

关于工程安全保护的FPGA设计方案
描述
随着设计需求的不断复杂化,设计工程规模的越来越大,整个设计会分给多个人,甚至多组人来协同开发。每个部分由擅长的人来处理。
如果一个设计是由多个组/公司来协同完成的,通常会引入一个新问题:知识版权的保护。有些创新的设计方案并不想让对方简单获取。这样,就有对原始设计进行保护的一些方案。
还有一种情况是,整个FPGA设计都由一个组来进行设计,但是不希望硬件层面上被简单复制(防止抄板),所以对整个FPGA的设计及交付的配置镜像,也需要一些保护方案。
文本简单讨论一下相关的保护方案。请注意,没有一种方案可以百分之百保护设计的安全。大部分方案只是提高破解成本。当破解成本比较高的时候就足够了。
关于子模块的方案保护
这种情况常见于两组(或者更多组)协同开发一个工程,其中一组设计一个子模块,并将设计交予另一组进行系统集成,同时不希望系统集成的人员获取原始设计思路。
这种情况最常见的方案就是IP。FPGA的EDA工具ISE、Vivado和Quartus都提供了大量IP,其中的不少IP都是不提供底层源码的。用户可以使用但是并不能获取原始设计。
比较常见的做法是提供综合后的网表。ISE使用综合后的ngc文件,Vivado的网表文件都是dcp文件。Quartus中使用过qxb和qdb文件。另外Vivado也是支持通用的EDIF格式文件,Quartus没有确认过,不过道理上应该也是支持EDIF的。
Vivado dcp文件就是一个zip压缩包
使用网表就可以正常进行布局布线。优点是制作/提供网表的操作上手方便,使用简单。弊端是:
1.不方便调式,尤其是不方便在系统集成时使用嵌入式逻辑分析仪;
2.如果时序有问题,不容易做优化;
不过使用IP、网表和其他原设计保护方案都有这个问题,所以算是通病,也没有很好的办法解决。
使用网表的另一个问题是无法仿真,尤其是ngc/dcp这样EDA工具自己定义的网表格式。IP内部除了包含网表文件还有仿真需要的文件。综合/布局布线时使用对应的网表,仿真时使用仿真专用的文件/网表。所以单单提供网表,对仿真是个大问题。如果有额外的人力,可以提供相关仿真文件。但是为了保证网表和仿真文件行为一致,并且需要依据项目的进度进行网表文件与仿真文件的同步更新,这个工作量并不小。通常只有专业的团队,才会有足够的人员来做这件事情。
这其实也就是版本管理的困难,当版本中的文件越来越多,版本管理的难度就越来越来。通常子模块的设计团队都很难有足够的人力/时间来很好的处理可综合设计和不可综合的仿真版本之间的版本管理。这里需要注意的是
仿真版本设计的难度并不比可综合设计简单。
1.如果简单的提供可综合版本的源代码,则无法起到保护原始设计的作用。
2.如果使用加密或者仿真工具支持的非源代码格式,首先要保证仿真工具支持这个功能,其次绑定了工具对版本管理也是增加了负担。
3.比较常用的方法是使用不可综合的仿真代码来实现一样的功能。这就需要较为复杂的设计。代码中要尽量做到不涉及原始设计思路,等于是要彻底换一个思路来设计一样的东西,而且还要尽量做到难看懂。
还有一种做法就是用C语言实现功能,然后用Verilog和C语言的接口来实现仿真。这样核心功能是C语言实现的,自然保证了无法综合。同时,软件语言也更加容易做到无法获取原始设计思路。这部分可以参考Verilog PLI。
这里要插一句,Vivado工具可以将dcp文件,进行适当分析并生成Verilog文件。生成的文件可读性很差,但是可以用于仿真。不过从功能角度说,工具反推回来的Verilog是否正确,就不太容易保证了。本人曾经尝试过这种方法,在仿真阶段遇到了诸多问题,虽然最终可以解决问题并且实现仿真,但需要修改和调整的地方还是非常多的,有一定的工作量。
目前Xilinx Vivado工具提供了一种加密方式来对源代码进行加密。使用这种方法后,可以直接提供加密后的源代码。这样的好处很多:1.源代码不绑定器件,所以跨器件的移植更容易;2.原代码参与综合,这样综合工具可以在综合阶段就有机会进行合适的优化;3.不影响仿真。
这种方法几乎和源代码一样、唯一的问题是需要解密。由于Vivado是全功能的工具(Quartus的仿真功能使用的是Modelsim,所以严格说不是全功能的工具),所以只要购买了这一功能的license,就可以用Vivado工具来进行设计。不过同时带来的问题是,只能使用Vivado。具体的影响是:
1.使用的器件必须是Vivado所支持的,也就是说如果设计需要在Spartan-6或者Altera的器件上运行,就需要另外的加密手段,也就无法统一保护代码/设计的手段,从公司和项目角度来看,这种方法会增加维护的成本。
2.部分公司的开发流程是使用独立的仿真工具/综合工具,这样就需要第三方工具也支持这个加密与解密,可能会一定程度上限制使用。
第三种保护原始设计的方法,拥有之前两种方法的几乎全部缺点,而且更加麻烦。但是相对的,保护原始设计的程度最高。这种方法就是,部分动态重配置。
这种方法的做法是子模块的设计团队可以获取顶层工程,然后依据工程设计出子模块的部分动态重配置的配置文件。FPGA最终加载的时候,先加载不包含子模块的静态部分配置文件,然后加载子模块的配置文件,通过两次加载来组合出完整的功能。
这种方法的优点是最终提供的是配置文件,所以几乎不可能恢复出原始设计,而且部分的配置文件和整体工程是相关联的,导致一个配置文件只适配一个工程(甚至只适配一个工程的一个版本)。这样就非常容易控制好子模块的使用情况。但缺点就是过于复杂和麻烦,不仅仅无法仿真,无法调试,而且也固定器件型号,并固定EDA工具版本。同时还需要做大量的时序优化来减少设计分区对时序的影响。由于这一方案的成本过高,所以只有极为少数的公司在非常看重保密的条件下,才会使用动态重配置技术。
最后一种方案是从可读性入手。如果源代码的功能正常,但是可读性非常非常差,就可以既保证源代码的使用,同时又可以一定程度来保护原始设计。这种方法可以称之为代码加扰,或者代码混淆。(下文会使用代码混淆这个称呼)
代码混淆是在不违反语法错误的条件下对信号名和代码结构进行重新处理,处理后的代码可读性非常非常低。通常情况下,在不熟悉代码结构的时候就直接读没有文档没有注释代码,本身就是一个非常辛苦的工作(所以基本上写代码的童鞋都不愿意读别人写的代码)。如果再对变量名和代码结构做一定程度的调整,可以大大增加读代码的困难。通读代码、理清结构的成本已经和完全重新设计差不多高,以此来达到保护设计的目的。
通常代码混淆分为变量混淆和格式混淆。变量混淆是将信号名全部替换成无意义的字符串。格式混淆是将代码格式进行打乱,不容易理解代码的“分段”,从而增加理解代码结构的难度。从最终出来的效果看,想要读懂代码的难度实在太大了。
这种方法交付的依然是原始代码,拥有源代码的所有优点,可以进行仿真,便于移植。同时由于是合乎语法的处理,所以对工具没有任何限制。所以呢,如果看到一个写的很糟糕的代码,不要直接下定义认为是作者太随意或者水平太差,也许是故意写出来不想让别人看懂呢。
FPGA配置文件的保护方式
通常配置文件是保存在FPGA片外Flash中。FPGA和Flash之间的连接是通过PCB连线。这样的问题是,很容易获取Flash中的原始数据(取下Flash或者截取加载时的原始数据)。为了对配置文件进行保护,Xilinx平台的FPGA可以有以下几种方案可以考虑。Altera平台没有深入的研究过,猜测推想,应该是有类似的加密功能。
内置Flash
部分FPGA芯片内置了配置用的Flash,这样很好的保护了Flash和其于FPGA的连接。一般来说很难获取Flash中的数据。目前这一类芯片有Xilinx Spartan-3AN和Altera Max10。这一方案比较大的问题是,可选芯片太少。
AES加密
Xilinx的FPGA提供了AES加密功能,具体就是由用户定义一个(或者用工具随机生成一个)密钥,存储在FPGA中,同时对bit文件进行加密。由加密后的bit文件衍生的MCS/BIN文件都是经过了加密的,所以最终Flash中存储的版本也是经过加密的。这样即使Flash中的数据被获取,没有密钥也无法使用。根据密钥存储的不同分为AES-BRAM和AES-EFUSE。
AES-BRAM是将密钥存储在一个特殊的BRAM中,这个BRAM可以用单独的电源供电。当彻底掉电时,密钥立即丢失,无法回复。所以这一方案需要为存储密钥的BRAM电源提供一个纽扣电池进行供电。
AES-EFUSE是将密钥存储在FPGA内置的,只能写入一次的EFUSE寄存器中,同时必须使用原厂的JTAG Cable。写入后密钥将永远保存在EFUSE中,用于解密。
DNA加密
Xilinx的FPGA,每一个芯片都有一个唯一的编码,成为eFuse ID。这个eFuse ID是64bit,其中57bit作为DNA提供给客户使用。大部分情况下,用户拿到的量产芯片中,DNA是不会重复的。此时可以作为一个加密的方法。
DNA加密的原理是在设计中加入读取DNA的模块,读取DNA后和内置存储的数据作对比,如果发现不一样则停止工作。
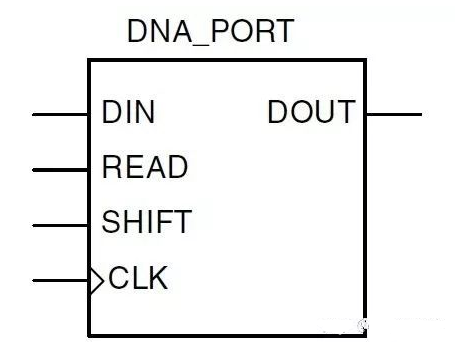
由于这种方法是写入设计中的,所以如果没有原始工程,几乎无法破解。另外DNA又几乎不会重复,所以一个bit文件对应一个FPGA芯片,可控性非常好。但是麻烦的是,对于量产的产片,每个产品都需要准备一个bit文件,这很大程度上加大了生产成本。
由于这个问题,出现了几种DNA用法的变种。
1.自动处理DNA
这种方法是在设计中先查看Flash特定的区域,是否有需要的标识符。如果没有,则自动读取DNA,并通过一定的加密计算(当然也可以直接使用原始数据)换算出另一个值,然后将数据写入Flash,并填充标志位。如果发现有标志位,则按规定的地址读取DNA数据,进行解密,然后和DNA进行对比。这种方案及利用了DNA的唯一性,又便于批量生产。但是代价是DNA数据是存储在Flash中的。如果检查Flash的数据,是有机会找到DNA的数据,此时结合FPGA的DNA原始数据,在加密算法不麻烦的情况下有机会做解密。这样是可以进行破解的。如果使用更强大的加密算法,又会增加设计的成本。
2.部分动态重配置
主体设计中不包含DNA信息,将DNA的读取和识别放入一个占用资源极少、交互接口最简单的动态重配置部分,这样极大的降低使用部分动态重配置的难度。在生产环节,交付统一的配置文件进行生产。在测试环节,如果产品需要逐一进行测试(现在很多电子产品都是100%测试而不是抽查),选择合适的动态配置文件写入Flash进行测试。这样一定程度上降低了使用成本并有较高的保密性。这种方案仅适合需要对产品进行100%充分测试的生产流程,否则依然会极大的提高生产成本。
- 相关推荐
- 热点推荐
- FPGA
-
基于CPLD/FPGA的多串口扩展设计方案2023-10-27 641
-
电力变压器保护设计方案2023-10-23 1876
-
基于FPGA的伪随机数发生器设计方案2021-06-28 5025
-
基于CPLD/FPGA的半整数分频器设计方案2021-06-17 1177
-
基于FPGA的二进制相移键控设计方案2021-05-28 1297
-
基于FPGA的调焦电路设计方案资料下载2018-05-07 1430
-
基于FPGA的OLED真彩色显示设计方案2017-01-18 1030
-
基于FPGA的变频器设计方案,利用simulink仿真2014-09-10 3156
-
FPGA典型设计方案精华汇总2012-08-16 12340
-
提交FPGA设计方案,赢取赛灵思FPGA开发板2012-07-06 10495
-
FPGA设计大赛设计方案提交规则和截止时间须知2012-05-04 20968
-
从ASIC到FPGA的转换系统时钟设计方案2011-03-02 2961
-
多种EDA工具的FPGA设计方案2010-05-25 947
-
锅炉汽包水位保护设计方案2010-04-01 740
全部0条评论

快来发表一下你的评论吧 !
