

 在标准C语言中编译出来的可执行程序
在标准C语言中编译出来的可执行程序
描述
在标准C语言中,编译出来的可执行程序分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分。如下代码
#include
int a = 0; //a在全局已初始化数据区
char *p1; //p1在BSS区(未初始化全局变量)
void main()
{
int b; //b在栈区
int c; //C为全局(静态)数据,存在于已初始化数据区
char s[] = "abc"; //s为数组变量,存储在栈区,
char *p2,*p3; //p2、p3在栈区
p2 = (char *)malloc(10);//分配得来的10个字节的区域在堆区
p3 = (char *)malloc(20);//分配得来的20个字节的区域在堆区
free(p2);
free(p3);
}
使用linux编译之后得到的可执行文件如下
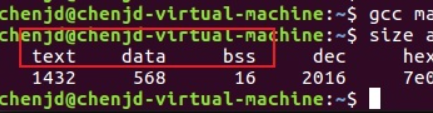
可以看到代码区(text)、数据区(data)和未初始化数据区(bss)。
代码段(text):存放代码的地方。只能访问,不能修改,代码段就是程序中的可执行部分,直观理解代码段就是函数堆叠组成的。
数据段(data):全局变量和静态局部变量存放的地方。也被称为数据区、静态数据区、静态区:数据段就是程序中的数据,直观理解就是C语言程序中的全局变量。注意是全局变量或静态局部变量,局部变量不算。
未初始化数据区(bss):bss段的特点就是被初始化为0,bss段本质上也是属于数据段。
那么问题来了,为什么要区分data段和bss段呢?
以下面代码为例,a.c和b.c的差异只是有没有给arr数组赋值。
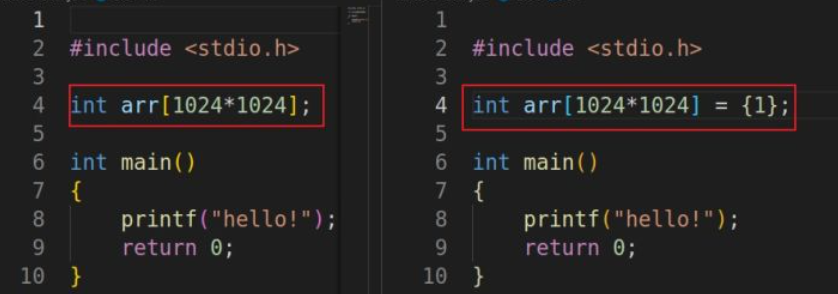
可以看到a.out的bss段大,b.out的data段大。但是b.out的文件大小明显比a.out的大很多。data段会增大可执行文件的大小,而bss段不会。
data段是全局变量,但是需要初始化值,上面我的例子是全部初始全部为1,但也可能是1024*1024个不同的数据,而这些数据需要保存起来,表现出来也就是需要保存在可执行文件中。
bss段也是全局变量,但不需要初始化值,只需要保存一下这个全部变量的保存的数据类型和大小即可。即使它的数组容量是1024*1024,也不会占用很多可执行文件的大小。
如果一个全部变量初始化为0,那么它也是bss段,不是data段,即使你代码中把它初始化为0了。
关于数据段,也就是data段,也会分为RO data(只读数据段)和RW data(读写数据段)。
- 只读数据段:程序使用的一些不会被更改的数据,使用这些数据的方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
- 读写数据段:程序中是可以被更改的数据,且初始化过的,所以需要放置在RAM中,且初始化的内容放在存储器中(表现为放入可执行文件中)。
上面说到“编译出来的可执行程序分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分”,那运行中就会多出来一些区域,这就是我们常说的堆栈,注意堆栈是两个区域堆和栈。
栈:局部变量、函数一般在栈空间中。运行时自动分配&自动回收:栈是自动管理的,程序员不需要手工干预。方便简单。是提前分配好的连续的地址空间。栈的增长方向是向下的,即向着内存地址减小的方向。
堆:堆内存管理者总量很大的操作系统内存块,各进程可以按需申请使用,使用完释放。程序手动申请&释放:手工意思是需要写代码去申请malloc和释放free。可以是不连续的地址空间。堆的增长方向是向上的,即向着内存地址增加的方向。
下面是简单的演示代码
#include
#include
int bss_var; //未初始化全局数据存储在BSS区
int data_var=42; //初始化全局数据存储在数据区
int main(int argc,char *argv[])
{
char *p ,*b;
printf("Adr bss_var:0x%x\n",&bss_var);
printf("Adr data_var:0x%x\n",&data_var);
printf("the %s is at adr:0x%x\n","main",&main);
p=(char *)alloca(32); //从栈中分配空间
if(p!=NULL)
{
printf("the p start is at adr:0x%x\n",p);
printf("the p end is at adr:0x%x\n",p+31);
}
b=(char *)malloc(32*sizeof(char)); //从堆中分配空间
if(b!=NULL)
{
printf("the b start is at adr:0x%x\n",b);
printf("the b end is at adr:0x%x\n",b+31);
}
free(b); //释放申请的空间,以避免内存泄漏
while(1);
}
审核编辑:汤梓红
-
C语言的编译过程2023-06-25 1126
-
C语言的编译链接过程2023-08-21 3820
-
c语言比汇编编译出来的程序大多少?2013-05-14 2742
-
labview生成的可执行程序的反编译2013-07-17 34292
-
从完成C源文件编辑后到执行程序前需要哪些步骤2022-02-28 530
-
C语言的编译预处理2009-09-20 780
-
16KEY-B的可执行程序2011-11-22 683
-
Setup软件安装可执行程序工具免费下载2018-11-13 2011
-
了解Linux安装ARM交叉编译器的步骤2019-04-26 7085
-
C语言的源代码文件和目标文件与可执行文件的详细介绍2020-02-18 10022
-
嵌入式软件开发笔试面试知识点总结-C语言部分2021-11-03 499
-
KEIL5中C语言编程时可以在可执行语句之后定义变量2022-01-13 1167
-
如何编译嵌入式系统运行的程序?2023-02-13 2203
-
c语言源程序main函数的位置2023-11-24 4484
-
ida反编译出来代码能直接用吗2024-09-02 2500
全部0条评论

快来发表一下你的评论吧 !
