

使用粗粒度可重构阵列加速处理
描述
随着性能需求的增加和对低功耗设计的推动,需要更有效的方法来执行处理任务,因为由于功率限制,将更多处理器投入性能问题不再可行。加速器旨在以更快的速度和更低的功耗进行计算,但今天的加速器在功耗和性能方面存在缺陷。
加速器阵容
亚利桑那州立大学计算、信息学和决策系统工程学院副教授 Aviral Shrivastava 正在对可编程加速器进行研究,以增强当今的加速技术。Shrivastava 列出了当今使用的三种常见类型的加速器:硬件加速器、FPGA 和 GPU。硬件加速器将特定的计算元素专用于处理计算,而不是在 CPU 上运行它们。它们速度快、功耗低,但不适合当今快速变化的技术迭代,因为它们不可编程。FPGA 是可编程的——开发人员可以在其上编写任何逻辑并且它们可以充当加速器——但 Shrivastava 说它们通常过于通用并且消耗太多功率。GPU 是当今流行的加速器,
粗粒度可重构阵列
Shrivastava 正在开发粗粒可重构阵列 (CGRA),它可以加速非并行循环,并在 GPU 的并行循环优势之上实现更多加速功能。CGRA 由一个由算术逻辑单元 (ALU) 和寄存器组成的二维网格组成,这些单元接收输入和指令,计算指令的算术或逻辑运算,并将输出发送给它的四个邻居以计算下一个步骤(图 1)。
图 1:粗粒度可重构阵列。
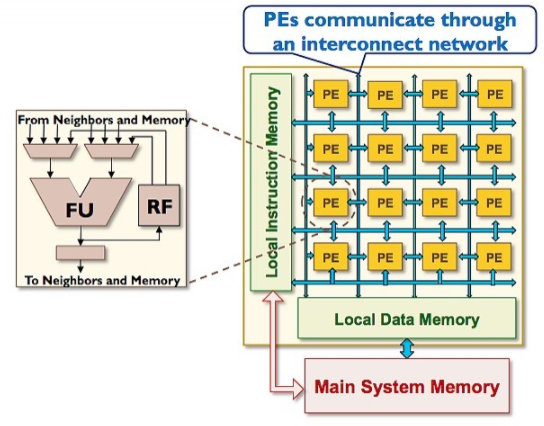
CGRA 的潜力来自于他们能够在消耗很少的电力的情况下执行操作。在常规处理器中执行加法运算需要很大的功率:它必须经过 20 多个流水线阶段。在 CGRA 中,只需要从邻居那里获取操作数并执行加法运算。CGRA 可以通过流水线加速——循环的操作被布置在 CGRA 的 PE 上,数据在它们之间流动。
CGRA 本身并不新鲜,但开发人员对现有的 CGRA 进行编程以仅执行一种类型的计算。Shrivastava 说,挑战在于映射,因为循环内核需要映射到 CGRA,操作映射到节点,数据依赖关系映射到 CGRA 的路径。Shrivastava 的目标是消除耗时的手动编码,并使任何类型的循环或计算能够通过编译器映射到 CGRA,这是一种相对较新的方法。他正在开发一个生成映射代码的编译器工具链。
Shrivastava 说 CGRA 的研究引起了 IBM 的兴趣,IBM 希望将这种方法应用于并行循环轻型服务器应用程序。用于科学研究和多媒体扩展的图形和高性能计算也可以从使用 CGRA 中获益。
解决分支分歧问题
所有现有加速技术面临的一个挑战是“分支分歧”。当执行具有“if-then-else”结构的循环时,加速器分配资源以执行来自分支的两条路径(真路径和假路径)的指令,然后丢弃假路径指令的影响。FPGA 将两个路径的功能映射到计算资源上,GPU 执行来自两个分支路径的指令并丢弃错误路径指令的结果。加速器必须这样做,因为在分配分支路径资源时,分支的结果在编译时是未知的(分支的结果是在运行时计算的,当执行分支时)。这种冗余执行会导致分支花费双倍的性能时间和执行能力。
Shrivastava 和他的团队提出了通过智能硬件-软件协同设计解决分支分歧问题的方法。不是为真路径分配一些PE,而为假路径分配一些PE,而是分配相同的PE来执行来自两条路径的指令。来自真路径和来自假路径的指令都发给PE。在运行时,PE 只选择正确的一个来执行。
审核编辑:郭婷
-
求一种可重构测控系统的设计构想2021-04-30 1506
-
粗粒度可重构阵列架构相关实践2021-03-11 1189
-
采用FPGA实现可重构计算应用2019-07-29 2937
-
一种基于体系结构模板的粗粒度可重构SoC设计方法2017-11-29 1261
-
基于PSO的粗颗粒度可重构处理器时域划分算法设计刘勰2017-03-17 920
-
多层异构粗粒度可重构处理器的编译器后端设计2017-01-07 693
-
面向大数据集的粗粒度并行聚类算法研究2016-01-15 722
-
用于视频处理的可重构流处理器的设计2011-08-18 1138
-
FPGA可重构设计的结构基础2011-05-27 4039
-
用于可重构硬件容错过程的辅助布线电路设计2010-04-24 1845
-
基于跨导运算放大器的可重构模拟电路及应用设计2009-11-13 479
-
二维DCT在粗粒度可重构处理器上的实现2009-04-14 882
全部0条评论

快来发表一下你的评论吧 !
