

机器学习和数据挖掘的关系
描述
在开篇之前,想和大家聊一下机器学习和数据挖掘的关系。
数据挖掘只是机器学习中涉猎的领域之一,机器学习还有模式识别、计算机视觉、语音识别、统计学习以及自然语言处理等。
机器学习即 ML,是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习作为人工智能研究较为年轻的分支,机器学习也分监督学习和非监督学习,同时随着人工智能越来越被人们重视和越热,深度学习也是机器学习的一个新的领域。
机器学习,从知识清单开始
我们第一天学开车的时候一定不会直接上路,而是要你先学习基本的知识,然后再进行上车模拟。
只有对知识有全面的认知,才能确保在以后的工作中即使遇到了问题,也可以快速定位问题所在,然后找方法去对应和解决。
所以我列了一个机器学习入门的知识清单,分别是机器学习的一般流程、十大算法、算法学习的三重境界,以此来开启我们的学习之旅。
一、机器学习的基本流程
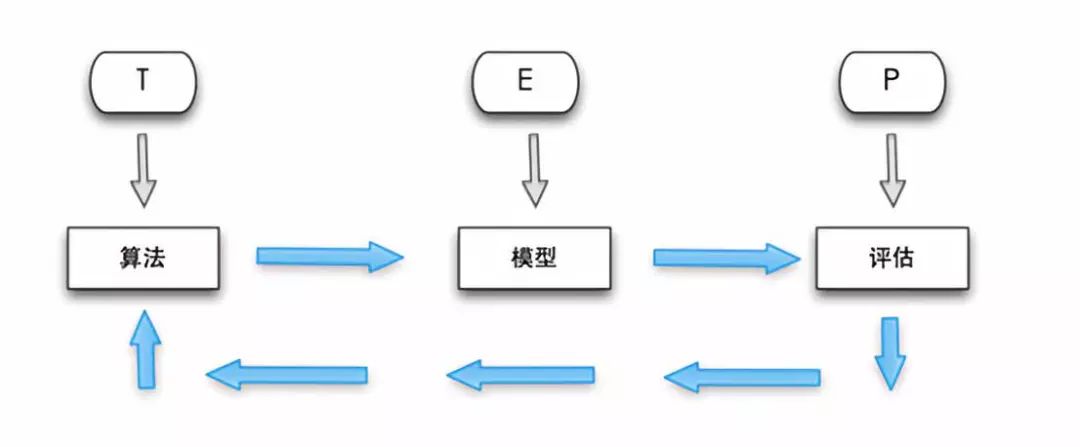
引用大佬的解释:
A computer program is said to learn fromexperience E with respect to some task T and some performance measure P,if itsperformance on T,as measured by P,improves with experience E. —Tom Mitchell
简单来说,机器学习就是针对现实问题,使用我们输入的数据对算法进行训练,算法在训练之后就会生成一个模型,这个模型就是对当前问题通过数据捕捉规律的描述。然后我们将模型进一步导入数据,或者引入新的数据集进行评估,根据结果的好坏反过来调整算法,形成反馈和优化闭环。整个过程机器在不断的学习、训练和优化迭代,这个也是机器学习强大的地方。
二、机器学习的十大算法
为了进行机器学习和数据挖掘任务,数据科学家们提出了各种模型,在众多的数据挖掘模型中,国际权威的学术组织 ICDM(the IEEE International Conference on Data Mining)评选出了十大经典的算法。
按照不同的目的,我可以将这些算法分成四类,以便你更好的理解。
分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
聚类算法:K-Means,EM
关联分析:Apriori
连接分析:PageRank
1. C4.5
C4.5 算法是得票最高的算法,可以说是十大算法之首。C4.5 是决策树的算法,它创造性地在决策树构造过程中就进行了剪枝,并且可以处理连续的属性,也能对不完整的数据进行处理。它可以说是决策树分类中,具有里程碑式意义的算法。
2. 朴素贝叶斯(NaiveBayes)
朴素贝叶斯模型是基于概率论的原理,它的思想是这样的:对于给出的未知物体想要进行分类,就需要求解在这个未知物体出现的条件下各个类别出现的概率,哪个最大,就认为这个未知物体属于哪个分类。
3. SVM
SVM 的中文叫支持向量机,英文是 SupportVector Machine,简称 SVM。SVM 在训练中建立了一个超平面的分类模型。
4. KNN
KNN 也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A。
5. AdaBoost
Adaboost 在训练中建立了一个联合的分类模型。boost 在英文中代表提升的意思,所以 Adaboost 是个构建分类器的提升算法。它可以让我们多个弱的分类器组成一个强的分类器,所以 Adaboost 也是一个常用的分类算法。
6. CART
CART 代表分类和回归树,英文是 Classificationand Regression Trees。像英文一样,它构建了两棵树:一颗是分类树,另一个是回归树。和C4.5 一样,它是一个决策树学习方法。
7. Apriori
Apriori 是一种挖掘关联规则(association rules)的算法,它通过挖掘频繁项集(frequentitem sets)来揭示物品之间的关联关系,被广泛应用到商业挖掘和网络安全等领域中。频繁项集是指经常出现在一起的物品的集合,关联规则暗示着两种物品之间可能存在很强的关系。
8. K-Means
K-Means 算法是一个聚类算法。你可以这么理解,最终我想把物体划分成 K 类。假设每个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点要归类,这时候就只要计算这个新点与K 个中心点的距离,距离哪个中心点近,就变成了哪个类别。
9. EM
EM 算法也叫最大期望算法,是求参数的最大似然估计的一种方法。原理是这样的:假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反过来知道了 B 也就得到了 A。可以考虑首先赋予A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这个过程一直持续到收敛为止。
EM 算法经常用于聚类和机器学习领域中。
10. PageRank
PageRank 起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank 被 Google 创造性地应用到了网页权重的计算中:当一个页面链出的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们可以得到网站的权重划分。
算法可以说是机器学习的灵魂,也是最精华的部分。这 10 个经典算法在整个机器学习领域中的得票最高的,后面的一些其他算法也基本上都是在这个基础上进行改进和创新。今天你先对十大算法有一个初步的了解,你只需要做到心中有数就可以了。
三、机器学习的三大境界
1. 掌握算法入口出口
第一重境界,将算法本身是做黑箱,在不知道算法具体原理的情况下能够掌握算法的基本应用情景(有监督、无监督),以及算法的基本使用情景,能够调包实现算法。
2. 理解原理,灵活调优
第二重境界则是能够深入了解、掌握算法原理,并在此基础上明白算法实践过程中的关键技术、核心参数,最好能够利用编程语言手动实现算法,能够解读算法执行结果,并在理解原理的基础上对通过调参对算法进行优化。
3. 融会贯通,设计算法
最后一重境界,实际上也是算法(研发)工程师的主要工作任务,即能够结合业务场景、自身数学基础来进行有针对性的算法研发,此部分工作不仅需要扎实的算法基本原理知识,也需要扎实的编程能力。
总结
今天我列了下学习机器学习你要掌握的知识清单,只有你对机器学习的流程、算法、原理有更深的理解,你才能在实际工作中更好地运用,祝你在机器学习的路上越走越远。
审核编辑 :李倩
-
机器学习与数据挖掘方法和应用2023-09-26 790
-
机器学习与数据挖掘的对比与区别2023-08-17 2764
-
聊一下机器学习和数据挖掘的关系2023-07-18 1634
-
机器学习和数据挖掘的关系(1)#大数据机器人未来加油dz 2023-07-10
-
[1.4.1]--4.机器学习和数据挖掘的关系jf_60701476 2022-12-05
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2893
-
Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘工具集2018-09-07 1539
-
《机器学习与数据挖掘:方法和应用》2018-06-27 1026
-
机器学习与数据挖掘的关系2018-01-05 6887
全部0条评论

快来发表一下你的评论吧 !
