

如何判断视频是不是VR视频
vr|ar|虚拟现实
描述
VR眼镜层出不穷,VR 应用如雨后春笋,它们消费的内容主要有图片,视频和游戏3种。当前优酷,搜狐,乐视,爱奇艺,Youtube等比较大的视频网站,都推出了VR视频专区,各种比较小的专注VR视频的网站多不胜数,其中比较有名的有Utovr,591vr等。用户在使用QQ手机浏览器(Android)过程中视频的播放量很大,其中不可避免的会有VR视频。
VR视频一般是mp4格式,与普通视频无异。mp4视频里面并没有标记这是一个普通视频,还是一个VR视频。一般网站或者应用里面区分VR视频的做法是,在后台的数据库里面有个字段标记。但是QQ浏览器里面的播放器只能拿到一个视频的URL,无法知道这是一个普通视频还是VR视频,所以播放的时候只能按照普通视频去渲染。

VR视频眼镜播放模式(可以转动手机查看周围)

VR视频普通播放模式
如何判断视频是不是VR视频
前面已经说了,QQ浏览器的视频播放器只能拿到一个视频的播放地址,所以判断是否VR视频,只能从视频本身出发。观察以下VR视频和普通视频的截图两端红框区域,发现VR视频的两端边缘相似度较高,而普通视频的边缘相似度很差。VR视频识别的算法就是基于这个现象,获取一个视频多个帧的图片,然后给出视频是VR视频的概率。
算法存在的问题
通过上面的介绍,知道这个算法是根据图片边缘相似性得到结果,出于效率的考虑检查的图片数量和检查的粒度不能设置太高,那么它得到的结果会有两个不可避免的问题:将VR视频识别为普通视频;将普通视频识别为VR视频。如以下示例:
对于这样一个计算概率性的算法,需要找到尽量多的失败用例,然后根据失败的特点来改进算法。为了发现失败用例,需要一个很大的测试集,这个测试集合里面包含了一个VR视频集合,以及一个普通视频的集合。这个集合的作用是尽量使VR视频正确识别,又要保证普通视频不会被识别为VR视频。这个集合最好还要易于增加测试源,用来验证算法的有效性。
测试集的建立
最开始测试集合是到网络上下载VR视频,保存到本地,然后用来测试验证。这种方式的优点是测试的速度很快,因为都是本地视频。但是缺点也很明显,VR视频的size太大(5 分钟的视频经常会上 G)本地保存比较麻烦;每次去网上找下载太耗时,不容易增加,而且容易重复。
现在的测试集合保存的是视频网页的网址,网址有爬虫爬取。当前做了12个网站的爬虫,基本包含了国内主流的视频网站和VR 视频网站。
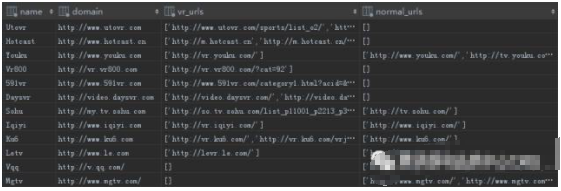
支持的主流网站(source表)
在爬虫里记录了网站经常更新的页面(一般是网站的分类网址:如优酷的电视剧,电影分类的 URL),爬虫运行时将爬去到的页面地址保存到Video表。保存前会自动分析页面的特征,判断该页面的视频是不是 VR 视频,并将结果一起保存到video表,从而建立VR视频集合以及普通视频集合。
测试过程中如果发现有的视频源已经失效,需要在video表中标记无效,不用删除视频源,避免下次再次加入。如果是自动化能识别的失效可以自动化标记(如:视频已经下线跳转到404页面),否则需要人工根据测试结果标记。
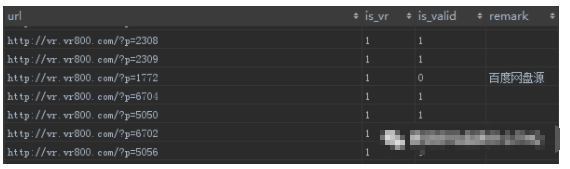
测试集合内的视频(video 表)
当前测试集合的VR视频数量有2500个,普通视频数量有7000 个,由于现在的测试工具尚不支持https的测试源,所以有些视频还没有测试过。
测试准备
有了爬虫就可以建立测试集,有了测试集还需要测试工具。测试工具是开发提供的一个exe程序,程序的调用方式:VideoDetector.exe -c 30 -u http://www.xxx.mp4 ,调用后的返回结果是视频为VR视频的概率,如果出错返回 -1。
测试集和测试结果都保存在数据库中,数据库中有 4 张表。上面已经介绍了source和video表,分别支持的网站和爬虫爬取的视频网页。还有一个task表,用来记录每次测试的结果,另外还有一个result表,用来记录每个视频的测试结果。

以上是最近的一次测试结果,更新算法后,验证 VR 视频的成功率提升了 20%,验证非 VR视频的成功率下降了 3%。 使用该方案后,能快速了解算法对视频识别率的影响,并能方便获取失败用例,用来改进算法。
- 相关推荐
- 热点推荐
- vr
-
TVP5150是不是可以通过读什么寄存器来判断是否有视频输入?2025-02-10 379
-
请教3G视频传输是不是必须经过互联网?2012-07-08 3300
-
Youtube推出VR180视频格式 打造沉浸立体视频2017-06-27 2913
-
如何判断输入的数据是不是整数2017-08-06 9545
-
5G+VR视频产业已启航2019-04-22 1558
-
请问论坛是不是不能插入视频?2020-05-21 1263
-
如何判断视频花屏的原因?2023-09-19 731
-
VT/VR音视频光端机2010-12-23 1671
-
视频打印机的安全标准2009-12-31 1190
-
itunes怎么导入视频_itunes导入的视频在哪2017-12-19 58476
-
拆解索尼Play Station VR的视频2018-07-05 8737
-
什么全景视频 什么是VR视频2019-06-23 15631
-
把VR视频转换成普通视频的步骤2020-05-28 116361
-
如何判断步进电机是不是失步2020-09-25 8436
-
怎么判断是不是线性电路2023-12-15 3794
全部0条评论

快来发表一下你的评论吧 !
