

GPU计算对嵌入式应用产生影响
描述
与中央处理单元 (CPU) 相比,图形处理单元 (GPU) 更适合以更高分辨率和更快的帧速率形成图像,因为 GPU 具有数百个可以并行处理数千个数据集的计算单元。并行数据结构和高线程数使 GPU 本质上更适合需要大量计算功能的应用,例如医学成像和视频游戏,例如并发可视化和交互式分割。
容纳 CPU 和 GPU 的多核处理器设计已经存在多年。事实上,几乎每台笔记本电脑、智能手机和平板电脑现在都拥有多核处理器、集成 GPU 和许多其他加速器,用于音频、网络和其他功能。然而,在这些多核处理器设计中,GPU 通常不直接访问应用程序内存,因此充当 CPU 的从属设备。
几年前,AMD 引入了加速处理器单元 (APU) 的概念,该单元为处理器内部的 CPU 和 GPU 结合了高速缓存一致性内存。将两个处理单元组合在同一条总线上以提高处理器吞吐量的想法最终导致了2012 年异构系统架构 (HSA) 基金会的创建。
HSA 中的一组标准和规范促进了 CPU、GPU 和其他加速器的公共总线和共享内存,以使这些截然不同的架构协同工作。AMD、ARM、联发科和德州仪器等行业领导者参与了这项工作,这标志着现有多核处理器设计方法的重大突破。
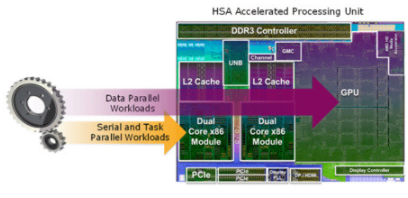
1. HSA 将现有的异构计算提升到一个新的水平。
首先,HSA 1.0 旨在通过自动将计算从 CPU 卸载到 GPU 来释放 GPU 在嵌入式计算中的潜力,反之亦然。通过使软件能够以更低的延迟和显着降低的开销有效地将任务分配给 GPU,HSA 允许 GPU 任务通过共享虚拟内存功能 (SVM) 直接安全地访问系统内存中的数据,并在应用程序进程中遍历数据结构内存(ptr-is-ptr)。现在,这一切都可以完成,而无需像以前在传统 GPU 计算 API 中所要求的那样提供数据缓冲区的主机 CPU 配置。
即将发布的 HSA 标准将数字信号处理器 (DSP) 集成到架构中,并提高了与系统中非 HSA 启用的可编程和固定功能加速器的高效互操作性。
接下来,虽然 HSA 是OpenCL等通用 GPU (GPGPU) API 的重要基础,但凭借其细粒度和粗粒度共享虚拟内存功能,许多高级语言已被移植和优化为原生目标 HSA 平台,包括 C++ 17、GCC、LLVM/CLANG 和 Python。优化 CAFFE、BLAS、CHARM++、FFT、Sparse、FLAME 和 Docker 等软件框架的工作也在进行中,以使开发人员更容易直接高效地编程和使用异构并行设备。
这些异构计算环境创造的这种新的处理器效率水平正在重振医疗和打印成像等行业。直到最近,需要图像配准、图像分割和图像去噪等计算密集型工作的医学成像产品在很大程度上以牺牲图像质量为代价来牺牲帧速率。
HSA 以其创新的机制为不同的处理核心分配不同的负载,从而实现具有强大可视化和图像保真度的高效计算。现在有大量资源可用于帮助开发人员调整或创建新应用程序以利用异构架构。其中包括 HSA Foundation GitHub 存储库和Radeon 开放计算解决方案 GitHub。后者将 HSA 编程模型扩展到高性能离散 GPU,并包括CodeXL 2.0 中提供的强大的开源调试和分析工具。
计算密集型医疗领域可以受益于 GPU 加速,以增强特定于 MRI、PET、超声和显微镜等应用的算法的执行。
2. GPU 加速提供卓越的速度,可有效满足医学成像独特的数据吞吐量和后处理需求。
具体来说,教程是异构系统架构——下一代异构计算的基础,以及医疗和打印成像中的 GPU 计算,而小组的主题是异构系统架构:未来的功率、性能和编程。
-
讨论几种类型的嵌入式计算机系统2021-12-23 2270
-
嵌入式系统设计|嵌入式计算2021-11-03 908
-
什么是嵌入式计算机2021-10-27 2226
-
计算机网络与嵌入式系统,嵌入式系统与计算机系统有什么不同2021-10-21 1188
-
微型计算机是嵌入式吗,什么是嵌入式计算机2021-10-20 1491
-
嵌入式系统EMC的产生原理是什么?2019-08-20 2233
-
嵌入式计算产品2019-07-16 2334
-
突破图形和计算性能的极限!面向最新应用的旗舰型嵌入式GPU2019-06-20 3610
-
面向嵌入式应用的系列GPU2019-06-16 4729
-
嵌入式系统组成和功能特点有哪些2017-06-30 3525
-
APU与GPU共进 AMD抢攻嵌入式应用2014-03-06 1688
-
AMD发布嵌入式GPU E67602011-05-04 1528
-
汽车嵌入式计算平台的设计2010-07-02 576
全部0条评论

快来发表一下你的评论吧 !
