

将多核复杂性与不同的工具和架构混合在一起
描述
假设不考虑金钱、时间或商业限制,并且只有物理学是唯一的限制,您将如何设计最终的计算机处理器?它会大规模并行,以极高的频率运行,并使用奇异的光学或量子互连吗?它会运行熟悉的软件,如 x86 或 PowerPC,还是有新的优化指令集?它会很大还是很小?它是否需要智能编译器或独特的软件结构?
多年来,为了让处理器运行得更快,设计人员必须做的就是提高时钟速度。在功耗和相关的散热赶上速度增加之前,这一直很好。超越这一点,走得更快意味着除了走得更快之外还要做一些事情。
多核速度更快,但是……
从此开始了多核时代。如果两个头比一个好,那么四个肯定是两倍好。在某种程度上,这个公理是正确的。但是今天的双核和四核处理器的运行速度并不比上一代快两到四倍。
这有两个原因:硬件和软件。当今绝大多数多核芯片的扩展性都不是很好,因此四核并不能真正提供四倍于单核实现的性能。片上总线跟不上,缓存一致性开销会消耗性能,管道过于频繁地停止等等。由于各种原因,当核心数量翻倍时,传统的微处理器架构不会接近双倍的性能。
在软件方面,许多程序员不习惯或不熟悉多核编程。当所讨论的多核芯片包含不同类型的处理器内核(通常称为异构架构)时,尤其如此。对一个处理器进行编程已经够难了;使用单独的工具链对四个不同的工具进行编程要复杂得多。
异构的,同质的,还是只是庞大的?
可以提出一个论点,即不同的计算问题需要不同的资源,因此微处理器应该包括一系列不同的处理资源。例如,一些任务可能需要信号处理能力,另一些可能需要单指令多数据矢量处理,而还有一些可能涉及复杂的决策树和大量数据移动。
一种观点认为,没有一种处理器架构可以有效地处理所有这些不同的任务。因此,需要不同架构的马赛克。在极端情况下,可以设想一个处理器由截然不同的计算引擎组成,除了它们共享的包之外没有任何共同之处。这些处理器实际上是共存的,而不是合作的。
相反的方法是选择一个指令集并坚持下去。这无疑简化了编程,但存在部署过于通用的处理器的风险,这些处理器没有针对特定任务进行微调。另一方面,处理器是可编程的,改变软件比改变硬件更容易、更便宜。
易于编程也不是一个小问题。延迟通常是由软件错误引起的,而不是硬件问题。更复杂的是,程序员被多核处理器吓得要死。让一个高端处理器可靠地工作已经够难的了。你如何编程和调试其中的 10 个?使用一个内核架构进行编程、调试和设计比处理具有不同指令集、架构、总线、工具和调试方法的不同内核的混合体更容易。
对比方法
英特尔和 AMD 已将大部分建议牢记在心,并生产了其传统 x86 架构的双核和四核版本。在某种程度上,这只是将资产从负债中提取出来。x86 是他们知道如何做的,向后兼容性对他们的市场至关重要。现有的 x86 代码在这些升级后的设计上运行良好,尽管它很少运行得比以前快得多,也很少使用额外的内核。
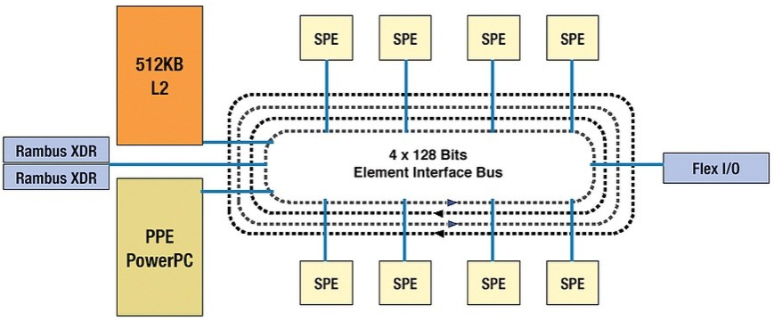
相比之下,许多 RISC CPU 和网络处理器 (NPU) 供应商采取了截然不同的方法,将各种不同的处理器内核和架构混合到各种瑞士军刀设计中。例如,IBM 著名的 Cell 处理器(图 1)有一个通用处理器内核和八个专用内核,需要不同的工具和编程技术。几条宽总线——一些环,一些更传统的——以各种方式连接核心。Cell 的性能令人印象深刻,但 PlayStation 程序员抱怨 Cell 是一头难以驯服的野兽,部分原因是管理带宽、延迟、总线事务和一致性都是游戏的一部分。
图 1: IBM 的 Cell Broadband Engine 芯片包括九个处理器,其中一个基于 PowerPC。处理器通过元素互连总线连接,共有 12 个主控器。它被实现为四个反向旋转的单向环。
将所有正确的硬件资源集中到单个芯片上是一回事。使组合可用是另一回事。具有混合架构的大规模并行芯片结合了两全其美:大规模多核复杂性与完全不同的工具和架构。这就像在您的芯片中举行联合国会议一样。
啮合在一起
更好的方法是保留大规模并行部分,这是高性能的必要条件,但抛弃差异并将许多相同的处理器内核连接到二维网格中。从概念上讲,它与通过网络连接单个计算机没有太大区别,只是在微观尺度上。
Meshing也有“grok-ability”的一面。程序员不难想到十个、100 或 1000 个相同的处理器内核以相同的方式工作并以一种简单但大部分透明的方式相互通信。1000 个元素中的每一个是否都针对给定的工作进行了完美调整几乎无关紧要。重要的是有 1,000 个处理器可以解决一个问题。
这种均匀的布置也有助于可扩展性。虽然类似 Cell 的组合非常适合它们的特定任务,但构建更大或更小的 Cell 版本需要芯片制造商进行大量的重新设计工作,接收端的程序员甚至需要更多的工作。现有的 Cell 代码不会神奇地放大或缩小到具有不同资源组合的芯片。它可能根本不会运行。相比之下,在相同处理器的网格中增加 25% 的处理器可增加 25% 的计算能力,而不会破坏现有代码。
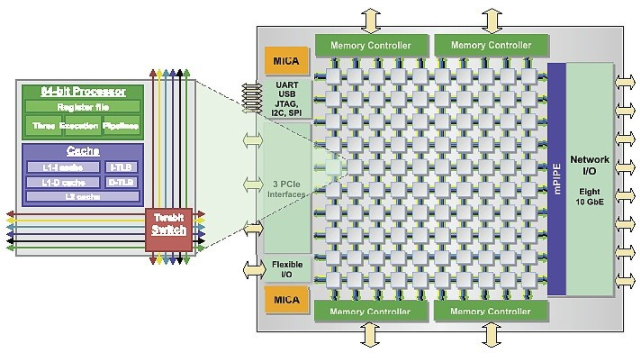
这并不意味着设计这种类型的芯片是微不足道的。核心之间的带宽是第一个挑战。如果核心不能有效地相互通信,那么连接它们就没有多大意义了。这种方法的一个例子是 Tilera 的 TILE-Gx100 处理器(图 2),包含 100 个相同的内核。在此处理器中,相邻内核之间的带宽为 1,100 Gbps。每个核心在北/南/东/西方向有四个连接,100 核处理器的总带宽为 200 TBps。大多数应用程序很难使用其中的一小部分。即使是 Tilera 相对适中的具有 4x4 内核阵列的 Gx16 芯片也拥有 20 TBps 的片上带宽。
图 2:其中一个 Tilera TILE-Gx 处理器内核(其中 n 为 16 到 100)有效地处理内核之间的带宽。每个核心块都有自己的 64 位处理器、L1 和 L2 缓存,以及与北/南/东/西方向的四个邻居的网络连接。
这种基于图块的设计的另一个挑战是内存延迟。如果内存不够接近或无法访问,所有这些处理器都可能会停止运行。同样,Tilera 将其设备分解为易于复制的切片,每个切片都有自己的本地 L1 和 L2 缓存。有趣的是,即使内存是每个图块的本地内存,它也可以是更大的共享分布式缓存的一部分,该缓存在所有共享者之间保持一致性。在某些情况下,程序员可能想要定义任意数量的缓存一致性岛,必要时与相邻的切片合作或忽略。
整个芯片架构就像一个计算结构。相同的逻辑块、内存块和互连块在行和列中复制,以制造更大或更小的芯片。就像 FPGA 或分形 Mandelbrot 图像一样,平铺处理器在任何规模上看起来都是一样的。大或小,它的编程方式相同。可扩展性平方。
与四核 x86 类似,但与 Cell 或 NVIDIA 芯片不同,TILE-Gx 网状互连在引擎盖下透明地工作。Mesh 流量不需要手动调整,事务也不需要手动调整以避免冲突或仲裁。尽管它位于中心,但网格基本上是不可见的,这正是程序员喜欢它的方式。
可扩展性最终获胜
与大多数生态系统一样,许多不同类型的处理器将继续存在。有些人会茁壮成长,而另一些人将勉强在某个特定的利基市场谋生。外部力量将淘汰牛群,就像图形和网络处理器一样,筛选出那些不适合当前环境的人。
在过去的几十年里,可扩展性和可编程性一直是关键。开发人员需要一种他们可以理解并能持续使用的芯片。他们想要一个增长路线图,包括价格/性能规模的上下。让它变得非常非常快也没有什么坏处。
审核编辑:郭婷
-
将5G信号链与电平转换结合在一起2024-09-18 525
-
如何将DMA和环形的FIFO队列结合在一起来使用呢2021-12-09 3468
-
如何将高图形性能和低功耗更好地结合在一起?2021-06-01 1291
-
示波器的三大功能是哪些? 它们是怎样组合在一起的?2021-05-08 4969
-
USAT和USB BooLoad能结合在一起吗2020-04-24 1895
-
labview中模糊控制和pid是怎么结合在一起的2020-03-13 2433
-
基于一款将PC和PS4或Xbox结合在一起的强大主机介绍2020-01-08 4032
-
怎么使用PADS将TOP层结构、BOT层结构、还有板框重合在一起?2019-06-25 7236
-
请问ISE和Mircoblaze是如何结合在一起的?2019-02-19 1289
-
怎样讲maxwell与 Simplorer联合在一起用?2017-11-16 3386
-
AD 如何把同一属性的焊盘组合在一起2016-11-16 16256
-
几个单独的程序组合在一起2016-03-23 4059
-
将分布测量参数整合在一起测量2014-09-10 3164
-
不同容量的电池组合在一起使用会出现什么问题?2009-11-13 4064
全部0条评论

快来发表一下你的评论吧 !
