

Python pacp模块:自动识别文字中的省市区并将其绘图
描述
一个用于提取简体中文字符串中省,市和区并能够进行映射,检验和简单绘图的python模块。
举个例子:
["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
↓ 转换
|省 |市 |区 |地址 |
|上海市|上海市|徐汇区|虹漕路461号58号楼5楼 |
|福建省|泉州市|洛江区|万安塘西工业区 |
注:“地址”列代表去除了省市区之后的具体地址
也可以将大段文本中所有提到的地址提取出来,并且自动将相邻的存在所属关系的地址归并到一条记录中(0.5.5版本新功能):
"分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区"
↓ 转换
|省 |市 |区 |
|上海市|上海市|徐汇区|
|福建省|泉州市|洛江区|
|江苏省|南京市|鼓楼区|
代码目前仅仅支持python3
pip install cpca
注:cpca是chinese province city area的缩写
如果觉得本模块对你有用的话,施舍个star,谢谢。
常见安装问题:
在 windows 上可能会出现类似如下问题
Building wheel for pyahocorasick (setup.py) ... error
先去下载 Microsoft Visual C++ Build Tools, 安装完成后,再重新使用 pip install cpca 安装,即可解决问题
开始使用
本模块中最主要的方法是cpca.transform,该方法可以输入任意的可迭代类型(如list,pandas的Series类型等),然后将其转换为一个DataFrame,下面演示一个最为简单的使用方法:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "北京朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str)
df
输出的结果为(adcode为官方地址编码):
省 市 区 地址 adcode
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 310104
1 福建省 泉州市 洛江区 万安塘西工业区 350504
2 北京市 市辖区 朝阳区 北苑华贸城 110105
如果你想获知程序是从字符串的那个位置提取出省市区名的,可以添加一个pos_sensitive=True参数:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "北京朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str, pos_sensitive=True)
df
输出如下:
省 市 区 地址 adcode 省_pos 市_pos 区_pos
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 310104 -1 -1 0
1 福建省 泉州市 洛江区 万安塘西工业区 350504 -1 0 3
2 北京市 市辖区 朝阳区 北苑华贸城 110105 -1 -1 0
从大段文本中提取多个地址(0.5.5版本新功能):
import cpca
df = cpca.transform_text_with_addrs("分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区")
df
结果为(注意 transform_text_with_addrs 获得的数据,“地址”列都是空的):
省 市 区 地址 adcode
0 上海市 市辖区 徐汇区 310104
1 福建省 泉州市 洛江区 350504
2 江苏省 南京市 鼓楼区 320106
transform_text_with_addrs 还支持和 transform 类似的 index, pos_sensitive 以及 umap 参数
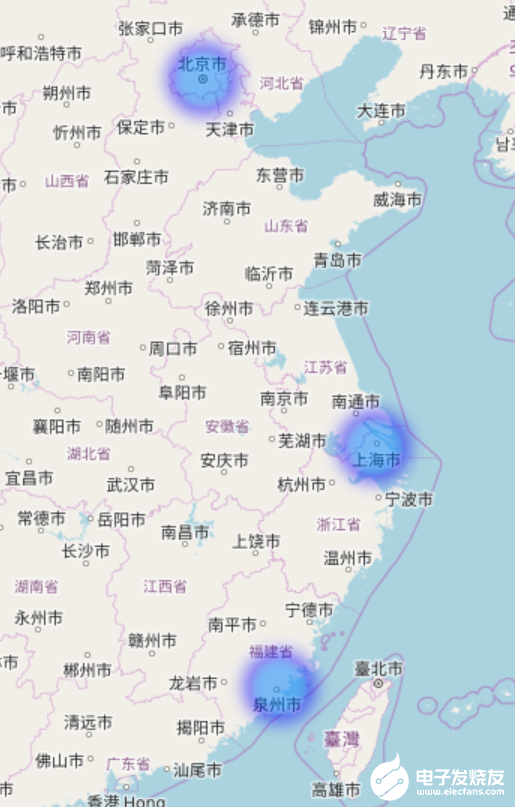
绘图:
模块中还自带一些简单绘图工具,可以在地图上将上面输出的数据以热力图的形式画出来.
这个工具依赖folium,为了减小本模块的体积,所以并不会预装这个依赖,在使用之前请使用pip install folium .
代码如下:
import cpca
from cpca import drawer
df = cpca.transform_text_with_addrs("分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区")
drawer.draw_locations(df[cpca._ADCODE], "df.html")
审核编辑 黄昊宇
-
如何实现串口的自动识别2012-03-23 5164
-
求助帖 labview自动识别2013-04-19 2644
-
请问USB自动识别芯片RH7901是怎样自动识别充电设备的?2018-05-22 2925
-
车辆自动识别称重系统的工作原理2021-03-01 2934
-
智能交通系统中的车牌自动识别技术有哪些应用呢2022-03-02 1505
-
Python pacp模块——自动识别文字中的省市区并绘图2022-06-27 2683
-
STLink是怎么自动识别STM32芯片型号的?2023-10-27 760
-
单总线数字温度传感器的自动识别技术2009-07-17 522
-
自动识别芯片在家居安防系统中的应用2009-09-04 578
-
基于射频技术的车牌自动识别装置设计2011-11-15 1219
-
Cpca 模块:自动识别文字中的省市区并绘图2023-10-21 2214
-
OCR如何自动识别图片文字2023-10-31 2006
-
数电票试点扩围至36个省市区 百望云解决方案助力企业数电升级2023-11-29 1139
-
如何使用Python进行图像识别的自动学习自动训练?2024-01-12 1851
-
水位自动识别摄像机2024-07-31 1410
全部0条评论

快来发表一下你的评论吧 !
