

eBPF深入理解和实现原理
描述
作者简介
周鹤洋(GitHub: losfair):目前就读于南京航空航天大学,此前在字节跳动、Vercel 等公司实习,现正与 DatenLord 团队合作完成毕业设计项目 WaveBPF 硬件加速器。开源软硬件开发者、独立产品 Planet 作者,发起和参与过 Blueboat、Wasmer、Next.js 等开源项目,业余开发过超标量处理器 Violet、内核态 WebAssembly 运行时 kernel-wasm 等 OS 与硬件项目。
TLDR
简单来说,wBPF 是一个在硬件上直接执行 eBPF 程序的系统。
它支持两种使用模式:
-
网络设备加速:集成到智能网卡中,对进/出网口的数据流实现观测与变换;
-
多指令集模式:在通用系统(比如 RISC-V + Linux)中,支持切换 CPU 进入 eBPF 指令集模式,从 Linux 内核直接调用硬件能力执行 eBPF 字节码。
Why?
eBPF 是一种来源于软件实现的“字节码格式”,并非传统的硬件指令集,常规的实现方法是解释器、JIT 或 AOT 编译成硬件指令片段执行。eBPF 设计时即以可向主流指令集架构 1-1 翻译为目标,JIT 编译的性能损失比传统的二进制翻译技术要低很多,为什么还要尝试用硬件实现呢?
-
首先,在“内核调用 eBPF“这一场景下,eBPF 需要访问内核缓冲区;针对 eBPF 的内存访问特性,专用的硬件逻辑路径可以实现比通用 MMU 更高效的内存管理机制。高性能处理器页表切换的开销很高,尤其在硬件与内核针对 Meltdown / Spectre 等微架构旁信道信息泄漏问题实现 mitigation 后更是这样;而 eBPF 程序的内存数据依赖相对规整,可以用类似“分段”的方法实现虚拟内存。
-
其次,eBPF 是 MagiCore 多指令集支持的实验性目标,所以 ”because it’s possible” 也是做 wBPF 的理由之一.
MagiCore
MagiCore 是我的乱序处理器核心,设计成译码逻辑可插拔的架构,可支持 RV32/RV64、 eBPF、MIPS 等多种指令集。为什么要这样做?首先目前开源的乱序处理器核心似乎不多 (BOOM, 香山, NaxRiscv) ,为 FPGA 优化的实现更少;其次也是因为个人兴趣,可能很多学 CS 的同学和我一样会有“从 silicon 到产品做一个全链路属于自己的现代系统”这样的想法吧。
下图展示了 MagiCore 的流水线结构。各结构单元以是否处理数据为界以分为前端与后端两个部分;前端包含取指单元(负责取指、预测)与译码单元,负责为后端生成指令流;后端包含涉及数据调度与指令执行的所有结构单元,负责由指令流分析数据依赖关系,执行计算、存储计算结果与生成副作用。
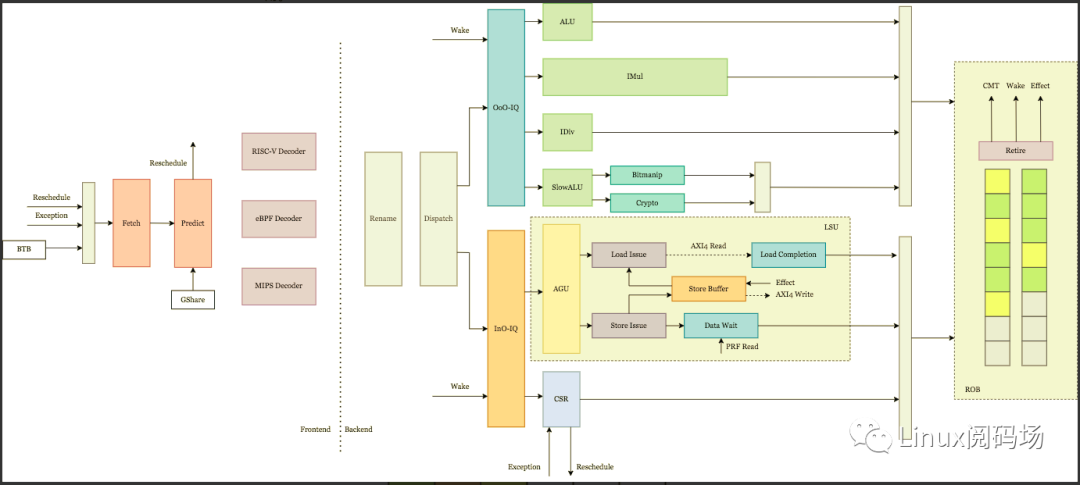
MagiCore 流水线结构图
以上是结构的视角;从指令处理流程的视角看,一条指令根据其数据依赖与生成的状态可以分为五个生命周期阶段:前端阶段、分发阶段、执行阶段、预提交阶段与提交阶段。各阶段对应的数据状态如下图所示:
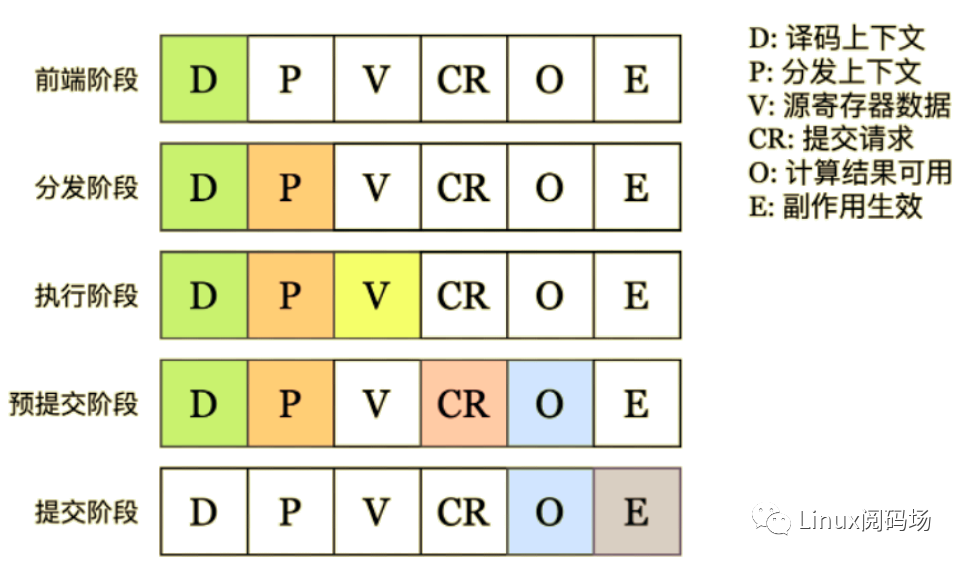
进入后端前的指令处理不涉及数据,均属于前端阶段,包括分支预测、取指与译码。本阶段输出取指上下文 FetchContext 与译码上下文 DecodeContext,提供指令地址、指令字、分支预测状态、缓存异常、译码异常、中断注入、架构寄存器与执行单元信息。
指令进入执行后端后的第一个阶段是分发阶段 (Dispatch),指令分发逻辑利用前阶段的译码信号与物理寄存器状态表为指令依赖的数据与产生的数据分配物理寄存器,同时分配重排序缓冲槽,生成重命名上下文 RenameContext 与分发上下文 DispatchContext.
指令的所有数据依赖就绪后即会被发射,进入执行阶段。发射逻辑从物理寄存器堆中取得源寄存器数据,为指令生成发射上下文 IssueContext.
指令执行完毕后进入预提交阶段,生成提交请求 CommitRequest 写入重排序缓冲,将指令计算结果写入目的寄存器,并生成唤醒信号。提交请求包含重排序缓冲编号 robIndex、全局迭代编号 epoch、指令输出值 regWriteValue 与指令异常 exception.
预提交阶段指令的提交请求到达重排序缓冲头部后进入提交阶段,输出物理寄存器状态被更新为已提交,寄存器提交映射表 (CMT) 中与输出架构寄存器对应的项被更新为输出物理寄存器编号,副作用被广播到副作用总线上,指令生命周期结束。
发射逻辑
MagiCore 采用了共享乱序发射队列 / 顺序发射队列的设计。
仅有数据依赖关系约束而没有全局顺序约束的指令由乱序发射队列发射,指令分发单元将指令推入发射队列,此时可确定该指令的数据依赖。每个时钟周期后,发射选择逻辑从发射窗口中选择所有数据依赖均已就绪的指令,发射到功能单元。
MagiCore 的乱序发射队列基于优先级决定指令发射顺序。每条被分发的指令会被分配一个 2-bit 的优先级,由 0 开始,每新推入一条指令,所有旧指令的优先级增加 1 直到饱和。
而访存、控制寄存器访问等指令具有副作用,须保证其副作用的产生顺序满足指令集架构对副作用顺序的约束,为以较低的硬件成本实现上述顺序保证,选择以顺序发射队列发射此类指令。
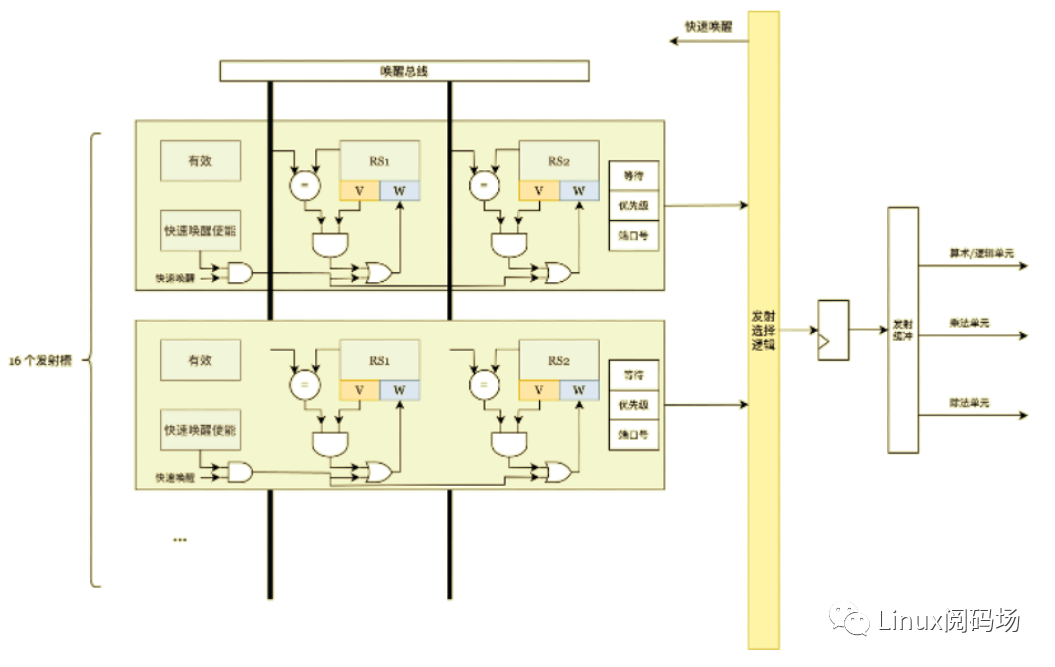
数据唤醒
数据唤醒是通知乱序发射队列“数据可用”的行为,所有源操作数均被唤醒是发射窗口中的指令被发射的必要条件。MagiCore 实现了常规唤醒与 ALU 快速唤醒两条数据唤醒路径,分别为不同类型的指令提供了较优的唤醒机制。
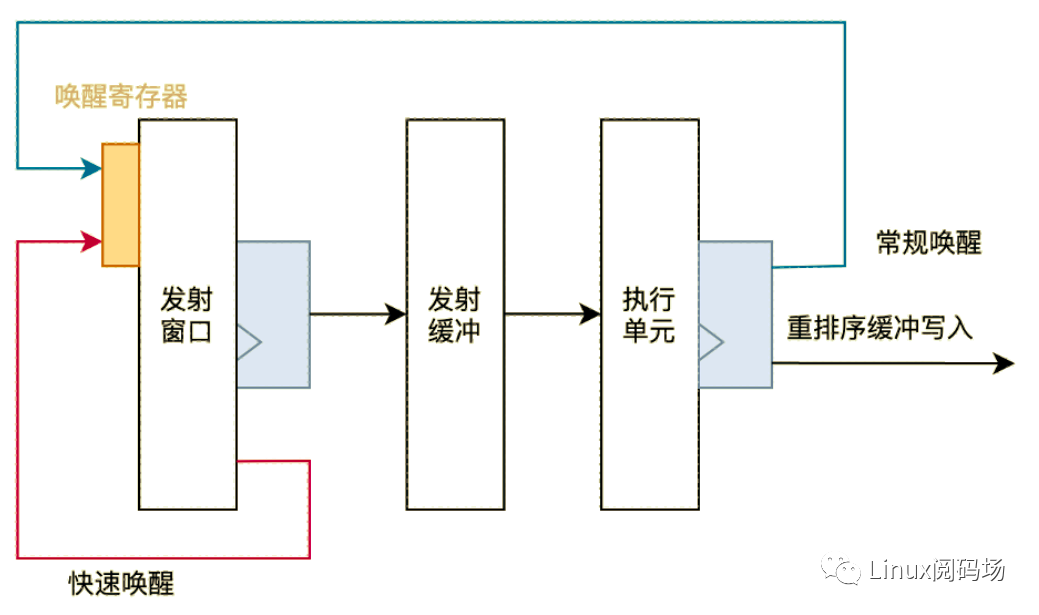
访存
TODO
二进制翻译
二进制翻译分为局部分析与全局分析两个阶段。局部分析是对包含多个对象文件的 eBPF 程序的各个对象文件分别独立进行分析的阶段,包含ELF文件解析、函数符号表分析、重定位分析,栈用量静态分析、调用/返回序列生成五个子阶段。全局分析是对 eBPF 程序进行整体分析并最终生成 RISC-V 指令序列、输出 Protobuf 目标镜像的阶段,包含数据段提取、伪调用解析、数据重定位链接、全局无用代码消除、入口跳板生成、RISC-V 代码生成、代码重定位链接、偏移量表生成八个子阶段。
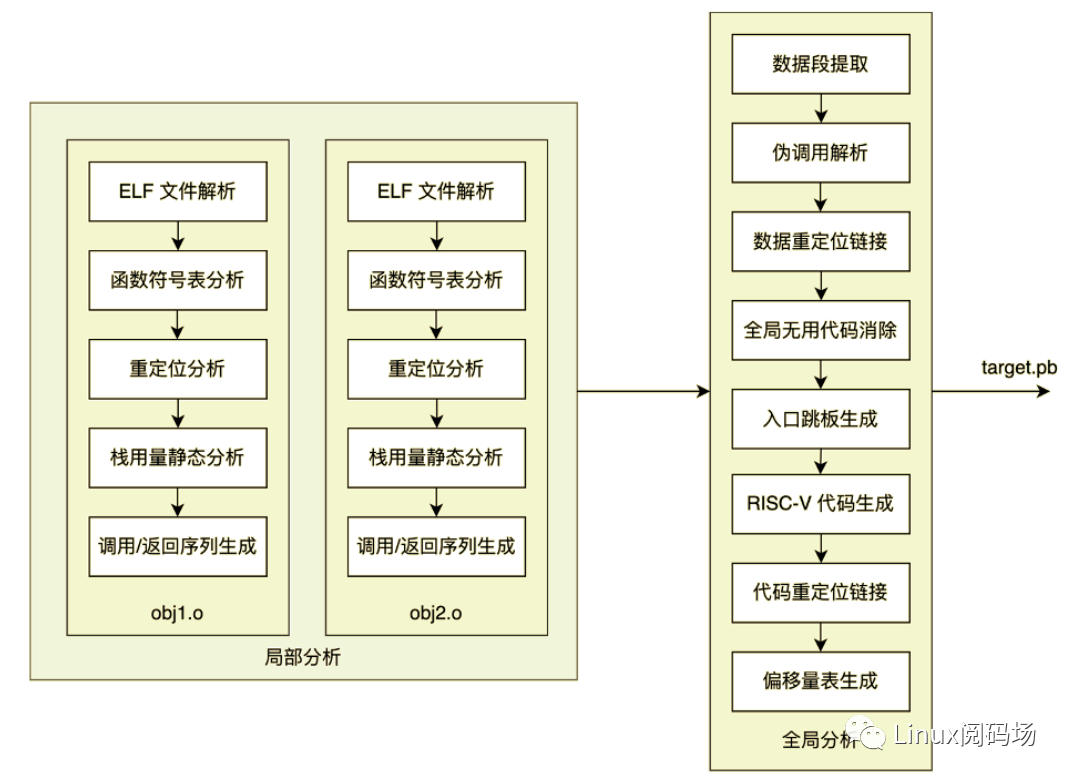
局部分析
-
ELF文件解析
二进制翻译软件的输入是文件类型为ELF64、目标机器类型为EM_BPF的ELF文件,本设计调用Rust语言第三方库goblin实现ELF文件的解析,并验证文件类型。
-
函数符号表分析
此阶段解析ELF符号表中函数类型的表项,建立函数名称到包含段编号、段内偏移的符号信息的映射,为后续分析作准备。对函数内eBPF指令的解析亦在此阶段完成。
-
重定位分析
此阶段解析ELF重定位表,建立从函数内指令位置到重定位信息的映射。
-
栈用量静态分析
此阶段逐函数对指令序列进行静态分析,计算栈用量。
eBPF标准规定每次函数调用可用的栈帧空间固定为512字节,但大多数函数实际使用的栈帧空间远小于512字节,调用函数时分配固定的栈帧空间会导致内存浪费。本设计针对栈指针用法的特例实现了优化,若某函数内部对栈指针的用法仅限于相对栈指针进行Load/Store操作的指令,则该函数的栈用量可被静态计算,无须分配完整的512字节栈帧;否则若任何其他类型的指令引用了栈指针作为源寄存器,则放弃当前函数的栈用量静态分析,采取保守策略分配512字节栈帧。
-
调用/返回序列生成
主流硬件指令集的ABI(应用程序二进制接口)均规定了调用方保存寄存器与被调用方保存寄存器,编译器须在函数入口与返回处生成相应的调用/返回序列,对被调用方保存的寄存器进行保存与恢复。eBPF规范虽然亦有对调用方/被调用方保存寄存器的规定,但eBPF程序中不含调用/返回序列,相应的寄存器保存与恢复逻辑由运行环境实现。
对于每个函数,此阶段遍历其全部指令,识别出被作为目的寄存器使用的所有被调用方保存寄存器,后向函数头部与返回 (EXIT) 指令前插入必要的栈空间分配、寄存器保存与恢复指令,将需保存的寄存器保存到栈上。下图为插入调用/返回序列后的函数栈帧结构示例。
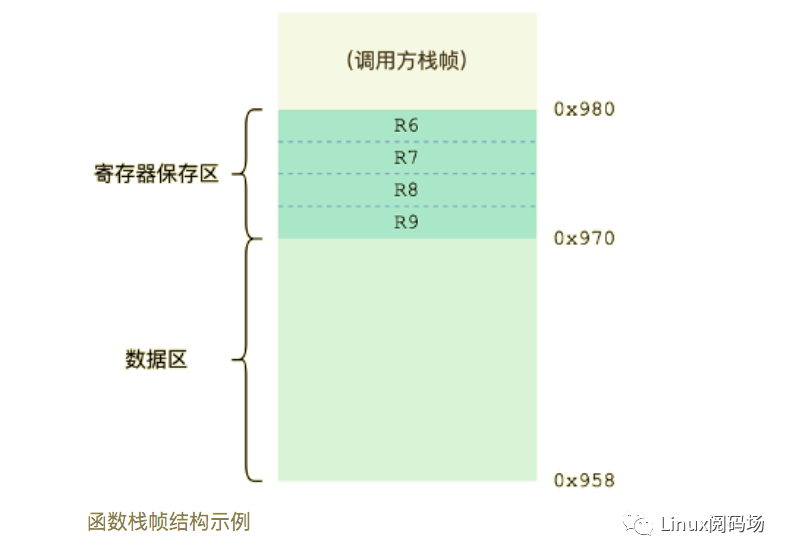
函数栈帧结构示例
全局分析
-
数据段提取
此阶段对所有对象文件遍历ELF段标头,将数据段序列化到输出缓冲区内,记录每个数据段的相对偏移量,为后续重定位逻辑作准备。
-
伪调用解析
eBPF的函数调用分为环境调用与伪调用 (Pseudo Call) 两类,环境调用是对主机环境提供的、非eBPF函数的调用,伪调用是对其他eBPF函数的调用。伪调用分为静态伪调用与动态伪调用两类,静态伪调用的调用目标函数在对象文件生成时即确定,动态伪调用在动态链接时进行重定位而确定。由于局部链接阶段可能向原始eBPF程序中插入新指令,静态伪调用的调用偏移量亦须更新,此阶段解析所有对象文件中的静态与动态伪调用,存储为应被重定位的指令的注解。
-
数据重定位链接
此阶段根据ELF重定位表与子阶段(一)提供的数据相对偏移量信息更新指令对数据引用的偏移量。
-
全局无用代码消除 (Global DCE)
此阶段以用户提供的入口点为根结点,遍历所有可达函数,移除未被使用的函数,降低输出镜像体积。
-
入口跳板生成
此阶段是写入指令镜像的第一个阶段,生成入口跳板代码,从内存中加载寄存器初始值并跳转到用户指定的目标地址。
-
RISC-V代码生成
此阶段由经过上述处理的、带注解的eBPF指令序列生成RISC-V指令序列,写入指令镜像。
-
代码重定位链接
此阶段根据步骤(二)伪调用解析所提供的指令注解,对步骤(六)生成的RISC-V指令序列中对指令地址的引用进行重定位。
-
偏移量表生成
至此指令镜像与数据镜像均生成完成,此阶段根据上述步骤提供的元数据计算各函数起始位置在指令镜像中的偏移量,生成偏移量表以供加载执行时指定入口函数。
Linux 设备驱动
目前 wBPF 测试用的平台是 Zynq-7020,由处理系统 (PS) 上运行的软件控制可编程逻辑 (PL) 上的自定义硬件。wBPF 硬件的设备树定义如下:
wbpf0@43c00000 {#address-cells = <1>;#size-cells = <1>;compatible = "bluelogic,wbpf1";clocks = <&clkc 15>;reg = <0x43c00000 0x10000 0x7aa00000 0x20000>;interrupt-parent = <&intc>;interrupts = <0 29 4>;};
内核模块加载后即注册为 Linux 平台设备驱动;探测到设备树节点后,创建 /dev 设备节点,通过 ioctl 接口向用户态提供执行 eBPF 的能力。
实现
wBPF 的硬件系统(包括 MagiCore)采用 SpinalHDL 硬件描述语言设计、采用 Cocotb 验证;软件系统采用 Rust + C 开发。
原文标题:wBPF WXMP post submission
文章出处:【微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
-
为什么要深入理解栈2022-02-15 1123
-
深入理解STM322021-08-12 1606
-
如何深入理解ES6之函数2020-05-22 1577
-
深入理解lte-a2019-02-26 4360
-
《深入理解Linux网络技术内幕》(EN)2018-02-06 5070
-
《深入理解Android》文前2017-03-19 725
-
《深入理解LINUX内存管理》学习笔记2016-11-07 3491
-
深入理解C语言比较有用的几个资料2014-08-07 4988
-
深入理解和实现RTOS_连载2014-05-29 6026
-
深入理解Android2012-08-20 3361
-
深入理解SD卡原理和其内部结构总结2012-08-18 3001
全部0条评论

快来发表一下你的评论吧 !
