

ADS算力芯片的多模型架构研究
描述
在过去十几年里,深度神经网络(DNN)得到了广泛应用,例如移动手机,AR/VR,IoT和自动驾驶等领域。复杂的用例导致多DNN模型应用的出现,例如VR的应用包含很多子任务:通过目标检测来避免与附近障碍物冲突,通过对手或手势的追踪来预测输入,通过对眼睛的追踪来完成中心点渲染等,这些子任务可以使用不同的DNN模型来完成。像自动驾驶汽车也是利用一系列DNN的算法来实现感知功能,每个DNN来完成特定任务。然而不同的DNN模型其网络层和算子也千差万别,即使是在一个DNN模型中也可能会使用异构的操作算子和类型。
此外,Torch、TensorFlow和Caffe等主流的深度学习框架,依然采用顺序的方式来处理inference 任务,每个模型一个进程。因此也导致目前NPU架构还只是专注于单个DNN任务的加速和优化,这已经远远不能满足多DNN模型应用的性能需求,更迫切需要底层新型的NPU计算架构对多模型任务进行加速和优化。而可重配NPU虽然可以适配神经网络层的多样性,但是需要额外的硬件资源来支持(比如交换单元,互联和控制模块等),还会导致因重配网络层带来的额外功耗。
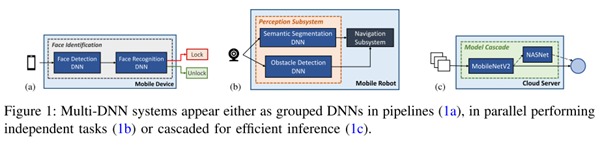
开发NPU来支持多任务模型面临许多挑战:DNN负载的多样性提高了NPU设计的复杂度;多个DNN之间的联动性,导致DNN之间的调度变得困难;如何在可重配和定制化取得平衡变得更具挑战。此外这类NPU在设计时还引入了额外的性能标准考量:因多个DNN模型之间的数据共享造成的延时,多个DNN模型之间如何进行有效的资源分配等。
目前的设计研究的方向大体可以分成以下几点:多个DNN模型之间并行化执行,重新设计NPU架构来有效支持DNN模型的多样性,调度策略的优化等。
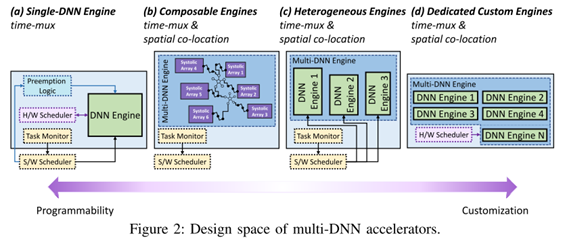
DNN之间的并行性和调度策略:
可以使用时分复用和空间协同定位等并行性策略。调度算法则大概可以分为三个方向:静态与动态调度,针对时间与空间的调度,以及基于软件或者硬件的调度。
时分复用是传统优先级抢占策略的升级版,允许inter-DNN的流水线操作,来提高系统资源的利用率(PE和memory等)。这种策略专注调度算法的优化,好处是对NPU硬件的改动比较少。
空间协同定位则专注于多个DNN模型执行的并行性,也就是不同DNN模型可以同时占用NPU硬件资源的不同部分。这要求在设计NPU阶段就要预知各个DNN网络的特性以及优先级,以预定义那部分NPU硬件单元分配给特定的DNN网络使用。分配的策略可以选择DNN运行过程中的动态分配,或者是静态分配。静态分配依赖于硬件调度器,软件干预较少。空间协同定位的好处是可以更好的提高系统的性能,但是对硬件改动比较大。
动态调度与静态调度则是根据用户用例的特定目标来选择使用动态调度或者静态调度。
动态调度的灵活性更高,会根据实际DNN任务的需求重新分配资源。动态调度主要依赖于时分复用,或者利用动态可组合引擎 (需要在硬件中加入动态调度器),算法则多数选择preemptive策略或者AI-MT的早期驱逐算法等。
对于定制化的静态调度策略,可以更好的提高NPU的性能。这种调度策略是指在NPU设计阶段就已经定制好特定硬件模块去处理特定神经网络层或者特定的操作。这种调度策略性能高,但是硬件改动比较大。
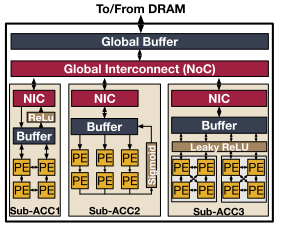
异构NPU架构:
结合动态可重构和定制化的静态调度策略,在NPU中设计多个子加速器,每个子加速器都是针对于特定的神经网络层或者特定的网络操作。这样调度器可以适配多个DNN模型的网络层到合适的子加速器上运行,还可以调度来自于不同DNN模型的网络层在多个子加速器上同步运行。这样做既可以节省重构架构带来的额外硬件资源消耗,又可以提高不同网络层处理的灵活性。
异构NPU架构的研究设计可以主要从这三个方面考虑:
1)如何根据不同网络层的特性设计多种子加速器;
2)如何在不同的子加速器之间进行资源分布;
3)如何调度满足内存限制的特定网络层在合适的子加速器上执行。
审核编辑 :李倩
-
大算力芯片的生态突围与算力革命2025-04-13 2802
-
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南2024-08-16 3907
-
大模型时代的算力需求2024-08-20 1015
-
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析2024-09-02 3685
-
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受2024-10-08 1054
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览2024-10-15 2051
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理2025-06-18 1491
-
国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?2025-10-27 2280
-
AI算力研究框架(2023)2023-06-15 1624
-
浅谈为AI大算力而生的存算-体芯片2023-12-06 820
-
浪潮信息与智源研究院携手共建大模型多元算力生态2024-12-31 921
-
科技云报到:要算力更要“算利”,“精装算力”触发大模型产业新变局?2025-01-16 881
-
DeepSeek对芯片算力的影响2025-02-07 1700
-
AIGC算力基础设施技术架构与行业实践2025-05-29 732
全部0条评论

快来发表一下你的评论吧 !
