

盘点一些用上先进制程工艺的RISC-V处理器
处理器/DSP
描述
电子发烧友网报道(文/周凯扬)无论是x86、Arm还是新秀RISC-V,大家谈及基于这些架构的处理器时,除了对比性能、功耗以外,不免会说到造就当下处理器差异化的另一大因素,那就是制造工艺。台积电、中芯国际、三星还有英特尔,随着如今几乎所有代工厂都参与到RISC-V的制造中来,我们不妨挑几个用上了先进工艺的RISC-V处理器看看。
台积电5nm+HBM3的RISC-V处理器 去年,SiFive旗下的OpenFive,一个用差异化IP提供定制方案的业务部门宣布正式流片了基于台积电5nm工艺的RISC-V处理器,该处理器集成的IP方案主要面向高性能计算/AI、网络与存储应用。
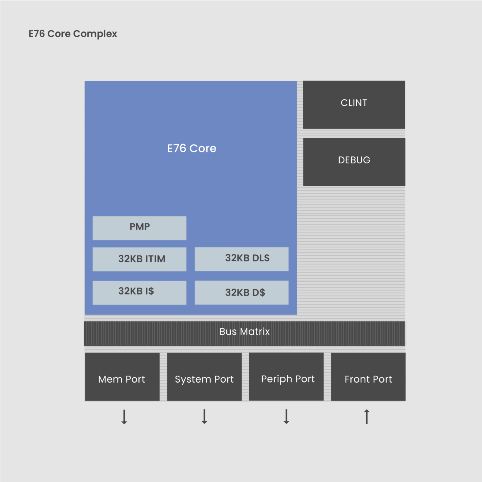
E76核心框图 / SiFive 这款SoC用到了OpenFive的HBM3 IP子系统和D2D I/O,CPU核心则选用了SiFive的E76,8级流水线的32位RISC-V核心。其HBM3接口给到了7.2Gbps的速度,足以满足任何计算密集型应用特定领域加速器的带宽需求。在D2D接口技术的支持下,该SoC可以通过2.5D封装实现更高的性能、更低的功耗与延迟。当然了,更重要的还是E76这个5.69CoreMark/Hz的RISC-V CPU核心。 不难看出,SiFive在高性能计算上有着自己的野心,哪怕目前Alphawave已经收购了SiFive的OpenFive业务部门。从SiFive和英特尔的关系来看,双方未来也会和继续合作,借助英特尔的IFS代工业务,为RISC-V处理器提供更先进的制造工艺,正如下面我们要提到的这款RISC-V处理器一样。
以Intel 4打造的近缓存计算RISC-V处理器 在我们已经看到的不少RISC-V处理器中,除了低功耗的以外,也有不少高性能的处理器,尤其是与AI/ML相关的。深度学习激发了一批数据并行的工作负载,而传统的SIMD处理器虽然解决了更多通用算力的问题,但其内存带宽还是无法这类应用的要求,这也是为何GPU和一众加速器在AI/ML上更受欢迎的原因。
Intel 4 RISC-V处理器样片 / 英特尔 在今年的VLSI22上,英特尔的研究工程师们带来了一个新的演示分享,一个全新的8核64位RISC-V处理器,代号Vela。该芯片完全基于Intel 4的CMOS工艺打造。在这一先进工艺的助力下,这个频率为1.15GHz的处理器仅仅占用了1.92mm2的面积,同时集成了512kB的共享LLC,每个核心分配了64kB SRAM。最关键的是Vela应用了近缓存计算(CNC)技术,使得该处理器在深度学习负载上展现了极佳的性能。
CNC不仅实现了高带宽的访问,也实现了在大容量片上SRAM中直接进行本地计算。而Vela将虚拟寻址,连贯性和一致性一并扩张到了CNC上,实现了可允许在Linux下的多核操作。与此同时,这个倒转芯片封装设计的处理器与一个FPGA相连,作为一个用于访问DRAM和IO的芯片组。 英特尔在分享中展示了CNC LLC的数据路径、CNC ISA规范以及编程模型,实际工作负载演示则为DNN提供了视觉化输入与输出。与将数据从LLC移动到核心内不同,CNC将成绩累加运算搬到了LLC上,就地处理数据。如此一来避免了片上网络的带宽瓶颈,同时减少全局数据的移动,增加了吞吐量提高了能效。英特尔的研究员也给出了具体提升数据,与标量处理相比,其吞吐量提升了46倍;通过减少数据移动,其整体功耗降低了11%,推理功耗降低至52分之一;在MLPerf的异常检测测试中,Vela将延迟降低了4.25倍,低至40μs。
不少人猜测这会不会是SiFive与英特尔打造的Horse Creek平台,毕竟该平台用到的也是英特尔的7nm工艺(Intel 4)。不过在英特尔和SiFive双方去年的声明中,都提到了Horse Creek将使用SiFive的P550核心,一个13级流水线三发射的高性能RISC-V核心。但从其1.15GHz的频率和1.92mm2的面积来看,很可能不是,至少不会是完整的Horse Creek。
结语 其实要说现在RISC-V处理器所用的工艺,还是7nm和之前的成熟工艺居多,毕竟RISC-V现在软硬件生态都还在高速发展中,并没有选择与Arm或x86在通用CPU和手机SoC上硬碰硬。也许RISC-V不像Arm的公版核心一样,有那么清晰的定位,但可以预见RISC-V未来覆盖的市场很快就会与Arm重合,所用工艺的差距也将缩小,届时观察各大半导体厂商的选择才更有趣。

-
fpga和risc-v处理器的区别2024-03-27 3126
-
基于形式的高效 RISC-V 处理器验证方法2023-07-10 2063
-
香山处理器 RISC-V的典范2023-04-14 834
-
关于RISC-V 处理器验证的问题2023-03-22 1204
-
从零开始写RISC-V处理器之一 二 前言 绪论2022-08-22 5237
-
4nm、5nm,那些用上先进工艺的RISC-V处理器2022-06-24 5076
-
RISC-V系列处理器的相关资料推荐2022-02-28 1470
-
RISC-V开源处理器核介绍2021-07-23 2455
-
RISC-V是什么?如何去设计RISC-V处理器?2021-06-18 2804
-
RISC-V是通用RISC处理器还是可定制的处理器?2020-11-17 4731
-
学习RISC-V入门 基于RISC-V架构的开源处理器及SoC研究2020-07-27 4460
-
关于RISC-V和开源处理器的一些解读2020-06-22 2308
-
晶心科技推出突破性的RISC-V 27系列处理器及向量扩展指令处理器2020-01-03 3821
全部0条评论

快来发表一下你的评论吧 !
