

AI和内存类存储结合节省成本
人工智能
描述
采用人工智能 (AI) 应用程序的曲棍球棒正在顺利进行,包括 CPU、GPU、FPGA 和神经网络处理器在内的定制架构正在云中占据一席之地。人工智能大规模并行架构的弱点之一是对电源故障时数据丢失的敏感性,导致这些数据中心的成本很高。内存类存储架构为 AI 应用程序提供高性能、持久的内存,使数据中心的正常运行时间、更低的功耗和更高的利润达到新的水平。
人工智能 (AI) 和深度学习算法的迅速普及正在改变现代数据中心的格局。随着云成为信息的通用资源,包括语音识别、增强现实、医学数据挖掘和成千上万的其他应用程序正在捕获越来越多的数据周期。我在这里使用的简单术语 AI 意味着许多类型的应用程序的集合,其中一些具有截然不同的技术要求。
云也是大多数企业的主要收入来源,正常运行时间已成为一项主要要求。系统停机造成的损失平均为每分钟 22,000 美元,每年平均 14.1 小时的停机时间使平均每年损失 1800 万美元。完全依赖互联网的公司很容易看到间接费用的倍数。
显然,如果解决方案能够最大限度地减少停机时间并加快从电源故障中恢复的速度,那么投资回报就会很快。将内存类存储(以下定义的术语)引入数据中心,尤其是 AI 处理器子系统是提高数据中心价值的关键性能增强。
常见的人工智能应用
人工智能并不新鲜,尽管大规模部署人工智能是最近的趋势。人工智能处理中心没有单一的架构,但是在人工智能的部署中出现了一些共同的趋势。一般来说,人工智能使用大量相对简单的处理单元在非常广泛的数据集上并行运行,每个处理单元都在数据的一个子集上运行。
为了帮助可视化这是如何工作的,想象一个 JPEG 图片处理算法,它有一个小型处理单元,为 8x8 像素阵列运行离散余弦变换算法 (DCT)。由于典型的原始图片远大于 8x8 像素,因此 AI 引擎可以包括许多并行运行的处理单元,每个处理单元运行相同的 DCT 算法,然后有一个主控制器将整体图片的 8x8 部分提供给处理单元。主控制器将来自每个处理单元的结果反馈到结果的输出缓存中,例如编码的 JPEG 文件的数据。
这些并行处理元素还可以选择在它们之间共享数据,例如管理相邻输入数据块之间的边缘。该解决方案的一种方法是递归神经网络 (RNN),如图 1 所示。
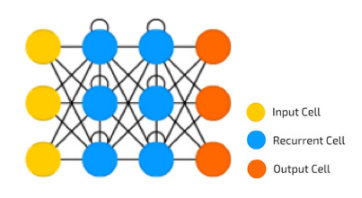
[图1 | 递归神经网络处理]
将 AI 的使用与功耗成本联系起来,上面的简单 RNN 应用程序显示了当黄色输入数据和橙色输出数据存储在动态内存中时的固有开销。在数据丢失时,必须重新加载输入数据并重新运行 RNN 算法以恢复输出数据。
深度学习是 AI 的另一种变体,它对数据吞吐量表现出更高的敏感性。深度学习算法将种子模式加载到 AI 内存中,该模式表示对预期可能答案的预先计算估计。深度学习的示例包括语音识别,其中种子数据可能代表通用语音模式。但是,一旦输入数据开始流过处理单元,深度学习就可以修改种子模式。对于语音识别,这可能包括针对特定用户的口音调整识别引擎。深度卷积网络是一种添加识别、上下文和修改种子以提高算法质量和准确性的机制。
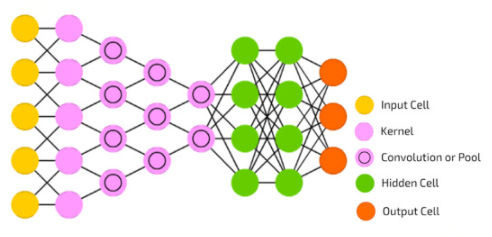
【图2 | 深度卷积网络处理]
深度学习算法面临的一个挑战是避免重新训练。想象一下每次将语音识别设备移到不同房间时都必须重新训练语音识别设备的客户的反应。对于深度学习,修改后的种子模型需要定期检查点,以便在断电后可以恢复学习到的数据。在图 2 中,绿色圆圈代表这些模型,如果这些数据丢失,则必须重新学习对模型的任何更新。粉红色双圆圈中的池化层还包含加速处理的信息,必须保存或重建。
常见的 AI 架构
如前所述,业界在人工智能架构的硬件实现方面存在趋势。这些趋势是:1) 将大量数据馈送到广泛的处理元件阵列中,2) 每个处理器在相对简单的算法上运行,以 3) 产生输出数据,该输出数据被重新组合成所需的结果。4)对于深度学习,这些中间结果可以修改需要定期提取的初始输入数据集。
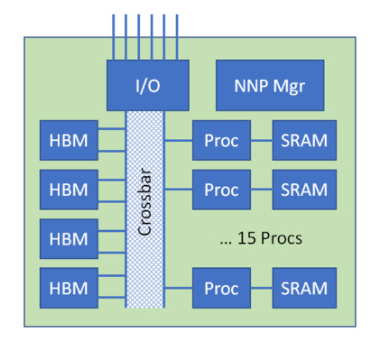
【图3 | 示例 AI 处理器]
图 3 显示了一个相当典型的 AI 设备,其中 15 个处理元件的阵列通过内部存储器交叉开关连接到使用高带宽存储器的大型数据资源(例如,32 GB)。HBM 提供一个 1024 位宽的接口,每个数据引脚以 2.4 Gbps 的速度运行,并且通过四个内部 HBM 总线,可以以大约 1.2 TB/s 的组合吞吐量为处理元件提供数据。
此外,每个 AI 设备都提供多个高速串行 I/O 接口(例如 1 Tbps),以将架构扩展到大量处理器。这些串行总线以某种特定于应用程序的模式互连,通常是超立方体或环形排列,因此数据可以通过阵列分布,以供许多 AI 设备并行处理。图 4 是通过阵列路由数据的环形连接方案示例。
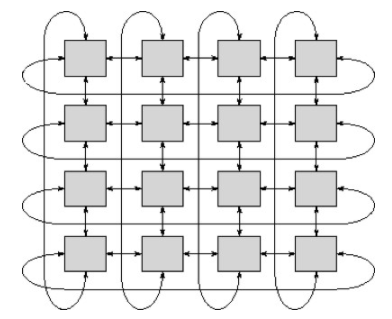
【图4 | 多个AI设备的环形连接]
在 1 Tbps 时,这些串行链路相当快,但链路的数量仍然有限,并且数据必须通过阵列进行几跳才能到达目的地。即使在相当高的总线效率下,填充每个 AI 设备的 HBM 内容也可能需要几秒钟的时间。一种解决方案是增加来自支持硬件的串行输入馈送数量,但在 26 GB/s 的完整 DDR4 接口下,需要四个 DDR4 通道来馈送一个输入管道,因此外部支持硬件很快成为瓶颈。
检查点在深度学习应用程序中修改模型的内容也发生在这些串行总线上。每个 AI 设备都需要将其内容传达给支持硬件,以承诺使用非易失性资源,通常是 NVMe 或 SSD 单元。这种检查点会消耗通信链路上宝贵的带宽,这些时间可以更好地用于数据处理。
停电的代价
串行链路造成的瓶颈突出了电源故障所面临的问题。一旦模型丢失,重新填充大量 AI 设备可能需要很长时间。将应用程序重新加载到执行单元中也需要时间,然后重新启动算法并恢复正在进行的丢失工作也可能需要大量时间。同时,系统无法进行终端用户数据处理。
对于深度学习环境,数据丢失可能是不可接受的,因此必须建立复杂的机制来定期检查种子数据模型的学习修改。
根据系统架构,重新加载的速度将受到非易失性存储接口的限制。即使使用 10 GB/s NVMe 备份,大型 AI 阵列的恢复也可能需要几分钟时间。如果这个瓶颈定义了保存的深度学习模型的粒度,则可以确保永久丢失数据的可能性。为了避免这种数据丢失,通常会部署不间断的备份系统,但是这些架构的电源要求往往相当高,而且 UPS 相对昂贵。
AI中的内存类存储
Nantero NRAM 是一种非易失性存储器技术,可在全 DRAM 速度下运行并具有无限的写入耐久性,因此称为 Memory Class Storage。NRAM 使用静电力来切换碳纳米管阵列以存储 1 和 0。NRAM 与 HBM 接口相结合,为 AI 架构的电源故障敏感性问题提供了很好的解决方案。
NRAM HBM 完全像 DRAM HBM 一样放入 AI 设备。它使用相同的信号和时序,使集成异常简单。与存储类内存相比,存储类内存比 DRAM 慢得多,耐用性非常有限,因此仍需要支持 DRAM 才能实现所需的性能,NRAM 完全取代了 AI 设备中的所有 DRAM,无需额外支持。由于 NRAM 本质上是非易失性的,因此 AI 控制器还可以利用其独特的功能,例如关闭刷新并在相同的时钟频率下获得额外 15% 的性能。
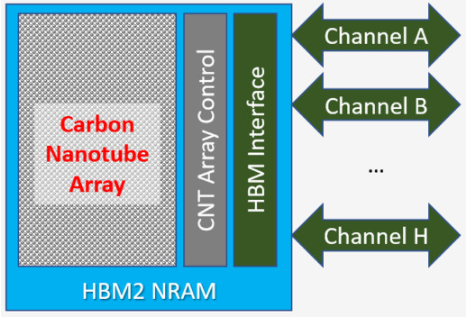
【图5 | HBM NRAM 架构]
停电时,系统会向所有 AI 设备发送一个信号,警告即将停电。每个 AI 设备的响应方式是完成进程中的计算并将结果存储到非易失性 NRAM 中,然后关闭。当电源恢复时,执行单元代码从 NRAM 恢复到每个执行单元所附的本地内存(如 SRAM),恢复临时结果,并在微秒而不是分钟内恢复执行。
由于数据永远不会丢失,并且不需要外部串行链路,也不需要 NVMe 或 SSD 等外部备份机制,因此将 NRAM HBM 并入 AI 架构无需昂贵的电池备份系统。
结论
总之,使用 NRAM HBM 重新构想了人工智能和深度学习应用的计算基础设施。通过始终提供固有的数据持久性,AI 服务器无需承受与重新加载模型和其他数据相关的长时间延迟。修改后的模型数据的检查点是自动的,并且不会消耗处理元件和支持计算系统之间的互连上的带宽。
将 NRAM HBM 整合到 AI 架构中,消除了电池备份系统的成本、复杂性和可靠性问题,并降低了数据中心的功耗,同时提高了性能。备份和恢复过程主要变成 NOP……只需重新启动即可!
审核编辑:郭婷
-
亚马逊云科技推出Amazon DocumentDB Serverless,简化数据库管理并大幅节省成本2025-08-15 713
-
如何通过设计模式来节省内存2023-10-09 1326
-
PCB项目如何节省成本2020-11-04 3068
-
一文知道存储和存储服务器的区别2020-10-23 4576
-
避免云计算浪费并节省成本的五种方法2020-09-01 4835
-
企业使用AI营销战略后有什么益处2019-08-09 1498
-
Flex PCB成本估算器帮您控制尺寸节省成本2019-07-29 3408
-
高效率4类PoE应用低成本解决方案含BOM表和原理图2018-12-29 3939
-
更好地节省成本,让你以最小代价削减云计算成本2018-12-04 514
-
立即节省成本:SDWAN解决方案2018-07-10 641
-
二维码货运标签处理包裹更加高效、更加节省成本2018-05-14 1301
-
请教,如何最节省成本制作语音播放器2018-02-24 4751
-
建立灵活的、节省成本的ECU测试系统设计2009-12-14 4283
-
高速、多路LVDS交叉开关,减少点到点链路并节省成本2008-10-01 1436
全部0条评论

快来发表一下你的评论吧 !
