

Vitis HLS的基础知识科普
描述
Vitis HLS简介
VitisHLS是一种高层次综合工具,支持将C、C++和OpenCL函数硬连线到器件逻辑互连结构和RAM/DSP块上。
Vitis HLS可在Vitis应用加速开发流程中实现硬件内核,并使用C/C++语言代码在VivadoDesign Suite中为赛灵思器件设计开发RTL IP。
参考:《Vitis高层次综合用户指南》(UG1399)。
在 Vitis 应用加速流程中,在可编程逻辑中实现和最优化 C/C++ 语言代码以及实现低时延和高吞吐量所需的大部分代码修改操作均可通过 Vitis HLS 工具来自动执行。在应用加速流程中,Vitis HLS 的基本作用是通过推断所需的编译指示来为函数实参生成正确的接口,并对代码内的循环和函数执行流水打拍。Vitis HLS 还支持自定义代码以实现不同接口标准或者实现特定最优化以达成设计目标。
Vitis HLS 设计流程如下所述:
- 编译、仿真和调试 C/C++ 语言算法。
- 查看报告以分析和最优化设计。
- 将 C 语言算法综合到 RTL 设计中。
- 使用 RTL 协同仿真来验证 RTL 实现。
- 将 RTL 实现封装到已编译的对象文件 (.xo) 扩展中,或者导出到 RTL IP。
Vitis HLS 存储器布局模型
Vitis 应用加速开发流程提供了相应的框架,可通过使用标准编程语言来为软件和硬件组件开发和交付 FPGA 加速应用。软件组件或主机程序是使用 C/C++ 语言开发的,可在 x86 或嵌入式处理器上运行,借助 OpenCL 或 XRT 本机 API 调用来管理与加速器的运行时间交互。硬件组件或内核(在实际 FPGA 卡/平台上运行)则可使用 C/C++、OpenCL C 或 RTL 来开发。Vitis 软件平台有助于促进对异构应用的硬件和软件元素进行并发开发和测试。因此,在主机上运行的软件程序需要使用精确定义的接口和协议来与在 FPGA 硬件模型上运行的加速内核进行通信。因此,精确定义所使用的存储器模型以便正确处理读写的数据就显得尤为重要。存储器模型可以定义计算机存储器中排列和访问数据的方式。其中涉及两个独立但相关的问题:数据对齐和数据结构填充。此外,Vitis HLS 编译器支持指定特殊属性(和编译指示)来更改默认的数据对齐和数据结构填充规则。
数据对齐
软件程序员习惯于将存储器视为简单的字节阵列,而将基本数据类型视为是由一个或多个存储器块组成的。但计算机处理器并不会在单个字节大小的区块内对存储器执行读取和写入。现今的现代化 CPU 实际上每次访问 2、4、8、16 甚至是 32 字节的区块,虽说最常用的指令集架构 (ISA) 是 32 位和 64 位的。鉴于系统内存储器的组织方式,这些区块的地址应为其大小的倍数。如果地址满足此要求,则将其称为已对齐。高级程序员对于存储器的看法与现代化处理器实际处理存储器的方式之间的差别在应用程序的正确性和性能方面实际上是非常重要的。例如,如果您不了解软件中的地址对齐问题,那么就可能发生下列情况:
- 软件运行缓慢
- 应用将锁定/挂起
- 操作系统可能崩溃
- 软件将静默失败,产生错误结果
C++ 语言可以提供一系列不同大小的基本类型。为了能快速操作这些类型的变量,生成的对象代码将尝试使用能立即读取/写入整个数据类型的 CPU 指令。这也就意味着这些类型的变量在存储器内的布局方式应确保其地址能以合适方式保持对齐。由此导致每个基本类型除大小之外还有另一个属性:即对齐要求。基本类型的对齐可能看似与其大小相同。但实际情况往往并非如此,因为最适合特定类型的 CPU 指令可能每次只能访问其数据中的一部分。例如,32 位 x86 GNU/Linux 机器可能每次只能读取最多 4 个字节,因此,64 位 long long 类型的大小为 8,对齐为 4。下表显示了 C/C++ 中对应 32 位和 64 位 x86-64 GNU/Linux 机器的基本原生数据类型的大小和对齐(以字节数为单位)。
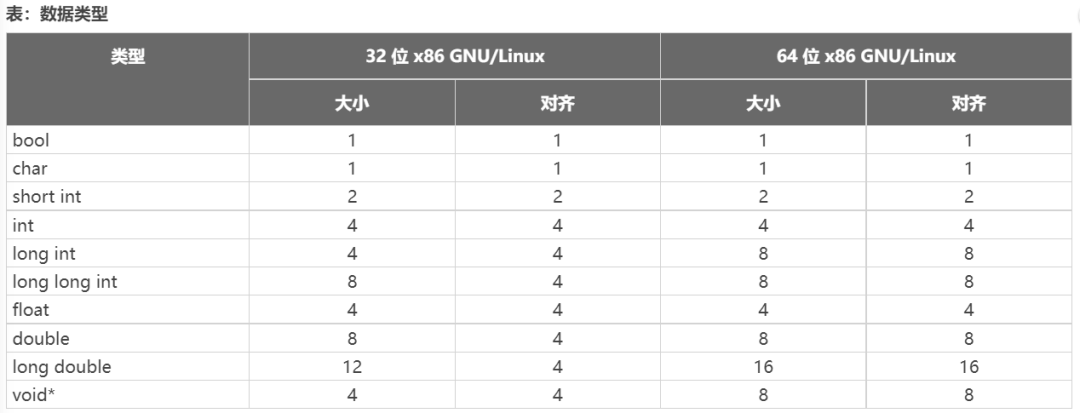
根据以上排列,程序员为什么需要更改对齐?原因有多个,但主要原因是在存储器要求与性能之间的取舍。在主机与加速器之间往返发送数据时,发射的每个字节都有成本。幸好,GCC C/C++ 编译器可提供语言扩展 ,用于为变量、结构/类或结构字段更改默认对齐(以字节数为单位来测量)。例如,以下声明会导致编译器在 16 字节边界上分配全局变量 x。
int x __attribute__ ((aligned (16))) = 0;
不会更改所应用到的变量的大小,而是可以更改结构的存储器布局,方法是在结构体的各元素之间插入填充。由此即可更改结构的大小。如果您在已对齐的属性中不指定对齐因子,那么编译器会将声明的变量或字段的对齐设置为要编译的目标机器上的任意数据类型所使用的最大对齐。这样通常能够提升复制操作的效率,因为编译器在对已通过这种方式对齐的变量或字段执行往来复制时,可以使用任何能复制最大存储器区块的指令。aligned 属性只能增大对齐,而不能减小对齐。C++ 函数 offsetof 可用于判定结构中每个成员元素的对齐。
数据结构填充
如 数据对齐(上一节) 中的表格所示,本地数据类型具有精心定义的对齐结构,但用户定义的数据类型的对齐结构又如何呢?C++ 编译器也需要确保结构体或类中的所有成员变量都正确对齐。为此,编译器可在成员变量之间插入填充字节。此外,为了确保用户定义的类型的阵列中的每个元素都对齐,编译器可以在最后一个数据成员之后添加额外的填充。请考量以下示例:

GCC 编译器始终假定 的实例的起始地址对齐到所有结构体成员的要求最严格的对齐地址处,在此例中,即 int。实际上,用户定义的类型的对齐要求正是以此方式计算所得的。假定存储器为 x86-64 对齐,其中 的对齐为 2,int 的对齐为 4,为了使 的 i 数据成员得以适当对齐,编译器需要在 s 与 i 之间插入 2 个额外的填充字节以创建对齐,如下图所示。同样,为了对齐数据成员 c,编译器需要在 c 之后插入 3 个字节。
对于 ,编译器将基于结构体元素的对齐方式推断总计大小为 12 个字节。但如果结构体的元素已重新排序(如 中所示),那么编译器现在即可推断得到较小的大小,即 8 个字节。
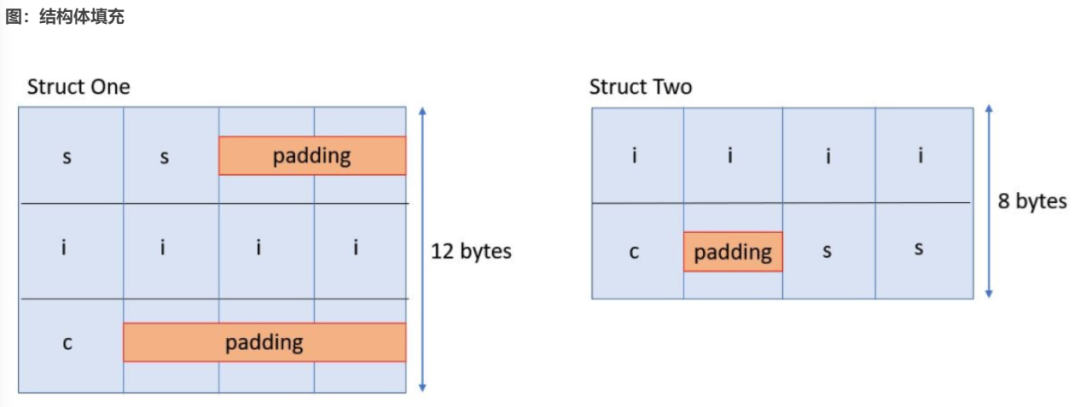
默认情况下,C/C++ 编译器将按结构体成员的声明顺序来完成这些成员的布局,在成员间或者最后一个成员之后可能按需插入填充字节,以确保每个成员都能正确对齐。但是,GCC C/C++ 编译器会提供语言扩展,以告知编译器不插入填充,而是改为允许结构体成员间不对齐。例如,如果系统正常情况下要求所有 int 对象都采用 4 字节对齐,那么使用 可能导致将 int 结构体成员分配至错误偏移处。
您必须审慎考量 的使用,因为访问未对齐的存储器可能导致编译器插入代码以逐个字节读取存储器,而不是一次性读取多个存储器区块。
Vitis HLS 对齐规则和语义
鉴于前述 GCC 编译器的行为,本节将详述 Vitis HLS 如何使用 aligned 和 packed 属性来创建高效硬件。首先,您需要了解 Vitis HLS 中的 聚合 和 解聚 功能特性。代码中的结构或类对象(例如,内部变量和全局变量)默认情况下处于解聚 (disaggregated) 状态。解聚暗示此结构/类已分解为多个不同对象,针对每个结构体/类成员各一个对象。创建的元素数量和类型取决于结构体本身的内容。结构体阵列作为多个阵列来实现,每个结构体成员都具有独立的阵列。
但默认情况下,用作为顶层函数的实参的结构体则保持聚合状态。聚合暗示任一结构体的所有元素都集合到一个单宽矢量内。这样即可同时读写结构体的所有成员。结构体的成员元素按 C/C++ 代码中所示顺序置于该矢量内:结构体的第一个元素对齐矢量的 LSB,结构体的最后一个元素对齐矢量的 MSB。结构体中的任意阵列都分区到独立阵列元素中,并按从低到高的顺序置于矢量内。
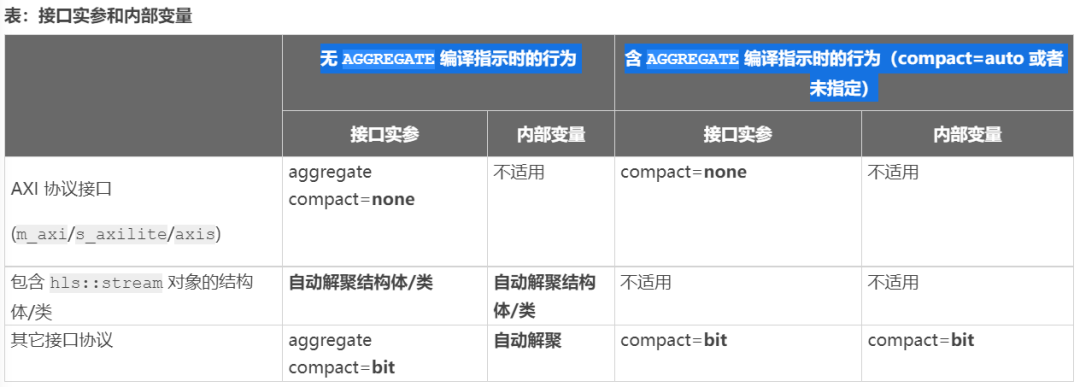
Vitis HLS 中的默认聚合目的是在硬件接口顶层使用 x86_64-gnu-linux 存储器布局,同时最优化内部硬件以提升结果质量 (QoR)。上表显示了 Vitis HLS 的默认行为。该表中显示了 2 种模式:用户不指定 编译指示(默认模式),和用户指定 编译指示的模式。
对于 AXI4 接口 (m_axi/s_axilite/axis),默认根据结构体元素对该结构进行填充,如 数据结构填充 中所述。这样即可将结构大小聚合为最接近 2 的幂值,并且在此情况下可应用部分填充。这样即可有效推断 编译指示上的 e 选项。
对于其它接口协议,按位级来对结构体进行封装,以便根据该结构体所含的各元素来调整聚合的矢量的大小。这样即可有效推断 编译指示上的 选项。
以上规则的唯一例外是在接口中以间接方式使用 时(即,在结构体/类内部使用 对象,随后将此结构体/类用作为接口端口的类型)。包含 对象的结构体将始终解聚为其各独立成员元素。
聚合示例
聚合存储器映射接口
这是 m_axi 接口的 AGGREGATE 编译指示或指令的示例。
struct A {
char foo; // 1 byte
short bar; // 2 bytes
};
int dut(A* arr) {
#pragma HLS interface m_axi port=arr depth=10
#pragma HLS aggregate variable=arr compact=auto
int sum = 0;
for (unsigned i=0; i<10; i++) {
auto tmp = arr[i];
sum += tmp.foo + tmp.bar;
}
return sum;
}
对于以上示例,m_axi 接口端口 arr 的大小为 3 个字节(或 24 位),但由于 编译指示的作用,该端口的大小将对齐到 4 个字节(或 32 位),因为这是最接近的 2 的幂值。Vitis HLS 将在 log 日志文件中发出以下消息:<Vitis HLS 2021.1 GUI 中有哪些新功能?>
INFO: [HLS 214-241] Aggregating maxi variable 'arr' with compact=none mode in 32-bits (example.cpp0)
仅当使用 AGGREGATE 编译指示时,才会发出以上消息。但即使不使用编译指示,该工具仍将自动聚合接口端口 arr 并将其填充至 4 个字节,这是 AXI 接口端口的默认行为。
在接口上聚合结构体
这是 ap_fifo 接口的 AGGREGATE 编译指示或指令的示例。
struct A {
int myArr[3]; // 4 bytes per element (12 bytes total)
ap_int<23> length; // 23 bits
};
int dut(A arr[N]) {
#pragma HLS interface ap_fifo port=arr
#pragma HLS aggregate variable=arr compact=auto
int sum = 0;
for (unsigned i=0; i<10; i++) {
auto tmp = arr[i];
sum += tmp.myArr[0] + tmp.myArr[1] + tmp.myArr[2] + tmp.length;
}
return sum;
}
对于 ap_fifo 接口,无论是否使用聚合编译指示,结构体都将在位级进行封装。
在以上示例中,AGGREGATE 编译指示将为端口 arr 创建大小为 119 位的端口。阵列 myArr 将取 12 个字节(或 96 位),元素 length 将取 23 位,总计 119 位。Vitis HLS 将在 log 日志文件中发出以下消息:《Xilinx HLS 导出IP失败的最新解决方案(2022.1.15)》
INFO: [HLS 214-241] Aggregating fifo (array-to-stream) variable 'arr' with compact=bit mode
in 119-bits (example.cpp0)
聚合嵌套结构体端口
这是 Vivado IP 流程中 AGGREGATE 编译指示或指令的示例。
#define N 8
struct T {
int m; // 4 bytes
int n; // 4 bytes
bool o; // 1 byte
};
struct S {
int p; // 4 bytes
T q; // 9 bytes
};
void top(S a[N], S b[N], S c[N]) {
#pragma HLS interface bram port=c
#pragma HLS interface ap_memory port=a
#pragma HLS aggregate variable=a compact=byte
#pragma HLS aggregate variable=b compact=bit
#pragma HLS aggregate variable=c compact=byte
for (int i=0; i
在以上示例中,聚合算法将为端口 a 和端口 c 创建大小为 104 位的端口,因为在聚合编译指示中已指定 compact=byte 选项,但针对端口 b 使用默认选项 compact=bit,其打包大小将为 97 位。嵌套的结构 S 和 T 将聚合以包含 3 个 32 位成员变量(p、m 和 n)以及 1 个位/字节成员变量 (o)。
注意:此示例使用 Vivado IP 流程来演示聚合行为。在 Vitis 内核流程中,端口 b 将自动推断为 m_axi 端口,故而将不允许使用 compact=bit 设置。
<【Vivado那些事儿】高层次综合技术(HLS)原理浅析>
Vitis HLS 将在 log 日志文件中发出以下消息:
INFO: [HLS 214-241] Aggregating bram variable 'b' with compact=bit mode in 97-bits (example.cpp0)
INFO: [HLS 214-241] Aggregating bram variable 'a' with compact=byte mode in 104-bits (example.cpp0)
INFO: [HLS 214-241] Aggregating bram variable 'c' with compact=byte mode in 104-bits (example.cpp0)
解聚示例
解聚 AXIS 接口
这是 axis 接口的 DISAGGREGATE 编译指示或指令的示例。
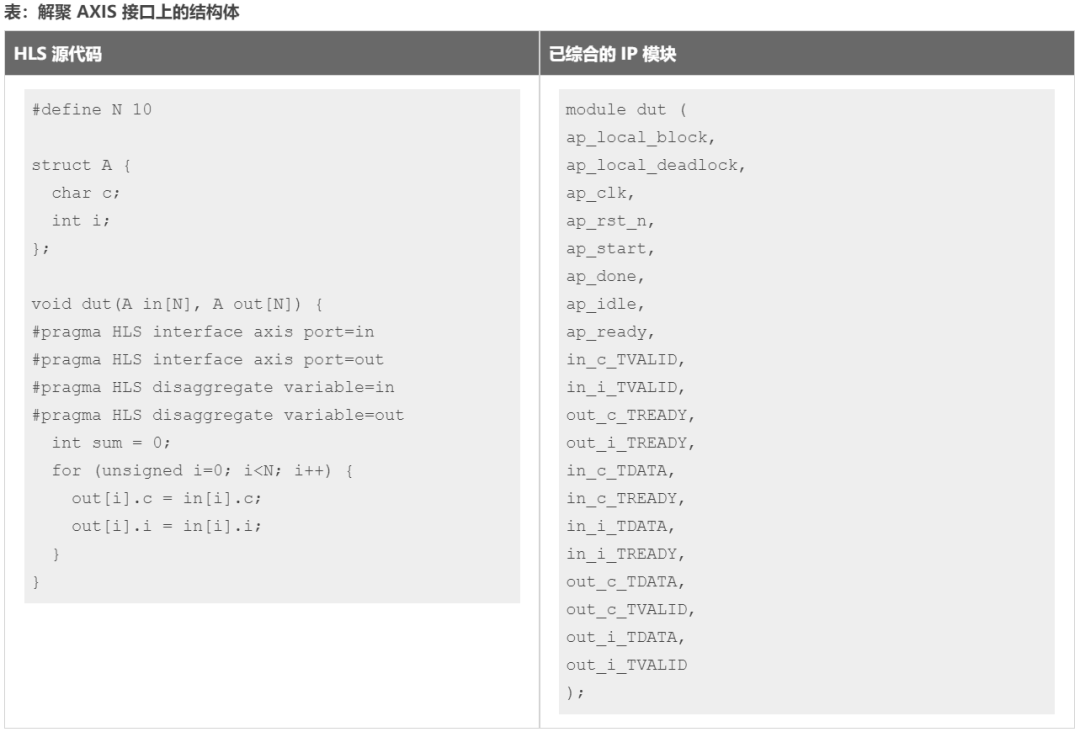
在以上解聚示例中,结构体实参 in 和 out 均映射到 AXIS 接口,然后进行解聚。这导致 Vitis HLS 为每个实参创建 2 条 AXI 串流:in_c、in_i、out_c 和 out_i。结构体 A 的每个成员都各成一条独立串流。
生成的模块的 RTL 接口显示在上表右侧,其中成员元素 c 和 i 均为独立 AXI 串流端口,每个端口都有自己的 TVALID、TREADY 和 TDATA 信号。
Vitis HLS 将在 log 日志文件中发出以下消息:
INFO: [HLS 214-210] Disaggregating variable 'in' (example.cpp0)
INFO: [HLS 214-210] Disaggregating variable 'out' (example.cpp0)
解聚 HLS::STREAM
这是搭配 hls::stream 类型一起使用的 DISAGGREGATE 编译指示或指令的示例。
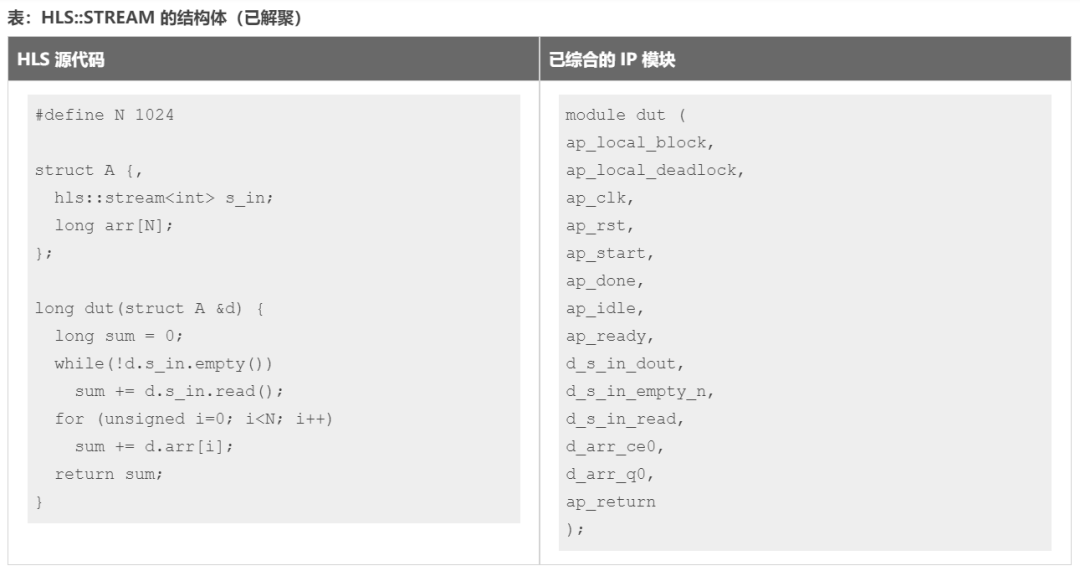
如果在用于接口中的结构内部使用 hls::stream 对象,则会导致 Vitis HLS 编译器将该结构体端口自动解聚。如以上示例所示,生成的 RTL 接口将为 hls::stream 对象 s_in 包含独立的 RTL 端口(名为 d_s_in_*),并为阵列 arr 包含独立的 RTL 端口(名为 d_arr_*)。
Vitis HLS 将在 log 日志文件中发出以下消息:
INFO: [HLS 214-210] Disaggregating variable 'd'
INFO: [HLS 214-241] Aggregating fifo (hls::stream) variable 'd_s_in' with compact=bit mode in 32-bits
结构体大小对于流水打拍的影响
函数接口中使用的结构体的大小对于循环中的流水打拍可能存在不利影响,主要影响的是有权访问函数主体中的接口的函数。以下列包含 2 个 M_AXI 接口的代码为例:
struct A { /* Total size = 192 bits (32 x 6) or 24 bytes */
int s_1;
int s_2;
int s_3;
int s_4;
int s_5;
int s_6;
};
void read(A *a_in, A buf_out[NUM]) {
READ:
for (int i = 0; i < NUM; i++)
{
buf_out[i] = a_in[i];
}
}
void compute(A buf_in[NUM], A buf_out[NUM], int size) {
COMPUTE:
for (int j = 0; j < NUM; j++)
{
buf_out[j].s_1 = buf_in[j].s_1 + size;
buf_out[j].s_2 = buf_in[j].s_2;
buf_out[j].s_3 = buf_in[j].s_3;
buf_out[j].s_4 = buf_in[j].s_4;
buf_out[j].s_5 = buf_in[j].s_5;
buf_out[j].s_6 = buf_in[j].s_6 % 2;
}
}
void write(A buf_in[NUM], A *a_out) {
WRITE:
for (int k = 0; k < NUM; k++)
{
a_out[k] = buf_in[k];
}
}
void dut(A *a_in, A *a_out, int size)
{
#pragma HLS INTERFACE m_axi port=a_in bundle=gmem0
#pragma HLS INTERFACE m_axi port=a_out bundle=gmem1
A buffer_in[NUM];
A buffer_out[NUM];
#pragma HLS dataflow
read(a_in, buffer_in);
compute(buffer_in, buffer_out, size);
write(buffer_out, a_out);
}
在以上示例中,结构体 A 的大小为 192 位,这并非 2 的幂。如前文所述,默认情况下,所有 AXI4 接口大小均设为 2 的幂。Vitis HLS 将自动把这 2 个 M_AXI 接口(a_in 和 a_out)的大小调整为 256 - 即与 192 位大小最接近的 2 的幂值(并在 log 日志文件中报告此行为,如下所示)。
INFO: [HLS 214-241] Aggregating maxi variable 'a_out' with compact=none mode in
256-bits (example.cpp0)
INFO: [HLS 214-241] Aggregating maxi variable 'a_in' with compact=none mode in 256-bits
(example.cpp0)
这其中隐含的意义是在写入结构数据并输出时,首次写入将在一个周期内把 24 个字节写入第一个缓冲器,但第二次写入将必须把 8 个字节写入第一个缓冲器内的剩余 8 个字节,然后将 16 个字节写入第二个缓冲器,这样就会生成 2 次写入,如下图所示。
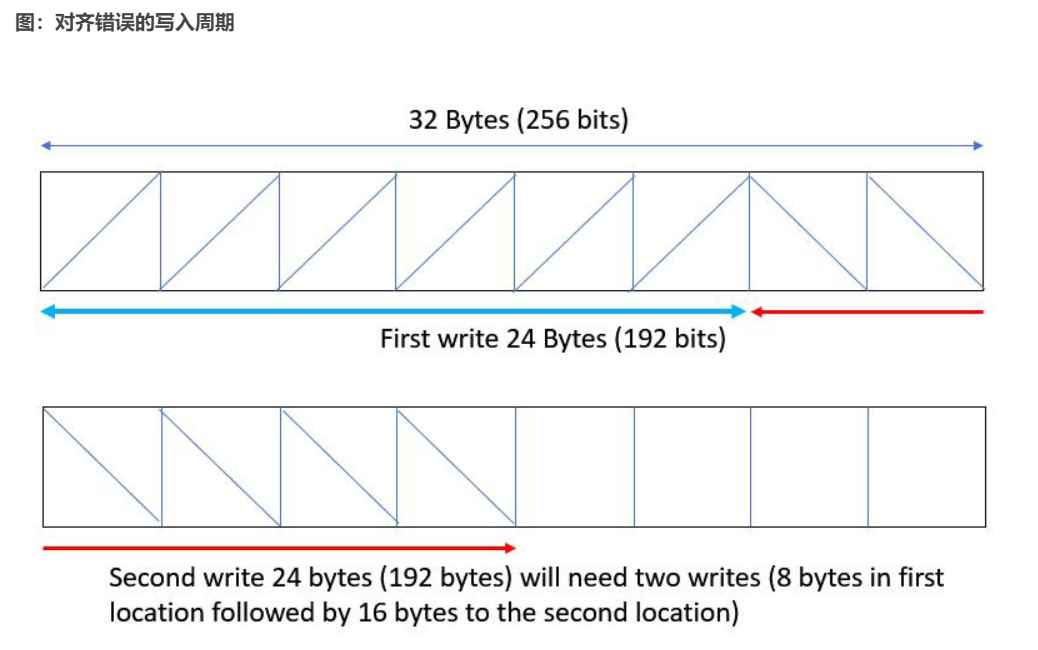
这将导致函数 write() 中的 WRITE 循环的 II 发生 II 违例,因为它需要 II=2 而不是 II=1。读取时也会发生类似的行为,因此 read() 函数同样会发生 II 违例,因为它需要 II=2。Vitis HLS 将为函数 read() 和 write() 中的 II 违例发出以下警告:
WARNING: [HLS 200-880] The II Violation in module 'read_r' (loop 'READ'): Unable
to enforce a carried dependence constraint (II = 1, distance = 1, offset = 1) between
bus read operation ('gmem0_addr_read_1', example.cpp:23) on port 'gmem0' (example.cpp:23)
and bus read operation ('gmem0_addr_read', example.cpp:23) on port 'gmem0' (example.cpp:23).
WARNING: [HLS 200-880] The II Violation in module 'write_Pipeline_WRITE' (loop 'WRITE'):
Unable to enforce a carried dependence constraint (II = 1, distance = 1, offset = 1)
between bus write operation ('gmem1_addr_write_ln44', example.cpp:44) on port 'gmem1'
(example.cpp:44) and bus write operation ('gmem1_addr_write_ln44', example.cpp:44) on
port 'gmem1' (example.cpp:44).
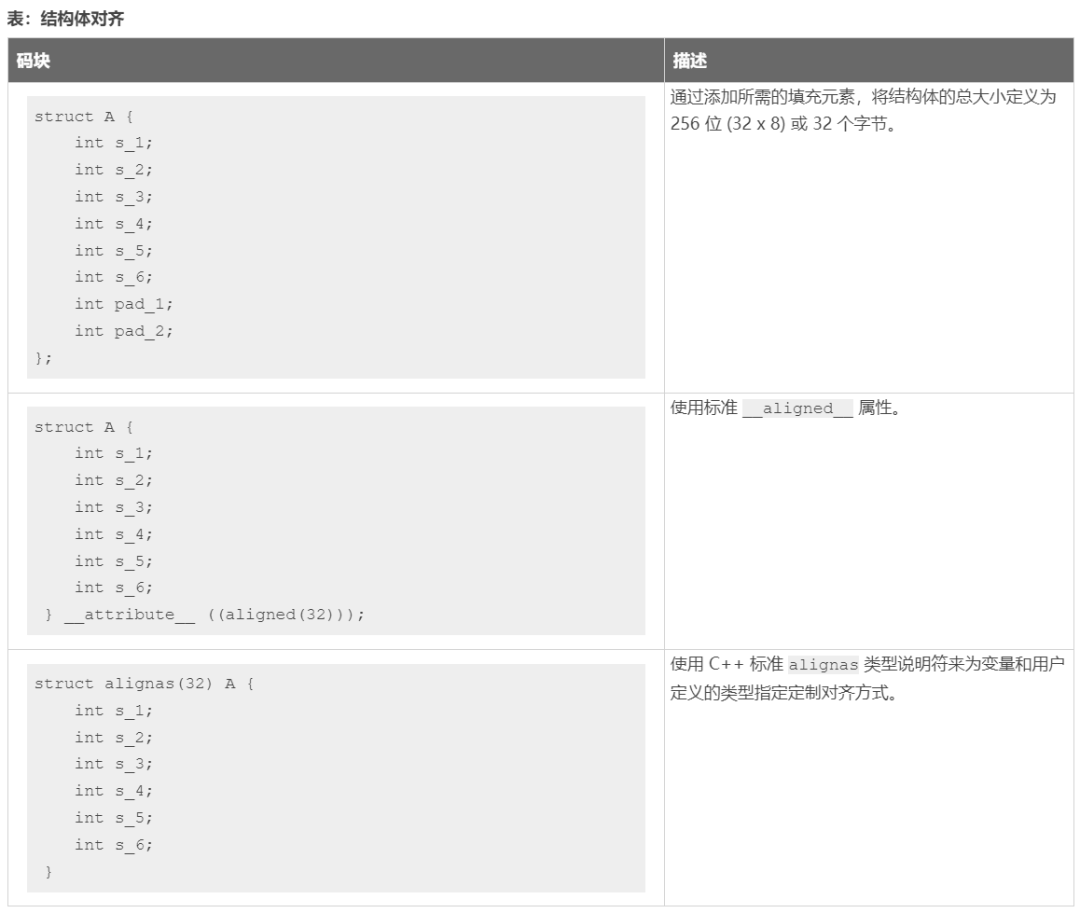
修复此类 II 问题的方法是以 8 个额外字节填充结构体 A,这样即可始终同时写入 256 位(32 个字节),或者使用下表所示的其它替代方法。这将允许调度器在 READ/WRITE 循环内按 II=1 来调度读/写。
教程与示例
为帮助您快速上手 Vitis HLS,您可在以下位置找到教程与应用示例:
-
Vitis HLS 简介示例 (https://github.com/Xilinx/Vitis-HLS-Introductory-Examples)包含许多小型代码示例,用于演示良好的设计实践、编码指南、常用应用的设计模式以及(最重要的)最优化技巧,从而最大程度提升应用性能。所有示例都包含 README 文件和 run_hls.tcl 脚本以帮助您使用示例代码。
-
Vitis 加速示例仓库 (https://github.com/Xilinx/Vitis_Accel_Examples)包含示例,用于演示 Vitis 工具和平台的各项功能特性。此仓库提供了小型有效示例,用于演示与 Vitis 应用加速开发流程的主机代码和内核编程相关的具体案例。这些示例中的内核代码均可在 Vitis HLS 中直接编译。
-
Vitis 应用加速开发流程教程 (https://github.com/Xilinx/Vitis-Tutorials)提供多种教程,通过这些教程可以教授有关工具流程和应用开发的具体概念,包括将 Vitis HLS 作为独立应用来使用的方式,以及在 Vitis 自下而上的设计流程中使用该工具的方式。
原文标题:Vitis HLS简介
文章出处:【微信公众号:OpenFPGA】欢迎添加关注!文章转载请注明出处。
-
使用AMD Vitis Unified IDE创建HLS组件2025-06-20 2906
-
如何使用AMD Vitis HLS创建HLS IP2025-06-13 2597
-
Vitis HLS移植指南2023-09-13 687
-
如何在Vitis HLS GUI中使用库函数?2023-08-16 2750
-
AMD全新Vitis HLS资源现已推出2023-04-23 2136
-
HLS最全知识库2023-01-15 4757
-
使用Vitis HLS创建属于自己的IP相关资料分享2022-09-09 5617
-
FPGA高层次综合HLS之Vitis HLS知识库简析2022-09-07 3940
-
Vitis HLS知识库总结2022-09-02 5257
-
Vitis HLS前端现已全面开源2022-08-03 1982
-
Vitis HLS工具简介及设计流程2022-05-25 3956
-
基于Vitis HLS的加速图像处理2022-02-16 3732
-
如何在Vitis HLS中使用C语言代码创建AXI4-Lite接口2020-09-13 7862
全部0条评论

快来发表一下你的评论吧 !
