置结构与yaml结构是一样的。这里相比传统的内核模块等技术方案,灵活性更高。
用户空间
详细执行流程会在下篇分享,直入主题。
数据结构
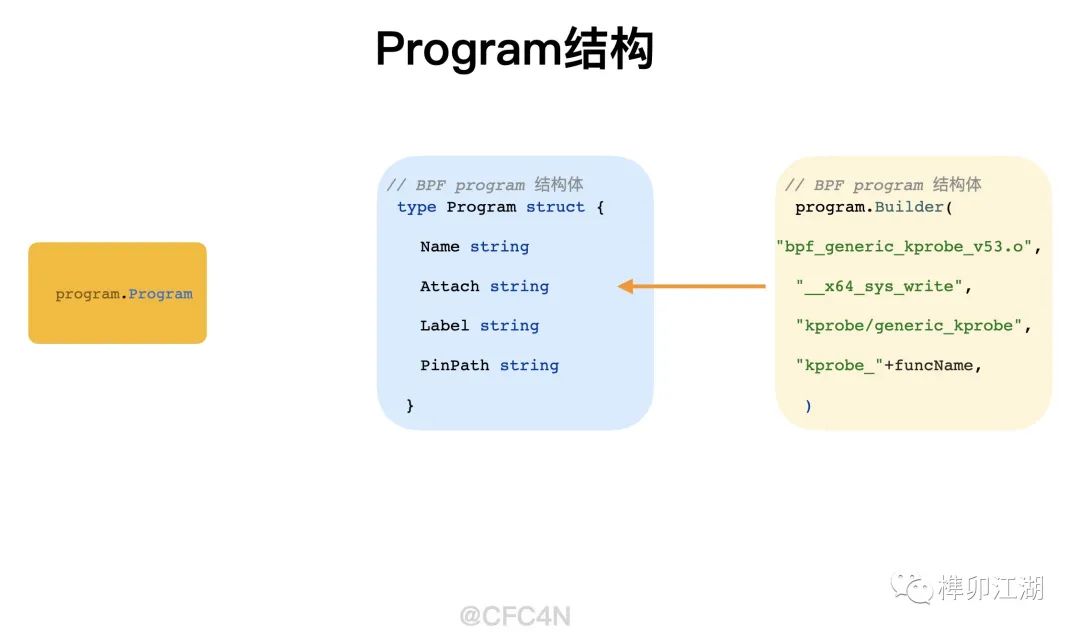
在项目中,抽象出一些概念:
- Tetragon由多个Sensors传感器构成
- Sensor由多个Programs和Maps构成
- 每个Program对应eBPF代码的HOOK函数
- 每个Map是相应Program的bpf的数据交互map

// Program reprents a BPF program.
type Program struct {
// Name is the name of the BPF object file.
Name string
// Attach is the attachment point, e.g. the kernel function.
Attach string
// Label is the program section name to load from program.
Label string
// PinPath is the pinned path to this program. Note this is a relative path
// based on the BPF directory FGS is running under.
PinPath string
// RetProbe indicates whether a kprobe is a kretprobe.
RetProbe bool
// ErrorFatal indicates whether a program must load and fatal otherwise.
// Most program will set this to true. For example, kernel functions hooks
// may change across verions so different names are attempted, hence
// avoiding fataling when the first attempt fails.
ErrorFatal bool
// Needs override bpf program
Override bool
// Type is the type of BPF program. For example, tc, skb, tracepoint,
// etc.
Type string
LoadState State
// TraceFD is needed because tracepoints are added different than kprobes
// for example. The FD is to keep a reference to the tracepoint program in
// order to delete it. TODO: This can be moved into loaderData for
// tracepoints.
TraceFD int
// LoaderData represents per-type specific fields.
LoaderData interface{}
// unloader for the program. nil if not loaded.
unloader unloader.Unloader
}
ExecveV53 = program.Builder(
"bpf_execve_event_v53.o",
"sched/sched_process_exec",
"tracepoint/sys_execve",
"event_execve",
"execve",
)
Sensors传感器加载
默认传感器注册
pkg/sensors/tracing包下由两个文件对传感器进行默认注册,分别是generictracepoint.go与generickprobe.go,写入如下两个Sensors到registeredTracingSensors中。
- observerKprobeSensor ,kprobe类型HOOK
- observerTracepointSensor, tracepoint类型HOOK
同时,还会注册自定义eBPF probe加载器到registeredProbeLoad中。
// generickprobe.go#Line=43
func init() {
kprobe := &observerKprobeSensor{
name: "kprobe sensor",
}
sensors.RegisterProbeType("generic_kprobe", kprobe)
sensors.RegisterTracingSensorsAtInit(kprobe.name, kprobe)
observer.RegisterEventHandlerAtInit(ops.MSG_OP_GENERIC_KPROBE, handleGenericKprobe)
}
策略文件解析
GetSensorsFromParserPolicy方法遍历所有Sensors,调用它的SpecHandler方法,解析yaml配置。解析配置后,生成新的传感器对象,作为整个应用启动、注入、监听的所有传感器。
// cmd/tetragon/main.go#line=209
startSensors, err = sensors.GetSensorsFromParserPolicy(&cnf.Spec)
// pkg/sensors/sensors.go#line=160
for _, s := range registeredTracingSensors {
sensor, err := s.SpecHandler(spec)
if err != nil {
return nil, err
}
if sensor == nil {
continue
}
sensors = append(sensors, sensor)
}
新增传感器
接上,yaml解析器读取格式后,根据当前传感器的类型(kprobe还是tracepoint),处理yaml配置文件对应的HOOK配置。
kprobe类型以kprobe类型的hook配置为例,调用 addGenericKprobeSensors 详细处理每一个配置内容。
// pkg/sensors/tracing/generickprobe.go#line=242-516
func addGenericKprobeSensors(kprobes []v1alpha1.KProbeSpec, btfBaseFile string) (*sensors.Sensor, error) {
// 遍历所有kprobes的元素
for i := range kprobes {
f := &kprobes[i]
funcName := f.Call
// 1. 验证配置文件中配置依赖,比如Sigkill需要内核大于5.3
// 2. 解析匹配参数(进程名、namespace、路径、五元组等)写入BTF对象
// 3. 解析ReturnArg 返回值参数,写入到BTF对象
// 4. 过滤保留参数,写入BTF对象
// 5. 解析Filters逻辑,写入BTF对象
// 6. 解析Binary名字到内核数据结构体
// 7. 将属性写入BTF指针,以便加载
// 8. 判断action是否为SIGKILL,并写入BTF对象
kernelSelectors, err := selectors.InitKernelSelectors(f)
kprobeEntry := genericKprobe{
loadArgs: kprobeLoadArgs{
filters: kernelSelectors,
btf: uintptr(btfobj),
retprobe: setRetprobe,
syscall: is_syscall,
},
argSigPrinters: argSigPrinters,
argReturnPrinters: argReturnPrinters,
userReturnFilters: userReturnFilters,
funcName: funcName,
pendingEvents: map[uint64]pendingEvent{},
tableId: idtable.UninitializedEntryID,
}
genericKprobeTable.AddEntry(&kprobeEntry)
// 9. 设定这个kprobe所需的ebpf字节码文件信息
loadProgName := "bpf_generic_kprobe_v53.o"
// 10. 利用如上信息,填充到prog的结构体中。
// 11. 在prog结构体中,label字段的值都是**kprobe/generic_kprobe**
load := program.Builder(
path.Join(option.Config.HubbleLib, loadProgName),
funcName,
"kprobe/generic_kprobe",
"kprobe"+"_"+funcName,
"generic_kprobe").
SetLoaderData(kprobeEntry.tableId)
}
// 创建生成新的sensor,并返回
return &sensors.Sensor{
Name: "__generic_kprobe_sensors__",
Progs: progs,
Maps: []*program.Map{},
}, nil
}
解析过程如下:
- 验证配置文件中配置依赖,比如Sigkill需要内核大于5.3
- 解析匹配参数(进程名、namespace、路径、五元组等)写入BTF对象
- 解析ReturnArg 返回值参数,写入到BTF对象
- 过滤保留参数,写入BTF对象
- 解析Filters逻辑,写入BTF对象
- 解析Binary名字到内核数据结构体
- 将属性写入BTF指针,以便加载
- 判断action是否为SIGKILL,并写入BTF对象
- 设定这个kprobe所需的ebpf字节码文件信息
- 利用如上信息,填充到prog的结构体中。
- 在prog结构体中,label字段的值都是kprobe/generic_kprobe
解析完成后,返回一个新的sensor,并添加到Sensors传感器数组中。
至此,完成了配置文件的解析。在这里,阻断指令的配置,是保存在genericKprobe.loadArgs.filters这个byte数组中的。
动态更新
在tetragon项目中,还具备从远程下发新的规则,更新、添加Sensor传感器功能,相应代码在pkg/observer/observer.go中,本篇不做过多展开,会在下篇分享。
// InitSensorManager starts the sensor controller and stt manager.
func (k *Observer) InitSensorManager() error {
var err error
SensorManager, err = sensors.StartSensorManager(k.bpfDir, k.mapDir, k.ciliumDir)
return err
}
eBPF加载与挂载
Sensors启动
传感器启动加载,执行流程为obs.Start(ctx, startSensors) -> config.LoadConfig -> load.Load 。
在Load方法里,对每一个Program元素,调用observerLoadInstance方法进行加载。
// load.Load
// Load loads the sensor, by loading all the BPF programs and maps.
func (s *Sensor) Load(stopCtx context.Context, bpfDir, mapDir, ciliumDir string) error {
for _, p := range s.Progs {
// ...
// 加载每个prog
if err := observerLoadInstance(stopCtx, bpfDir, mapDir, ciliumDir, p); err != nil {
return err
}
// ...
}
}
eBPF Program加载、挂载
在对每个eBPF program进行加载时,会判断HOOK的类型,针对tracepoint特殊判断处理。这里还是以Kprobe为例。代码调用loadInstance函数,逻辑中判断是否存在自定义的加载器:
-
若有,则调用
s.LoadProbe加载; -
若没有,则调用
loader.LoadKprobeProgram加载;
// pkg/sensors/load.go#Line=297
if s, ok := registeredProbeLoad[load.Type]; ok {
logger.GetLogger().WithField("Program", load.Name).WithField("Type", load.Type).Infof("Load probe")
return s.LoadProbe(LoadProbeArgs{
BPFDir: bpfDir,
MapDir: mapDir,
CiliumDir: ciliumDir,
Load: load,
Version: version,
Verbose: verbose,
})
}
return loader.LoadKprobeProgram(
version, verbose,
btfObj,
load.Name,
load.Attach,
load.Label,
filepath.Join(bpfDir, load.PinPath),
mapDir,
load.RetProbe)
同样,以前面提到的observerKprobeSensor类型传感器,已经注册自己的Probe加载器,那么会走s.LoadProbe()逻辑,之后,调用loadGenericKprobeSensor() -> loadGenericKprobe()进行加载。
这里的load.Name、load.Attach、load.Label的值,来自前面的yaml配置文件读取部分,值分别为bpf_generic_kprobe_v53.o、 __x64_sys_write 、 kprobe/generic_kprobe,也就是说,不管是哪个kprobe函数,都会被挂载到kprobe/generic_kprobe上,都被generic_kprobe_event()这个eBPF 函数处理,起到统一管理的网关作用。
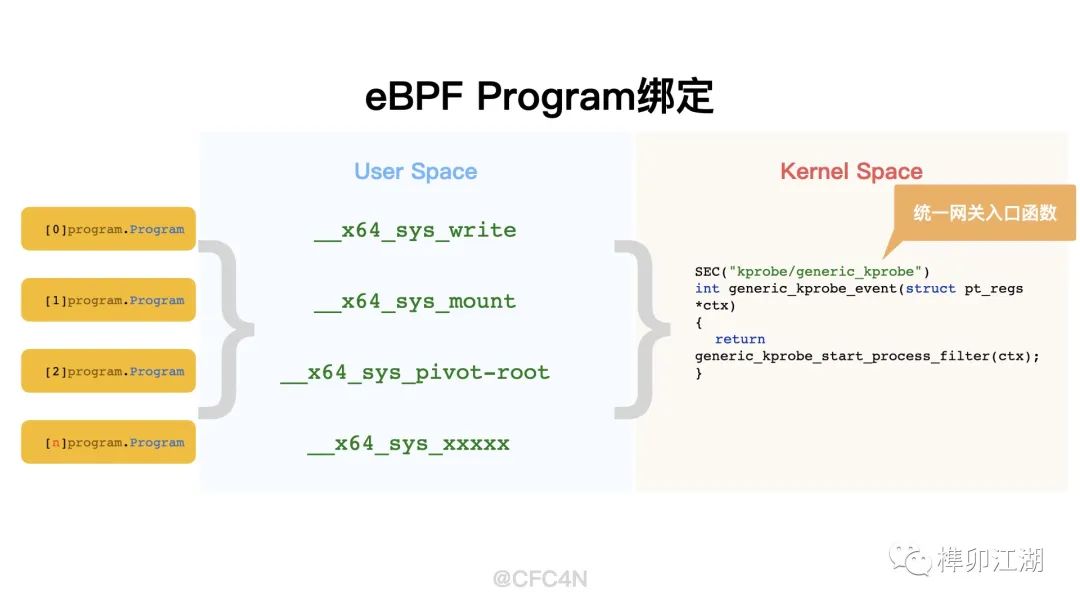
kprobe/generic_kprobe对应的eBPF代码在bpf/process/bpf_generic_kprobe.c文件里,我们在后面内核空间代码详细分析。
__attribute__((section(("kprobe/generic_kprobe")), used)) int
generic_kprobe_event(struct pt_regs *ctx)
{
return generic_kprobe_start_process_filter(ctx);
}
filters过滤器
loadGenericKprobe()函数最后一个参数filters过滤器参数,类型是[4096]byte
func loadGenericKprobe(bpfDir, mapDir string, version int, p *program.Program, btf uintptr, genmapDir string, filters [4096]byte) error {
}
其内容为前面yaml格式解析中的第5步,
kernelSelectors, err := selectors.InitKernelSelectors(f)
格式构成为
filter := [length][matchPIDs][matchBinaries][matchArgs][matchNamespaces][matchCapabilities][matchNamespaceChanges][matchCapabilityChanges]
这些数据,也是在内核空间eBPF逻辑中,实现参数匹配,动作响应的判断依据。
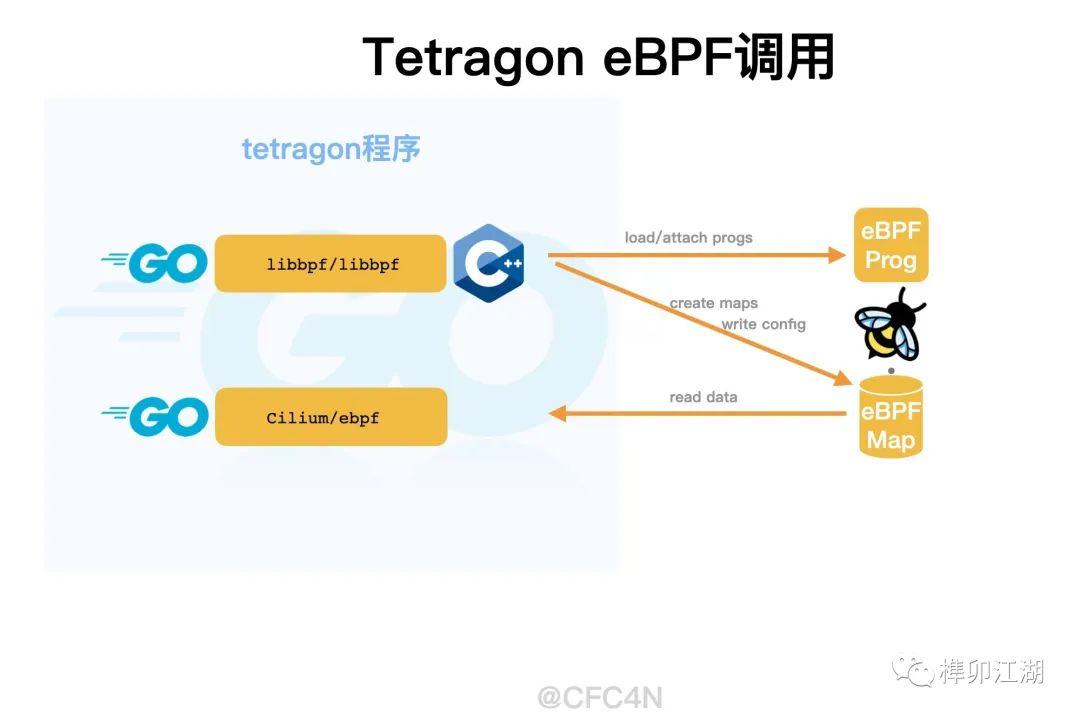
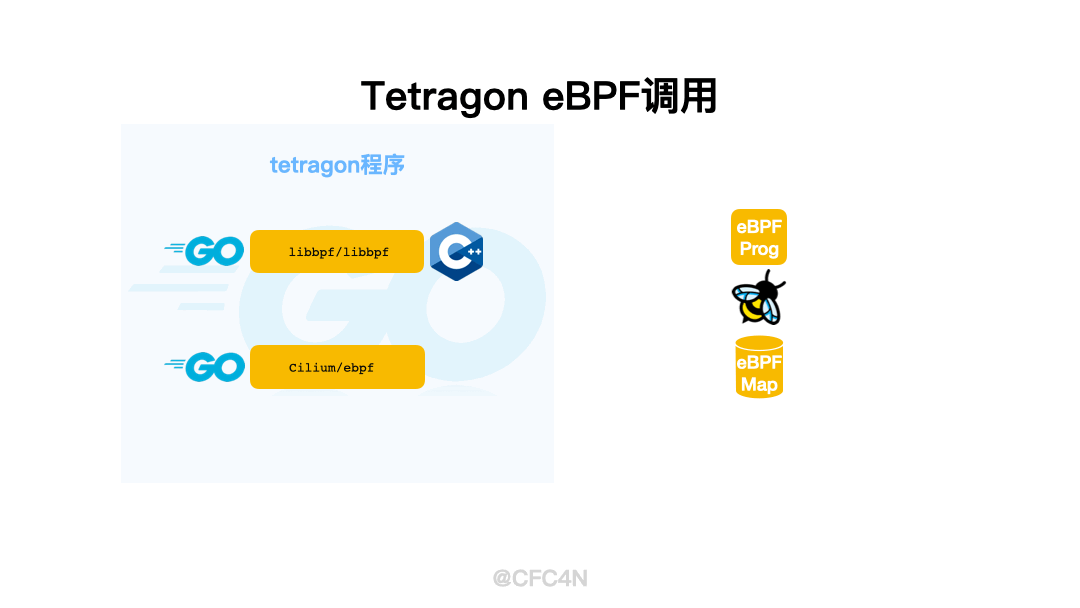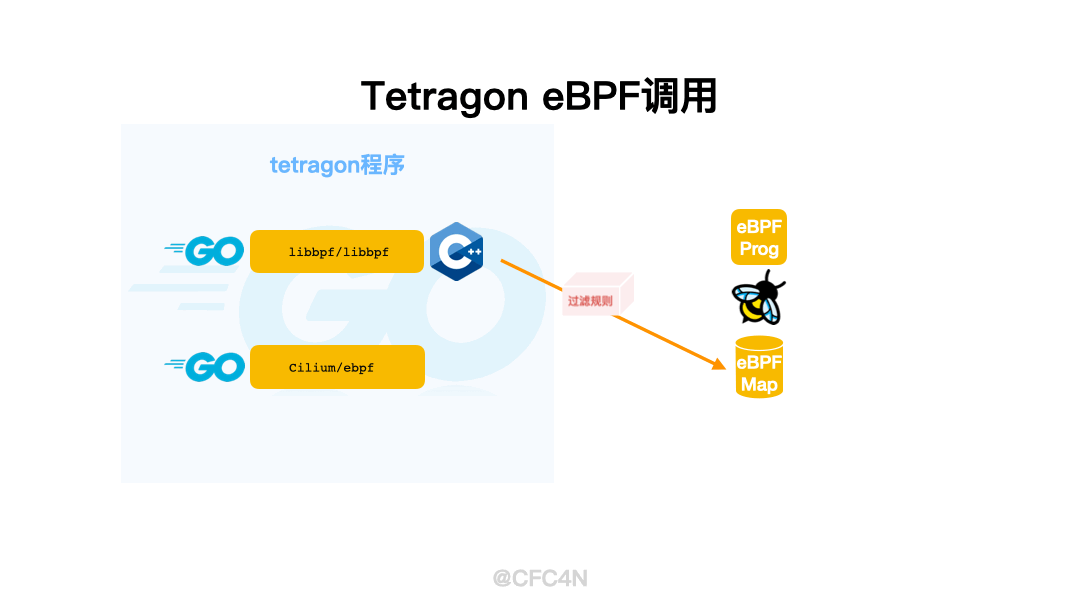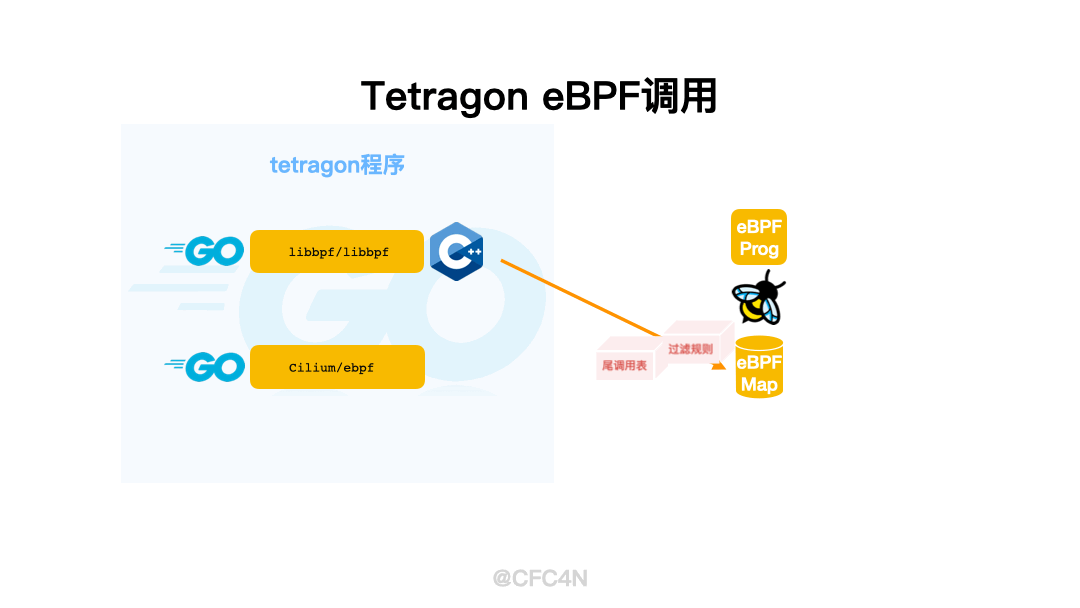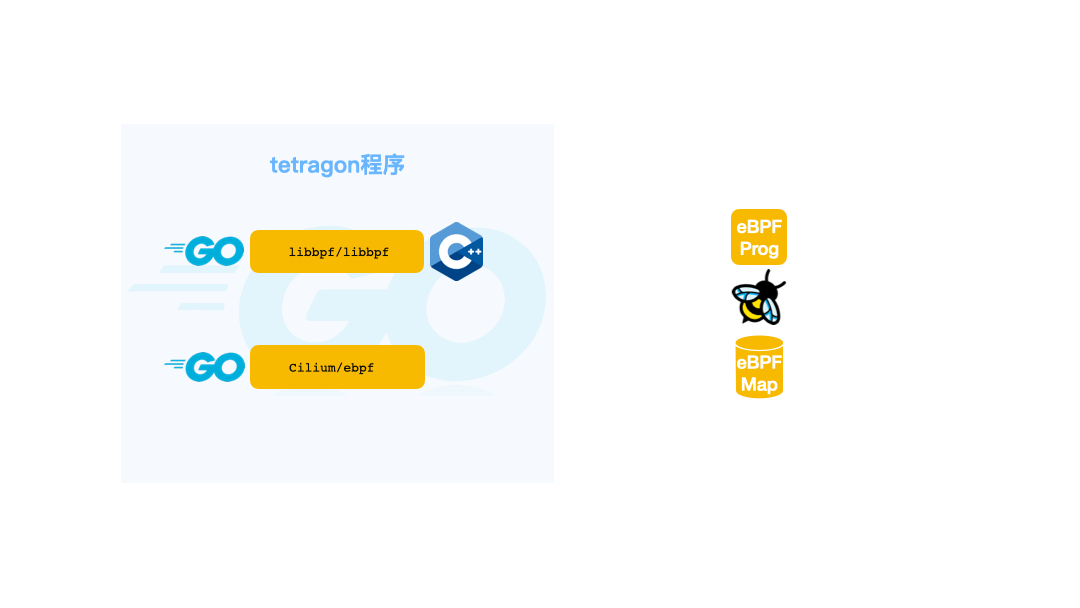
Cgo函数调用
在调用BPF SYSCALL的实现上,Tetragon没有使用母公司自己的Cilium/ebpf库,而是使用CGo包装了libbpf进行加载。使用的版本还是0.2.0,当前社区最新版为0.7.0,比较老。(下一篇再讲原因)
loadGenericKprobe()函数调用bpf.LoadGenericKprobeProgram(),并把filters传递给下一个CGO的函数C.generic_kprobe_loader(),函数定义在pkg/bpf/loader.go的476行。
int generic_kprobe_loader(const int version,
const int verbosity,
bool override,
void *btf,
const char *prog,
const char *attach,
const char *label,
const char *__prog,
const char *mapdir,
const char *genmapdir,
void *filters) {
struct bpf_object *obj;
int err;
obj = generic_loader_args(version, verbosity, override, btf, prog, attach,
label, __prog, mapdir, filters, BPF_PROG_TYPE_KPROBE);
if (!obj) {
return -1;
}
// ...
}
之后,再调用CGO的C函数generic_loader_args()进行BPF SYSCALL调用,加载eBPF程序,挂载到对应kprobe函数上。之后,再写入eBPF Maps。
eBPF Maps创建写入
Tetragon使用eBPF Maps进行用户空间与内核空间的配置数据交互,比如yaml配置文件中,各种过滤条件,匹配后的处理动作等。
还是以open_kill.yaml为例,涉及了两类eBPF Map:
- 特征匹配规则,也就是配置的内容,比如需要保护的文件路径、IP黑名单等,称之为filters规则
- 路由分发规则,也就是tetragon程序内部,用于eBPF HOOK的函数网关处理各类参数的自用规则,用尾调用Tail Call类型的map实现。
filters规则Map
在generic_loader_args()里,创建了"filter_map" eBPF Map,并将判断规则、阻断规则filter bytes数组写入到这个map里,格式依旧是[4096]byte的字节流。
// ...
char *filter_map = "filter_map";
// ...
map_fd = bpf_object__find_map_fd_by_name(obj, filter_map);
if (map_fd >= 0) {
err = bpf_map_update_elem(map_fd, &zero, filter, BPF_ANY);
if (err) {
printf("WARNING: map update elem %s error %d
", filter_map, err);
}
}
Tail Call尾调用Map
在eBPF Program加载部分提到,eBPF Kprobe函数kprobe/generic_kprobe(即generic_kprobe_event())作为统一的过滤处理网关,针对不同的kprobe,其参数个数、参数类型一定是不一样的,比如文件读写函数__x64_sys_write有三个参数,分别是
args:
- index: 0
type: "fd"
- index: 1
type: "char_buf"
sizeArgIndex: 3
- index: 2
type: "size_t"
而SOCKET连接函数__x64_connect只有两个参数,分别是
args:
- index: 0
type: "sockfd"
- index: 1
type: "sockaddr"
并且,他们的参数类型也不一样,作为统一网关,且面对参数个数、参数类型都不一样的问题,Tetragon在eBPF的解决方案是使用BPF_MAP_TYPE_PROG_ARRAY类型的eBPF Map实现,用于尾调用Tail Call处理。,
kprobe_calls尾调用Map
struct bpf_map_def __attribute__((section("maps"), used)) kprobe_calls = {
.type = BPF_MAP_TYPE_PROG_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(__u32),
.max_entries = 11,
};
kprobe_calls Map写入
map_bpf = bpf_object__find_map_by_name(obj, "kprobe_calls");
// ...
err = bpf_map__pin(map_bpf, map_name);
// ...
map_fd = bpf_map__fd(map_bpf);
for (i = 0; i < 11; i++) {
struct bpf_program *prog;
char prog_name[20];
char pin_name[200];
int fd;
snprintf(prog_name, sizeof(prog_name), "kprobe/%i", i);
prog = bpf_object__find_program_by_title(obj, prog_name);
if (!prog)
goto out;
fd = bpf_program__fd(prog);
if (fd < 0) {
err = errno;
goto err;
}
snprintf(pin_name, sizeof(pin_name), "%s_%i", __prog, i);
bpf_program__unpin(prog, pin_name);
err = bpf_program__pin(prog, pin_name);
if (err) {
printf("program pin %s tailcall err %d
", pin_name, err);
goto err;
}
err = bpf_map_update_elem(map_fd, &i, &fd, BPF_ANY);
if (err) {
printf("map update elem i %i %s tailcall err %d %d
", i, prog_name, err, errno);
goto err;
}
}
用户空间程序,读取eBPF二进制文件,读取kprobe开头的的eBPF函数,以ID作为Key,写入到kprobe_calls尾调用表中。
一共11个函数,都在bpf/process/bpf_generic_kprobe.c文件里,分别是:
- kprobe/0 对应 generic_kprobe_process_event0
- kprobe/1 对应 generic_kprobe_process_event1
- kprobe/2 对应 generic_kprobe_process_event2
- kprobe/3 对应 generic_kprobe_process_event3
- kprobe/4 对应 generic_kprobe_process_event4
- kprobe/5 对应 generic_kprobe_process_filter
- kprobe/6 对应 generic_kprobe_filter_arg1
- kprobe/7 对应 generic_kprobe_filter_arg2
- kprobe/8 对应 generic_kprobe_filter_arg3
- kprobe/9 对应 generic_kprobe_filter_arg4
- kprobe/10 对应 generic_kprobe_filter_arg5
至此,涉及eBPF阻断功能的用户空间逻辑全部完成。
内核空间
在内核空间,入口函数为用户空间HOOK的kprobe点 "kprobe/generic_kprobe" ,对应 generic_kprobe_event() 函数。这函数内部只有一个 **generic_kprobe_start_process_filter()**的调用。
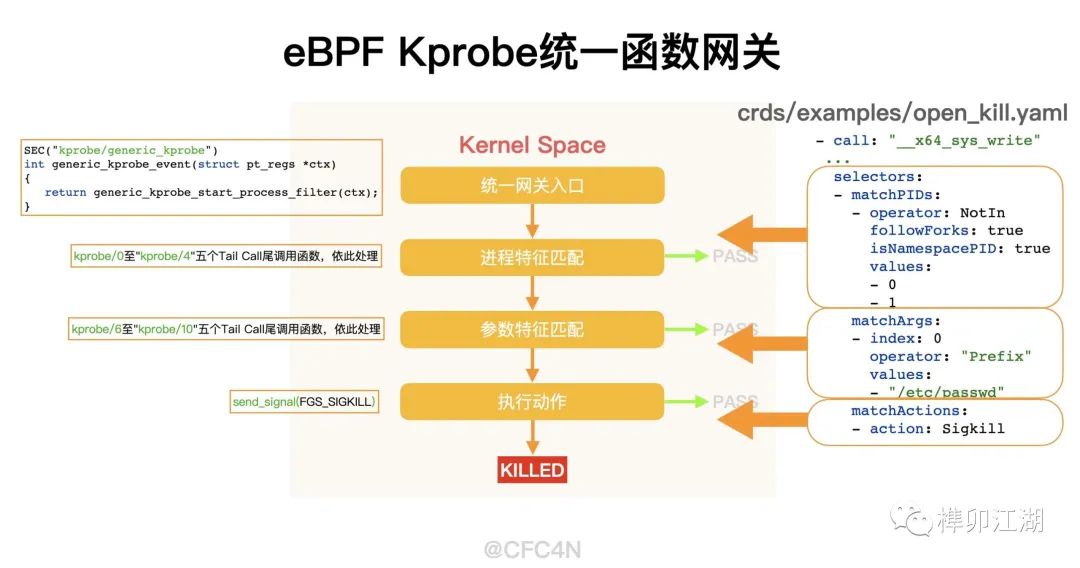
统一网关触发
前面提到,tetragon是把open_kill.yaml中的所有kprobe syscall都交给这个eBPF函数处理,所以,当__x64_sys_write这些HOOK点触发后,逻辑都交给generic_kprobe_start_process_filter()处理。
// bpf/process/bpf_generic_kprobe.c#line=48
static inline __attribute__((always_inline)) int
generic_kprobe_start_process_filter(void *ctx)
{
// ...
/* Tail call into filters. */
tail_call(ctx, &kprobe_calls, 5);
return 0;
}
程序内部获取当前进程信息(struct task_struct、namespace、caps等)后,使用Tail Call尾调用转交kprobe_calls Maps的第5个函数处理,即generic_kprobe_process_filter()。
提醒
因eBPF虚拟机寄存器限制,只能获取前5个参数。
进程过滤流程
获取当前进程信息后,进入下一个流程,获取当前kprobe的进程参数。即进入generic_kprobe_process_filter()函数内部
// bpf/process/bpf_generic_kprobe.c#Line=146
// ...
ret = generic_process_filter(msg, &filter_map, &process_call_heap);
if (ret == PFILTER_CONTINUE)
tail_call(ctx, &kprobe_calls, 5);
else if (ret == PFILTER_ACCEPT)
tail_call(ctx, &kprobe_calls, 0);
/* If filter does not accept drop it. Ideally we would
* log error codes for later review, TBD.
*/
return PFILTER_REJECT;
这里对kprobe所在进程信息,以及配置文件中信息匹配,判断是否要走过滤、阻断流程。流程逻辑如下
PFILTER_ACCEPT 逐个进入5类进程event事件判断
- generic_process_event0()
- generic_process_event1()
- generic_process_event2()
- generic_process_event3()
- generic_process_event4()
- generic_kprobe_filter_arg1()
PFILTER_CONTINUE直接进入参数判断
- generic_kprobe_filter_arg1()
OTHER 其他情况
直接返回PFILTER_REJECTeBPF HOOK流程。
参数判断流程
当前kprobe函数是否需要过滤判断完成后,流程转入真正的判断逻辑中,即tailcals尾调用的第6个函数处理,即generic_kprobe_filter_arg1()
__attribute__((section(("kprobe/6")), used)) int
generic_kprobe_filter_arg1(void *ctx)
{
return filter_read_arg(ctx, 0, &process_call_heap, &filter_map,
&kprobe_calls, &override_tasks);
}
其中,核心处理函数为filter_read_arg(),第四个参数&filter_map就是来自用户空间解析yaml的filters bytes数组。
filter_read_arg()函数判断触发当前kprobe的进程filter配置,若没找到,则调用kprobe/7至kprobe/9的尾调用函数,逐个查找filter配置。
阻断动作执行
当找到filter配置后,则读取配置中相应的action参数类型,开始进行相应动作分类判断,执行相关流程逻辑,这块都是在__do_action()函数中完成的。

actions = (struct selector_action *)&f[actoff];
postit = do_actions(e, actions, override_tasks);
action动作的类型有下面几种
- ACTION_POST = 0,
- ACTION_FOLLOWFD = 1,
- ACTION_SIGKILL = 2,
- ACTION_UNFOLLOWFD = 3,
- ACTION_OVERRIDE = 4,
每个action动作类型都有相应的处理逻辑,本文重点是阻断的实现,那么只需要关注ACTION_SIGKILL类型。
static inline __attribute__((always_inline)) long
__do_action(long i, struct msg_generic_kprobe *e,
struct selector_action *actions, struct bpf_map_def *override_tasks)
{
int action = actions->act[i];
switch (action) {
case ACTION_UNFOLLOWFD:
case ACTION_FOLLOWFD:
// ...
break;
case ACTION_SIGKILL:
if (bpf_core_enum_value(tetragon_args, sigkill))
send_signal(FGS_SIGKILL);
break;
case ACTION_OVERRIDE:
default:
break;
}
if (!err) {
e->action = action;
return ++i;
}
return -1;
}
可以看到,针对类型,是调用了send_signal()函数进行下发FGS_SIGKILL指令给当前进程,完整阻断动作。send_signal()函数是ebpf的内置函数,在Kernel 5.3版本[5]里增加。
阻断演示视频可以到CNCF (Cloud Native Computing Foundation)的油管观看:Real Time Security - eBPF for Preventing attacks - Liz Rice, Isovalent[6]
LSM HOOK比较LSM类HOOK是在Kernel 5.7以后才添加。阻断功能的实现,Tetragon选择send_signal()的方式,有着兼容更多内核版本的优势。并且其kprobe的HOOK点上,可以实现网关式通用处理,通过配置方式,更灵活地变更HOOK点,避免更新eBPF字节码的方式。
- 更灵活
- 网关式
- 内核版本覆盖多
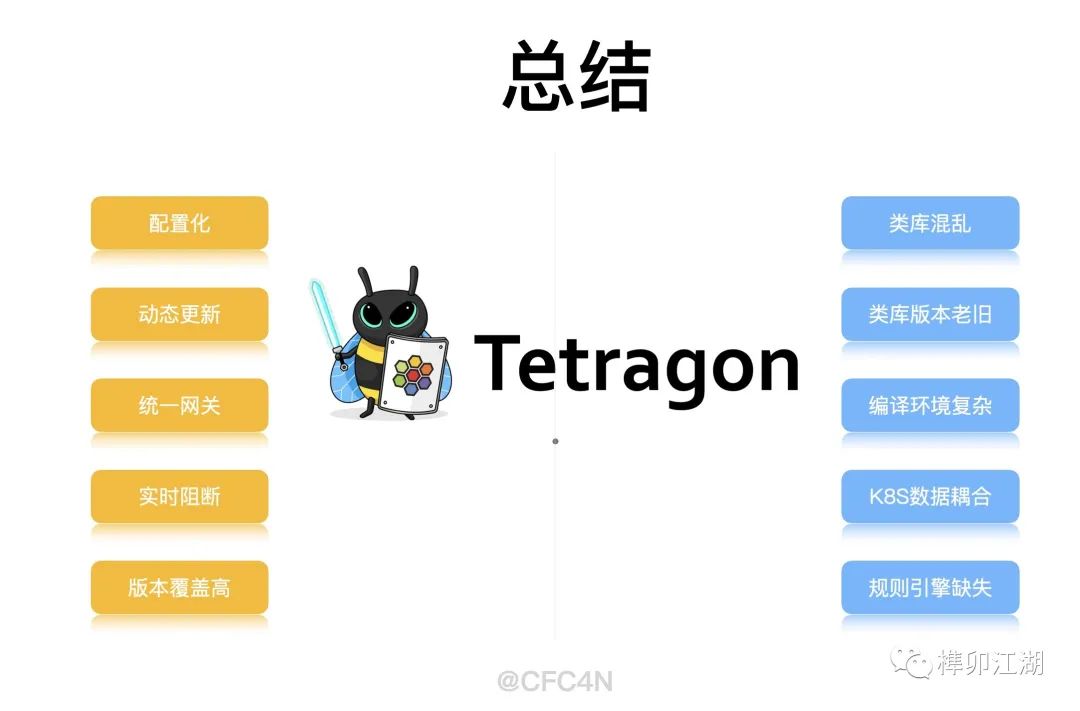
总结
Tetragon是一个实时识别阻断的运行时防护系统。具备网关式统一处理抓手,可以覆盖更多内核版本,通过配置文件方式灵活变更HOOK点。在eBPF技术支持下,还具备热挂载,系统稳定性高,程序可靠性高等特点。是主机运行时防护系统HIDS的最佳学习项目。
笔者水平有限,若有错误,欢迎指出,谢谢。
Tetragon阻断争论
2022年5月,云原生安全公司Isovalent的CTO宣布开源了其内部开发了多年的基于eBPF安全监控和阻断的方案:Tetragon。称可以防御容器逃逸的Linux内核漏洞。
安全研究人员Felix Wilhelm的质疑,在Tetragone: A Lesson in Security Fundamentals[7]认为可以轻易绕过,并用CVE-2021-22555[8]漏洞修改版演示。
这篇文章从标题上都充满了各种嘲讽,Tetragon单词加了e,大概是gone的谐音吧。grsecurity是linux 内核安全经验非常深厚的大厂,对这个领域比较精通。但Tetragon的优势并不是内核底层安全能力。
赛博堡垒(HardenedVault)也撰写一篇文章,云原生安全Tetragon案例之安全产品自防护[9] 认为该产品必定失败。
随着云原生的流行,Linux内核安全成为了一个无法绕开的问题,某个容器被攻陷后可以向Linux内核发起攻击,一旦成功则整个主机都会被攻击者控制,如果你不想你的产品耗资上百万美金后攻击者两个小时就攻陷的话,那应该认真的考虑是否应该从一开始就建立正确的威胁模型。另外,eBPF机制更适合实现审计监控类的安全方案而非防护阻断类,VED的eBPF版本也仅仅是为审计而设计,剩下的事情你应该让SIEM和SOC团队去做,在安全流程上我们也应该遵循KISS(Keep it simple, stupid!)原则,不是吗?
我的看法
针对漏洞利用的方法(注:不是漏洞)的防御机制通常会针对三个阶段:
- Pre-exploitation(前漏洞利用阶段)
- Exploitation(漏洞利用阶段)
- Post-exploitation(后漏洞利用阶段)
Tetragon的阻断功能是在Exploitation漏洞利用阶段生效的,因为是可以直接阻断,让此次漏洞攻击失败。其次,认可几位安全人员的关于Tetragon适用场景说法,更适合阻断用户空间的内核逃逸漏洞。
否定的声音来自底层防御的传统厂商,其实他们没明白,Tetragon的优势是可以动态、轻量、无感知的提升防御能力,并不是完全防御所有攻击方式。
业务优先于安全
在云原生领域,业务类型多数是web服务,安全级别不需要那么高,硬件宿主机重启成本较高,性能要求大,业务优先,安全其次。过于严格的安全检测,占用过多资源,影响业务运行速度,性价比低,成本高。这是云原生场景不能接受的。但偶尔的入侵行为是能容忍的。所以业务优先级大于安全是第一守则。
安全优先于业务
传统安全厂商的产品对系统稳定性、可用性、性能都有较大影响,且存在热更新的难题,哪怕解决了,依旧是特别重的方案。在轻量、动态、热更新的需求下,显得特别笨重。
机密数据库等保密程度较高的服务器,数据安全大于业务功能,愿意牺牲性能换取安全性,那么这种场景适合传统安全厂商的产品。这种场景的规则是安全优先级大于业务,更适合传统安全厂商发挥。
争议总结
当今互联网的服务器市场中,云原生业务占比越来越高,这将会是Tetragon、Falco、Tracee、Datadog等运行时安全产品愈加内卷的动力。
对于用户来说,根据自己的业务特性,选择相应的防御检测产品,满足自己业务需求。
原文标题:Tetragon阻断争论
文章出处:【微信公众号:一口Linux】欢迎添加关注!文章转载请注明出处。
-
 jf_65140927
2023-02-10
0 回复 举报厉害!!多谢分享! 收起回复
jf_65140927
2023-02-10
0 回复 举报厉害!!多谢分享! 收起回复
-
如何缩短Vivado的运行时间2019-05-29 15724
-
云原生技术概述 云原生火爆成为升职加薪核心必备2022-07-27 2108
-
如何检查Linux服务器的运行时间2022-11-25 15967
-
只需 6 步,你就可以搭建一个云原生操作系统原型2022-09-15 11204
-
紫金桥组态软件新的功能_运行时组态2017-10-13 1266
-
2021年最热门的云原生存储解决方案之一:容器原生存储2021-01-06 3606
-
如何高效测量ECU的运行时间2021-10-28 3365
-
Go运行时:4年之后2022-11-30 1765
-
如何在AUTOSAR OS系统运行时使用事件Event呢?2023-05-22 3958
-
ch32v307记录程序运行时间2023-08-22 2036
-
Xilinx运行时(XRT)发行说明2023-09-14 818
-
如何保证它们容器运行时的安全?2023-11-03 1732
-
jvm运行时内存区域划分2023-12-05 1317
-
三菱plc累计运行时间怎么编程2024-06-20 5532
-
什么是云原生MLOps平台2024-12-12 1226
全部0条评论

快来发表一下你的评论吧 !
