

开源SPL的出现,将使报表数据准备的困难得到巨大的改观
描述
现在应用中的报表大都使用报表工具开发,成熟的报表工具提供了丰富的显示设置、图表类型、导出打印等功能可以简化报表开发,非常方便。但是,实际报表开发中还是经常碰到一些非常棘手的深层次问题,即使是已经熟练使用报表工具的开发老手也会很挠头。为什么有了报表工具还会出现这些问题呢?报表开发,看起来就是将数据按照指定格式的表格或图形呈现出来,这也是报表工具一直很擅长的环节。但是,原始数据经常并不适合直接呈现,需要先做一些复杂的处理,这就是数据准备环节。从报表工具的眼光上看,数据准备属于报表之外的事情,可以堂而皇之地拒绝处理。但是,拒绝不等于不存在,这个工作总还要做。没有好的工具,目前报表的数据准备还处于比较原始的硬编码阶段,几百上千行的 SQL、几十上百 K 的存储过程和大量的 JAVA 代码充斥在报表之后。落后的工具必然导致低下的生产效率,会严重拖累整个报表开发的进程,也就出现了前述的“挠头”现象。再由于大多数报表工具的不重视,这个问题迟迟还没有被解决的迹象。报表数据准备之于报表有如树根之于大树,如果根本得不到解决,在枝叶上花多少精力都是白费。开源 SPL 的出现,将使报表数据准备的困难得到巨大的改观。SPL(Structured Process Language)是专业的开源结构化数据计算引擎,提供了丰富的计算类库,支持过程计算,擅长完成各类复杂计算。同时开放计算体系支持多数据源混合计算,支持热切换,提供标准 JDBC 接口可与报表工具无缝集成。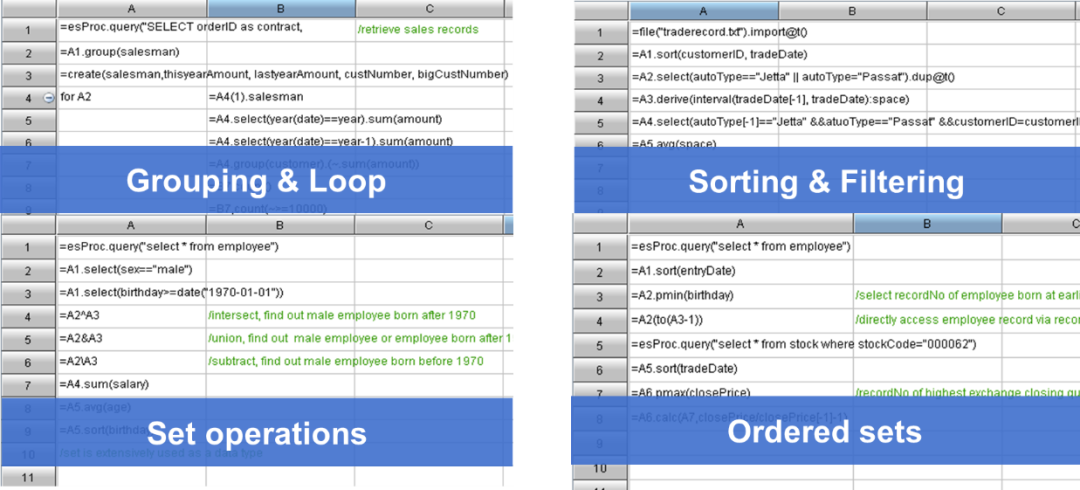 与 SQL 不同,SPL 提倡分步计算,算法可以按照自然思维一步步实现,这样就可以避免编写过于复杂的 SQL(复杂 SQL 不仅难写,维护也不方便)。
与 SQL 不同,SPL 提倡分步计算,算法可以按照自然思维一步步实现,这样就可以避免编写过于复杂的 SQL(复杂 SQL 不仅难写,维护也不方便)。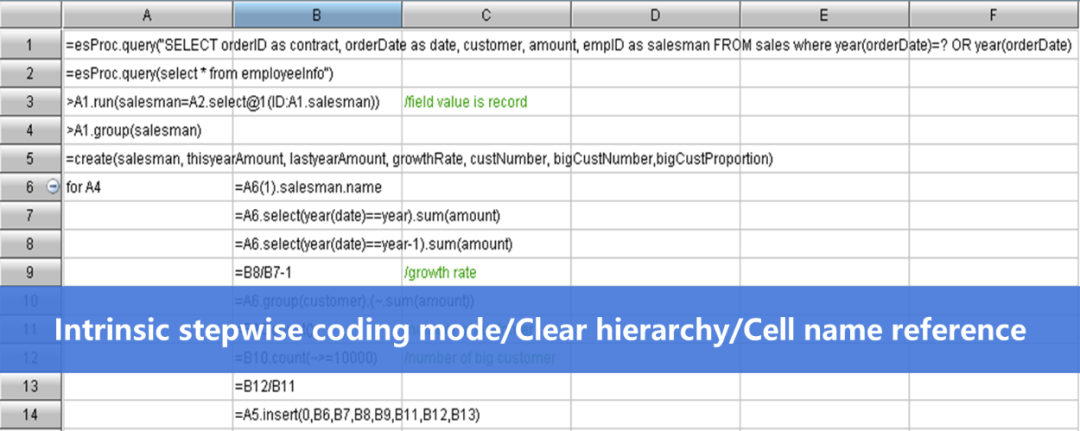 这里拿 SPL 和 SQL 做个对比(Java 计算要复杂得多,不太具备可比性)。查询目标:根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)SQL 实现要嵌套 3 层子查询才能完成:
这里拿 SPL 和 SQL 做个对比(Java 计算要复杂得多,不太具备可比性)。查询目标:根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)SQL 实现要嵌套 3 层子查询才能完成:
 每步计算的结果都可以实时查看,相比 SQL 和存储过程不好调试要方便高效得多。SPL 可以与报表工具集成嵌入使用,SPL 提供了标准 JDBC 接口供报表工具调用,这样就可以无缝取代原来实现报表数据准备的硬编码方式,甚至可以与原有方式共存。
每步计算的结果都可以实时查看,相比 SQL 和存储过程不好调试要方便高效得多。SPL 可以与报表工具集成嵌入使用,SPL 提供了标准 JDBC 接口供报表工具调用,这样就可以无缝取代原来实现报表数据准备的硬编码方式,甚至可以与原有方式共存。
这个运算复杂度是平方级的,数据量小的时候没什么影响,数据量稍大时性能就会急剧下降。解决办法是将在报表端实现的多数据集关联运算转移到数据准备阶段完成。如果是同一个数据库可以使用 SQL,但如果 SQL 运行效率不高,或者数据来自多源时,可以使用 SPL 完成关联计算。仍然是借助 SPL 的多源能力、高性能算法以及高性能存储来达到提速的目的。
降低报表的开发工作量
报表开发主要分两个阶段:第一阶段是为报表准备数据,也就是把原始数据通过 SQL/ 存储过程 /Java 加工成报表可用的数据集;第二阶段是使用已准备的数据编写表达式进行报表呈现。数据呈现使用报表工具可以简单地完成,尤其近些年前端可视化技术的进步,越来越多报表都以图形的方式呈现,这更降低了报表呈现阶段的难度。然而,数据准备并没有工具化。粗略统计,在报表工具支持下,数据呈现在当前报表开发的工作量占比能降到 20%,剩下80% 都是数据准备,甚至更高。这时候,如果要优化报表开发、提升报表开发效率也要从报表数据准备方面入手。当前数据准备的主要方式是 SQL(包括存储过程)和 Java。后者要比前者麻烦得多,主要是因为 Java 缺少结构化计算类库,并非专门的集合计算语言。但 SQL 缺乏分步机制实现复杂计算时也非常繁琐,加上只能基于数据库,当碰到其他类型的数据源时就只能依靠 Java 了。另外,目前的一些前后端分离、微服务架构要求只能在应用端用 Java 硬编码。这些因素都增加了报表数据准备的工作量,导致报表开发效率不高。使用开源 SPL 可以辅助 / 替代原有的报表数据准备方式,借助 SPL 简洁的语法和丰富的类库可以快速完成报表数据准备任务,从而减少报表开发的工作量。丰富的计算类库:与 SQL 不同,SPL 提倡分步计算,算法可以按照自然思维一步步实现,这样就可以避免编写过于复杂的 SQL(复杂 SQL 不仅难写,维护也不方便)。这里拿 SPL 和 SQL 做个对比(Java 计算要复杂得多,不太具备可比性)。查询目标:根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)SQL 实现要嵌套 3 层子查询才能完成:select code,max(risenum)-1 maxRiseDays from( select code,count(1) risenum from(select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from(selectcode,ddate,case when price>=lag(price) over(partition by code order by ddate)then 0 else 1 end changeSignfrom stock_record))group by code,unRiseDays)group by codehaving max(risenum) > 5
而同样的计算用 SPL 则要简单很多:
| A | ||
| 1 | =connect@l("orcl").query@x("select * from stock_record order by ddate") | |
| 2 | =A1.group(code) | |
| 3 |
=A2.new(code,~.group@i(price |
计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
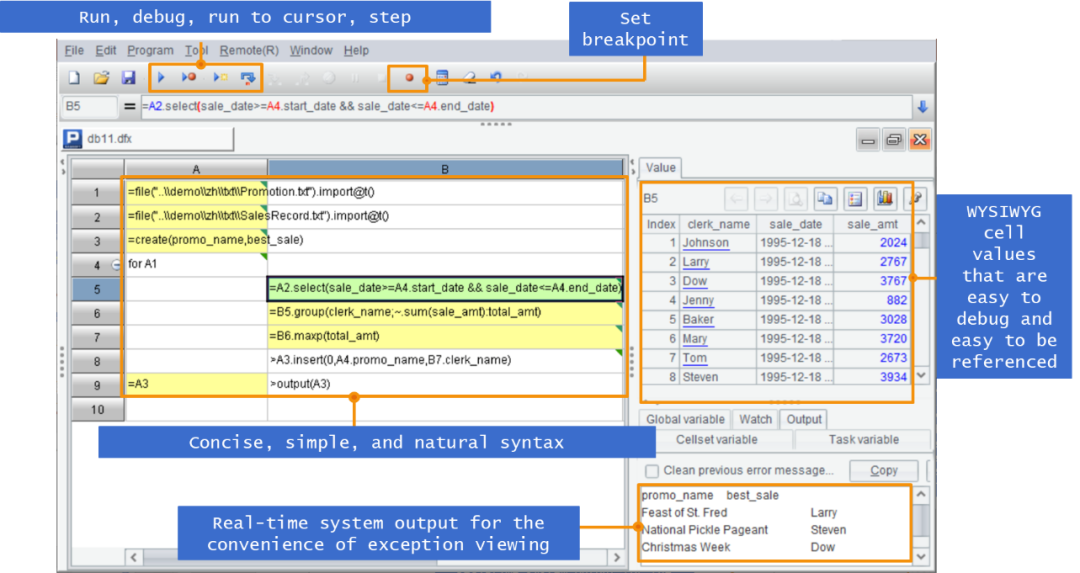
SPL 还提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…
每步计算的结果都可以实时查看,相比 SQL 和存储过程不好调试要方便高效得多。SPL 可以与报表工具集成嵌入使用,SPL 提供了标准 JDBC 接口供报表工具调用,这样就可以无缝取代原来实现报表数据准备的硬编码方式,甚至可以与原有方式共存。改善存储过程和 JAVA 做数据准备的缺点
在报表开发中为了应对复杂的数据准备逻辑而使用存储过程和 Java 处理数据的情况并不少见,在获得非常有限的开发便利时,却带来了巨大的麻烦。存储过程编辑调试困难,没有移植性更难以扩展,会造成报表与数据库的高度耦合,创建修改存储过程需要较高的数据库权限会带来安全隐患,存储过程往往需要专门的 DBA 维持,也推高了报表开发成本。不仅如此,同一个存储过程还可能被不同模块甚至不同应用共用,这就造成了应用间的紧耦合,牵存储过程一发而动应用全身。SPL 提供了不依赖数据库的计算能力,从存储过程的角度看 SPL 类似一种“库外存储过程”。这样可以充分解耦报表和数据库、应用与应用,不再存在安全问题,移植性也大大增强,再借助 SPL 开放的多样数据源支持,数据库扩展或更改时只需要修改数据源连接,无需更改计算逻辑,可以很好实现平滑移植。Java 由于缺少结构化计算类库,实现报表数据准备代码编写难度大,同样存在依赖专业程序员推高报表开发成本的问题。Java 实现数据准备还会造成报表模块和应用其他模块的紧耦合,不利于将查询压力大的报表模块单独维护。作为编译型语言,Java 缺乏有效的热切换机制,对频繁多变的报表业务十分不利。SPL 的语法更为简洁,实现同样的计算代码更短,报表开发人员就可以学习使用,人力成本更低。SPL 可以与报表模块集成,独立于应用其他模块,单独运行维护,降低应用间的耦合性。同时,SPL 解释执行支持热切换,可以更好适应多变的报表业务。减少数据库中的中间表
为了简化 SQL 运算难度或提高查询性能,或应对多源情况,经常会进行数据预处理,事先加工出一部分中间结果存在数据库中形成数据库中间表。报表开发时数据准备基于这些中间表完成,通常可以一定程度简化开发难度并获得较高的查询性能。但中间表是一把双刃剑,提供便利的同时缺点也很多。大多数情况下的中间表一旦建立几乎就无法删除(因为数据库表的管理机制是线性的,很难分类以确定中间表的归属,不敢轻易删除),这就会导致中间表越来越多,有时竟然高达数万。中间表要占用数据库空间,导致数据库容量不够;而加工中间表则需要数据库计算资源,导致数据库性能下降,中间表过多会导致数据库面临扩容压力。SPL 提供了不依赖数据库的计算能力,可以将中间表存储到库外文件中(开放数据文件格式或 SPL 存储格式),SPL 基于文件进行数据处理为报表输出计算结果,完成数据准备。将大量中间表外置到文件系统可以大幅减轻数据库的压力,既不用占用数据库的宝贵空间,更不需要牺牲数据库计算资源来加工中间表可谓一举两得。不仅如此,“库外中间表”可以使用文件系统的树状结构进行管理,不同目录的中间数据对应不同业务的报表,不仅方便管理,还能进一步降低报表模块间的耦合性。实现报表的热切换
热切换(Hot Swap)是指在系统不停机的情况下更换系统部件,在报表业务中则是指在不重启报表及相关应用的情况下完成对报表的维护(新增、修改、删除),实时修改,实时生效。目前大部分报表工具开发的呈现模板都能热切换,不过作为报表一部分的数据准备情况却有所不同。使用数据库 SQL 完成数据准备可以直接做到热切换,但编译型的 Java 不行。而现在随着更先进架构(如微服务)的应用,使用 Java 完成报表数据准备的情况非常常见。为了解决报表热切换的问题,可以使用 SPL 替代 Java 完成诸如微服务架构中的报表数据准备工作。SPL 解释执行,天然支持热切换,同时具备完善的计算体系以及敏捷语法可以很方便地实现数据处理任务。解决多样性数据源
当前报表的数据来源十分丰富,RDB、NoSQL、CSV、Excel、HDFS、Restful/Webservice、Kafka…都可以成为报表数据源,多样性数据源会带来两个问题,如何连接这些数据源?连接后如何关联计算?而在前后端分离、微服务等架构下,几乎所有报表都不会直接基于数据库开发,多样数据源问题就更加严重。以往解决报表多样源问题的方式有三种:一是借助报表工具的能力。有些报表工具提供了多种数据源连接支持,分别取数后在报表呈现模板中完成关联等计算。不过,报表工具的计算能力很弱,只能实现很有限的多源混合计算。二是将多源数据 ETL 到一个 RDB 中,将多源转化成单源再借助 SQL 能力完成计算。这种方式不仅很繁琐,数据也不实时,数据量大或计算复杂时还会引发数据库性能问题。而且这也严重有悖于微服务架构的原则。三是使用 Java 硬编码。Java 的问题我们已经说过多次,不仅编码难度高,而且也不支持热切换。开源 SPL 目前提供了几十种数据源支持,可以快速连接这些数据源完成取数计算。不仅是连接取数,SPL 提供丰富的计算类库可以很方便进行异构源混合计算,实现多源关联等复杂计算。 SPL 实时基于多源完成计算,将计算后结果直接输出报表进行呈现,不仅解决了数据实时性问题,也改善了报表工具计算能力不足、Java 编码难热切换难的困境,是报表多样源问题的有效解决方式。提升报表性能
报表性能是总也避不开的话题,报表作为 OLAP 中的最主要应用场景,涉及的数据可能很多,大数据量、计算逻辑复杂经常会引发报表性能问题。而报表是面向业务用户呈现的,性能差就会带来很恶劣的用户体验。报表性能问题表象上是报表查询慢,但其实绝大多数都是数据准备引起的,一旦数据准备好,呈现效率往往很高。报表数据准备是将原始数据加工成报表需要的数据集,报表要呈现的通常是聚合后的汇总结果数据量并不大,但原始数据却可能非常大,不仅数据量大,数据处理逻辑也可能很复杂,这些都会造成低性能。解决办法除了常见的优化 SQL 以外,还可以使用 SPL 提速。SQL 执行效率依赖数据库的优化能力,而对复杂 SQL 数据库优化引擎经常失效,导致执行效率不高。这时可以将计算逻辑使用 SPL 实现,借助 SPL 的高性能算法达到提速的目的。如果因为数据库过于繁忙(压力过大)导致查询慢,优化 SQL 也无能为力;甚至根本无 SQL 可用(非 RDB 源)时,使用不依赖数据库能力的 SPL 就比较有效了。特别说明的是,对于计算密集型任务,使用 SPL 优化时经常需要将数据事先外置到文件系统再进行,目的是减少 RDB 到 SPL 的 IO 时间,如果从数据库实时取数计算,IO 时间可能比计算时间还要长。另外,SPL 存储在数据组织方式上有很大优势,基于 SPL 存储计算可以获得更高性能。除了数据准备外,数据传输也是另一个瓶颈。报表通过 JDBC 接口访问数据库读取所需数据时,如果数据量比较大或者数据库 JDBC 性能较差(各种数据库的 JDBC 效率是不同的)会导致数据传输时间过长,导致报表变慢。对于数据密集型的报表,可以通过 SPL并行取数来提速。在 SPL 中建立多个数据库连接(这时要求数据库相对空闲),采用多线程的方式同时读取报表所需数据,可以是同一个表,也可以是多个表关联计算后的结果,这样数据传输的时间理论上就会缩短到原来的 1/n(n 是线程数),从而提升报表性能。此外,报表本身也可能发生计算较慢的问题。比如报表工具完成多数据集的关联是在报表单元格的表达式中完成的,类似这样 ds2.select(ID==ds1.ID),报表引擎在解析这个表达式时会按照顺序遍历的方式完成关联,即从 ds2(数据集 2) 中拿出一条记录,到 ds1 (数据集 1)中遍历,查找 ID 相同的记录;然后再拿第二条再去遍历查找;…这个运算复杂度是平方级的,数据量小的时候没什么影响,数据量稍大时性能就会急剧下降。解决办法是将在报表端实现的多数据集关联运算转移到数据准备阶段完成。如果是同一个数据库可以使用 SQL,但如果 SQL 运行效率不高,或者数据来自多源时,可以使用 SPL 完成关联计算。仍然是借助 SPL 的多源能力、高性能算法以及高性能存储来达到提速的目的。
低成本应对没完没了
报表不同于企业信息系统的其他部分,会伴随系统生命周期一直不断新增、修改。这是由于企业在生产经营过程中会不断催生出新的报表需求,这就造成了没完没了的报表。没完没了的报表无法消除,只能适应,这就需要低成本的适应方案。总体来讲,想要高效率、低成本地应对报表没完没了可以按照这样几步来走:第一步,引入报表工具解决报表呈现阶段的人力。先把最容易解决的问题解决掉,通过引入专业的报表工具解放报表数据呈现阶段的人力,完成各类图表呈现。目前大部分用户都会使用报表工具开发报表,因此这一步已基本实现。第二步,引入计算工具解决报表数据准备阶段的人力。跟第一步类似,要将报表数据准备也工具化才能彻底解决以往报表数据准备效率低下的问题。前文我们讨论的都是这个阶段的问题,利用开源 SPL 编码简洁、多源支持、热切换等特性可以很好实现数据准备工具化。配合第一步,可以让整个报表开发工作全面工具化,从而获得更高的开发效率。第三步,独立报表模块优化应用结构。报表开发全面工具化后,就可以调整应用结构,把报表模块从业务系统中解耦出来。报表模块仅仅共享业务系统的数据源(数据库或别的数据存储介质),而不再和业务系统紧密耦合。报表呈现和数据准备都工具化之后,报表运算可以被中间件解释执行,这样,报表的频繁修改增加也不需要让业务系统都重新启动,大幅降低运维的复杂度。这个过程特别重要的是梳理数据源,把报表模块需要的数据源单独整理出来,以后开发报表只需要和这些数据源打交道。通过这样三步将报表开发全面工具化,提升了报表开发效率,同时还优化了应用结构,独立后的报表模块单独运维,无论从技术架构上还是人员架构上都更为合理,有效应对没完没了的报表。审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
关于报表中输入表格中数据的问题?2012-10-08 2693
-
求助,利用labview中的生成报表存储数据出现不稳定的情况2018-01-31 3265
-
数据分析已经简单到只需准备好数据2020-07-08 3218
-
经验分享|BI数据可视化报表布局——容器2023-03-15 4487
-
WinCC数据报表实现方法介绍2010-07-03 1587
-
安讯百灵报表与开源Eclipse BIRT2011-04-13 1273
-
基于AM335x的U-Boot/SPL 的CCS 调试2014-08-21 11737
-
基于JasperReport通用的报表模板设计2017-12-04 1368
-
医疗保健行业采用大数据将使其发展方式产生巨大变化2019-08-26 3556
-
使用开源CMS系统所搭建的网站安全吗2019-08-29 1904
-
SPL的实际应用效果如何呢?2022-08-01 2869
-
深度解析SPL阶段A/B分区启动:spl_ab.c代码全拆解2026-01-20 10512
全部0条评论

快来发表一下你的评论吧 !
