

t770芯片怎么样 AI Benchmark跑分看展锐5G芯片T770性能特性
描述
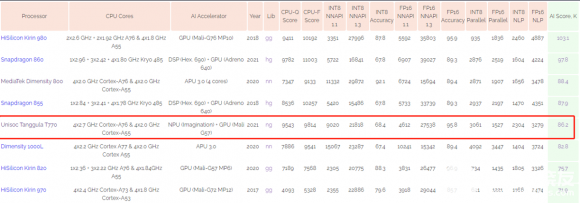
近日,AI Benchmark发布了最新Mobile SoCs推理测试结果。在这份备受AI圈关注的“战报”中,紫光展锐5G芯片T770取得了86.2K的不俗成绩。
AI Benchmark是全球权威AI性能评测平台,由苏黎世联邦理工学院计算机视觉实验室出品。这个实验室由计算机视觉领域著名学者Luc Van Gool, 医疗影像教授Ender Konukoglu,以及计算机视觉及系统教授Fisher Yu的研究组组成,是整个欧洲乃至世界最顶尖的CV/ML研究机构之一。
AI Benchmark涵盖了26组测试,共计78个测试子项,包括了目标识别、目标分类、人脸识别、光学字符识别、图像超分,图像增强、语义分割、语义增强等AI场景,从CPU、AI加速器对INT8和FP16模型的推理速度、准确性、初始化时间等数据全方位衡量平台/设备的AI能力。因此,AI Benchmark可以从比较客观的角度评估芯片的AI 性能。
在12个维度的测试里,共计102个测试数据,T770有超过59.8%的数据超过竞品。

具体表现在图片分类、并发场景 (量化模型)、目标检测、文字识别、语义分割、图像超分、图像分割、深度估计、图像增强、视频超分、自动文本生成等场景 。
接下来,让我们从几个关键的测试维度看下T770 AI性能的具体表现:
|
逐项拆解之MobileNet 首先来看较为经典的MobileNet神经网络维度。这里稍微提一下MobileNet的由来:谷歌在2017年提出了专注于移动端或者嵌入式设备中的轻量级CNN网络,其最大的创新点是提出了深度可分离卷积。mobileNet-V2是对mobileNet-V1的改进,是一种轻量级的神经网络。mobileNet-V2保留了V1版本的深度可分离卷积,增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual),而MobileNet-V3是谷歌基于MobileNet-V2之后的又一项力作,在精度和时间上均有提高。MobileNet-V3做了哪些修改呢?它引入了SE结构、修改了尾部结构和channel的数量,做了非线性变换的改变。MobileNet-V3提供了两个版本,一个是mobileNet-V3 Large,也就是AI Benchmark这次测试用的版本,另一个是MobileNet-V3 Small版本,分别对应了对计算和存储要求高与低的版本。 AI-Benchmark主要选取了V2和V3 Large两个版本进行测试。下图这个数据柱状图表达的是什么意思呢?这里包含了CPU、AI加速器分别对于量化和浮点模型的处理表现,主要从推理速度和准确性两个维度去评估平台/设备的AI能力,时间单位是毫秒。 灰色的柱形图代表竞品,紫色的代表T770。可以看到,在mobileNet-V2维度,T770在CPU量化、CPU浮点、加速器量化的处理上基本是优于竞品的。加速器浮点上略有差距,在mobileNet-V3 Large维度,T770在CPU量化、CPU浮点、加速器浮点的处理上是优于竞品的,加速器量化上略有差距,两者数据各有千秋,从MobileNet神经网络整体维度,T770优于竞品。 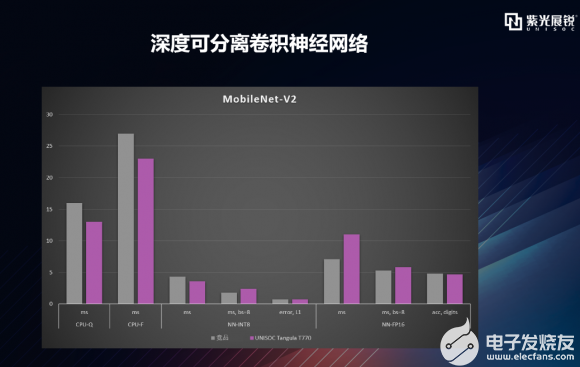 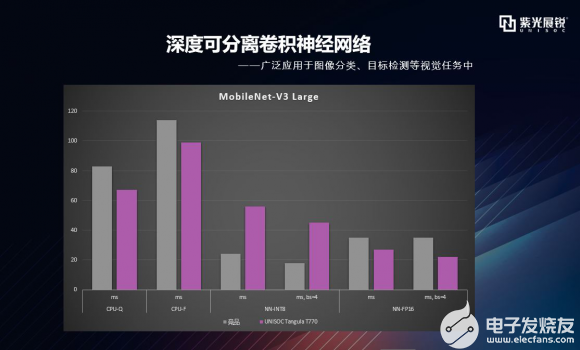 |
|
逐项拆解之Inception-V3 Inception-V3 架构的主要思想是 factorized convolutions (分解卷积) 和 aggressive regularization (激进的正则化)。可以看到,在精度基本一致的情况下,在CPU浮点、加速器量化这两个关键维度上,T770运行Inception-V3的运行速度更快,加速器浮点模型数据的运行速度上略有差距,但精度略优于竞品,如下图所示: 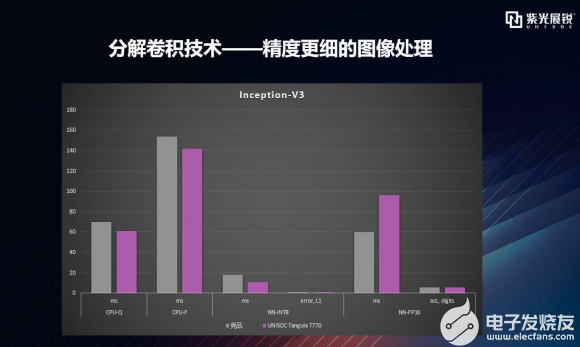 |
|
逐项拆解之EfficientNet EfficientNet是谷歌研究人员在一篇 ICML 2019 论文《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》中提出的一种新型模型缩放方法。可以看到,T770运行EfficientNet的表现与竞品相当,在CPU浮点、加速器量化、加速器浮点模型数据的运行速度上均有优势。 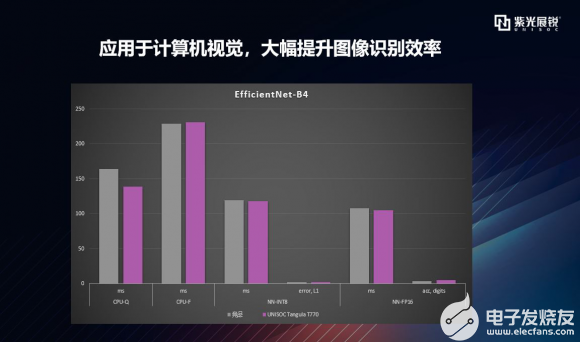 刚才提到的MobileNet、Inception-V3、EfficientNet网络结构常用于图像分类、目标检测、语义分割等技术开发中。这些神经网络结构可应用的常见场景有手机相册中的相册分类,手势识别等,工业上可用于快递分拣、头盔检测、头盔识别等场景,在医学领域会用于皮肤真菌识别等应用。当然这些神经网络所能支撑的场景,不限于刚刚介绍到的,可利用这些AI能力开发出更多的基于对物体/事物的分类场景。 T770在这些神经网络结构上的不俗表现表明:T770有更全面、更强大的能力去支撑这些场景的开发。 |
|
逐项拆解之Inception-V3 Parallel 接下来再看Inception-V3 Parallel (NN-INT8),你肯定会想,怎么又来一个Inception-V3,刚才不是show过了?是重复了吗?搞错了吗?当然没有!这里介绍的是Inception-V3 Parallel的能力,即同时处理多个Inception-V3,对应的是平台/设备对于AI并发处理的能力,怎么去理解这个并发处理呢?举个栗子吧,哦,今天忘记带栗子了,不好意思(╯▽╰)。 简单来讲,就是应用程序同时下发多个任务处理,再简单点讲就是,同时在做两件事情或多件事情,比如图片分类和手势识别同时进行。还不明白?再简单点,就好比人在吃饭的同时刷抖音短视频。 OK,我们来看下具体数据,下图显示的是AI加速器对1/2/4/8个量化模型同时处理的能力,可以明显看到,T770在AI多任务处理能力上占有明显优势。 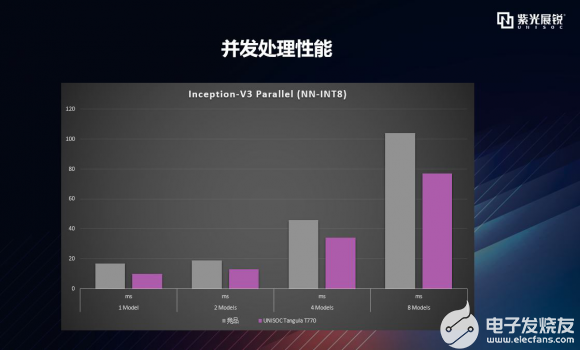 |
|
逐项拆解之Yolo-v4 Tiny 我们再看Yolo-V4 Tiny结构,它是Yolo-V4的精简版,属于轻量化模型,参数只有600万,相当于原来的十分之一,这使检测速度有了很大提升,非常有利于在端侧进行部署,在智能安防领域中已有大量应用,比如车辆识别、人员识别、路径预测和跟踪、行为分析、安全帽识别等。 先看下具体数据,如下图,除加速器量化模型部分略有不足之外,其他均有优势,如CPU量化、浮点,加速器浮点等。 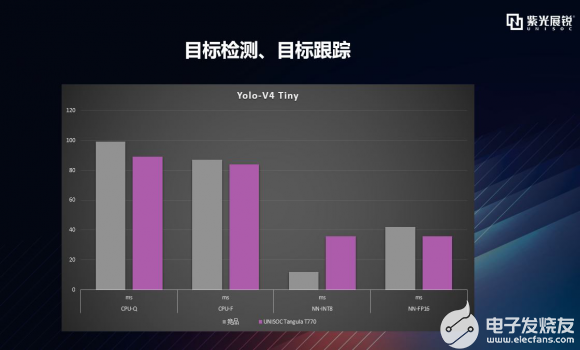 |
|
逐项拆解之DPED – ResNet 再看一下T770在DPED - ResNet处理维度的表现,解释一下,DPED是DSLR Photo Enhancement Dataset,而DSLR指的是Digital Single Lens Reflex Camera,即数码单反相机。讲到这一点,不得不提到一篇论文《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》,这是一篇发布于2017年关于图像增强的神经网络论文,大概成果就是将手机照片作为输入,将DSLR相机拍出的照片作为target,通过网络使其学习到一个映射函数,目的是让手机拍出单反相机照片的效果。 基于DPED,我们可以将老旧或低质量的照片转化为高质量的照片,而且转化效果很好,可用于照片美化等应用场景。如下图,可以看到T770在对DPED - ResNet处理的错误率一致的情况下,错误率都很低,处理速度上有明显优势。 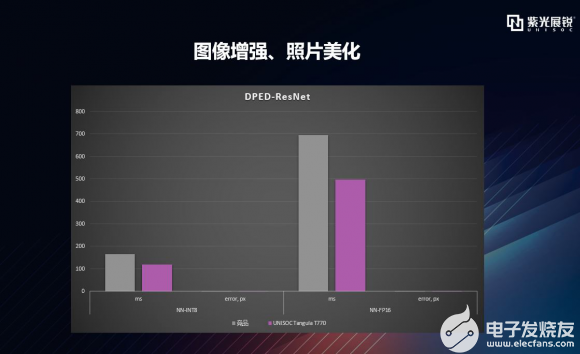 |
|
逐项拆解之LSTM 接下来,我们再看一下T770在长短期记忆网络(Long-Short Term Memory,LSTM)方面的性能。由于独特的设计结构,LSTM适合处理和预测时间序列中间隔和延迟非常长的重要事件。LSTM的表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好,比如用在不分段连续手写识别上。 2009年,用LSTM构建的人工神经网络模型赢得ICDAR手写识别比赛冠军。LSTM还普遍应用在自主语音识别,2013年,运用TIMIT自然演讲数据库实现了17.7%错误率纪录。作为非线性模型,LSTM可作为复杂的非线性单元,用于构造更大型深度神经网络。 下图可以看到,T770在对LSTM处理的错误率一致的情况下,处理速度上有着明显优势。 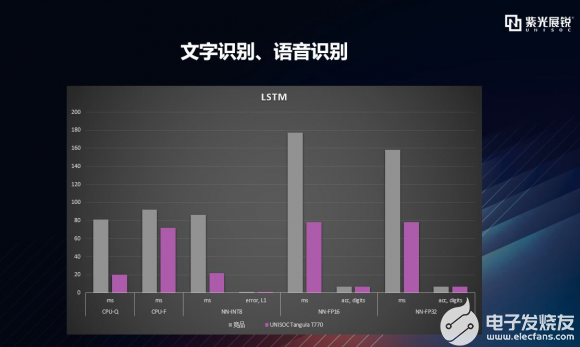 |
|
逐项拆解之U-Net U-Net是比较早的使用全卷积网络进行语义分割的算法之一,因网络形状酷似U而得名。图像语义分割(Semantic Segmentation)是图像处理和机器视觉技术中,关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。U-Net在医学领域也得到了应用,比如医学图像解析,也就是从一副医疗图像中,识别出特定的人体部位,比方说“前列腺”、“肝脏”等等。 下图可以看到,T770和竞品对U-net处理的错误率都极低,而T770在拥有极低错误率的同时,处理速度明显占优。 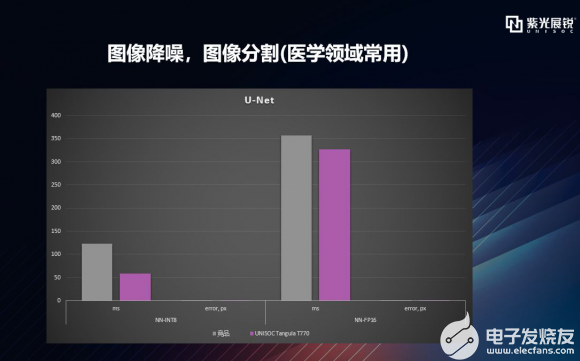 |
好了,数据对比分析先讲这么多,大家如果对T770在其他AI场景下的性能数据感兴趣,可前往AI Benchmark官网自行查看。
以上可以看到,T770有着不俗的AI性能,可以助力用户在相册分类、物体分类、智能美图、背景虚化、渲染、语音助手、智能家居、车牌识别,人脸识别、视频超分辨率应用场景中的落地实施,并且在满足常见CV/NLP应用场景下,可以同时满足实时、高并发的AI场景需求,如车牌识别、人脸识别等。
看罢T770的AI性能精彩展现,你是否会有疑问,T770是如何做到在AI上大放异彩的呢?下面我们来简单介绍下。
T770拥有多个可用于AI加速的设备,当然,有时候你拥有的资源越多,并不是一件好事,因为对资源的识别、管理和调度,会是一件极其困难的事情。所以,如何使T770上多个AI加速设备协同合作,并发挥出最大效能成为我们技术研发最主要的挑战。
大家都知道三个和尚挑水喝的故事:一个和尚挑水喝,两个和尚抬水喝,三个和尚没水喝。
故事很简单,道理也很简单,借这个故事,这里想表达的是三个核心问题:
一、任务来了,谁能干?
二、任务来了,谁来干更合适?
三、安排好活了,干活的是否积极?
为了解决上述问题,紫光展锐开发了两大核心技术:
1)Smart Schedule :采用智能算法,精准识别每个AI任务最适合在哪个加速器里进行处理,然后进行分配,使其随才器使;
2)Device Boost:采用智能调节算法,根据推理任务大小,智能调节加速器负载,使其张弛有度。
得益于紫光展锐开发的这两大核心技术,T770在AI性能上大放异彩,AI多变场景下,可以助力用户实现丰富的AI场景化落地。
而且,紫光展锐将持续针对多种AI场景进行优化,届时,T770的AI性能将得到更大提升,创新不止,敬请期待!
注:本文测试数据来源于AI Benchmark官网发布
-
紫光展锐亮相MWC 2023首度展示三款车规级商用芯片2023-02-28 1243
-
紫光展锐5G芯片T820通过沃达丰集团认证2023-02-23 1486
-
紫光展锐首发产品T760/T770现已成功实现客户量产2022-09-05 7022
-
紫光展锐5G和4G平台完成与Android 13的同步升级2022-08-25 2140
-
紫光展锐5G和4G平台同步向Android 13升级2022-08-24 1735
-
紫光展锐芯片与高通、联发科的对比介绍2022-04-27 45252
-
搭载展锐唐古拉T770芯片的5G手机通过抗老化性能认证2022-04-25 4432
-
搭载展锐唐古拉T770的5G手机获泰尔实验室权威认证2022-03-04 985
-
展锐携手产业生态伙伴,共同打造人民的5G2022-02-09 632
-
Imagination Series3NX神经网络加速器助力展锐打造其新一代5G智能手机平台2021-12-20 985
-
紫光展锐推出5G新品牌 丰田纯电动概念车公布2021-04-21 3588
-
紫光展锐首款5G基带芯片2019-09-18 4719
全部0条评论

快来发表一下你的评论吧 !
