

嵌入式AI的FPGA面向大众市场的编程复杂性
可编程逻辑
描述
开发人员正在汽车、工业和消费市场的嵌入式应用中研究人工智能。其中许多在功耗和复杂性方面具有严格的阈值。
对于熟悉机器学习、深度学习和其他 AI 推动因素的工程师——或者就此而言,任何熟悉 Gartner 炒作周期的人来说——人工智能正处于与幻灭低谷的碰撞过程中(图 1)。
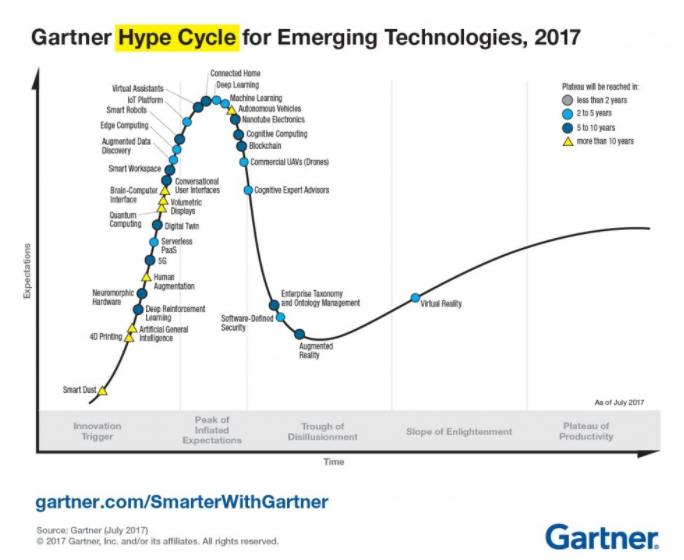
图 1. AI 正走向 Gartner 炒作周期的幻灭低谷。
在一项技术跌入低谷的过程中,有许多市场动态在起作用,包括耸人听闻的营销、令人兴奋的媒体,甚至是忘记考虑商业案例的聪明设计师的过度设计概念。然而,从技术角度来看,加速人工智能失宠的因素是功耗和编程复杂性。
我之前写过有关启用 AI 的嵌入式系统中的处理器功耗的文章,从那时起,广泛的现实世界人工智能用例变得更加清晰。如今,开发人员正在汽车、工业、商业和消费市场的嵌入式应用中研究人工智能,例如关键短语识别、面部和对象跟踪、对象计数和交通标志检测等等。其中许多功能不需要我当时介绍的处理器提供的每秒操作 (OPS) 性能,但在它们可以添加到整个系统设计中的功耗、尺寸和成本方面确实有严格的阈值。 特别关注功率,负责这些任务的计算解决方案通常需要适应 1 W(甚至低于 1 W)的封装。这是一个重大的设计障碍,尤其是考虑到许多现成的 CPU、GPU、
降低 AI 边缘支持的功耗
最初为一个目的而设计的技术也很适合其他目的,这是很常见的,用于深度学习工作负载的 FPGA 就是这种情况。例如, Lattice Semiconductor拥有将胶合逻辑和接口 FPGA 交付到低功耗边缘系统的传统,并意识到这些解决方案可以重新用于灵活的低于 1 W 的 AI 推理应用程序。现在,这可以通过公司的sensAI 技术堆栈实现(图 2)。
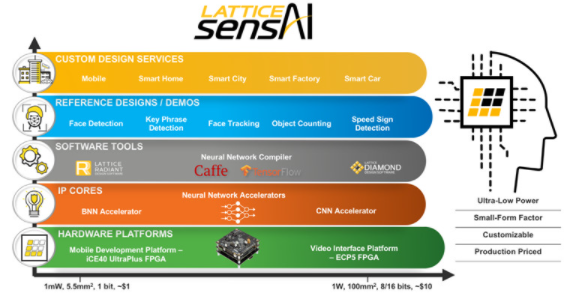
图 2. Lattice Semiconductor sensAI 技术堆栈包括一套围绕公司的 ICE40 UltraPlus 和 ECP5 FPGA 设计的硬件和软件开发工具,可为边缘机器学习应用提供低于 1 W 的功耗。
Lattice sensAI 堆栈基于ICE40 UltraPlus FPGA和ECP5 FPGA,可分别创建二值化神经网络 (BNN) 和卷积神经网络 (CNN) 加速器(图 3A 和 3B)。该堆栈还包括软件开发工具、硬件开发平台、参考设计和第三方设计中心的入口,以帮助加速大批量消费和工业机器学习系统的部署。
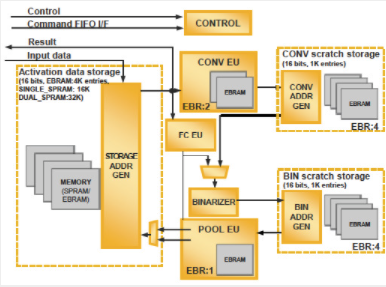
图 3A。作为莱迪思半导体 sensAI 技术堆栈的一部分,ICE40 UltraPlus FPGA 经过优化,可用作二值化神经网络 (BNN) 加速器。
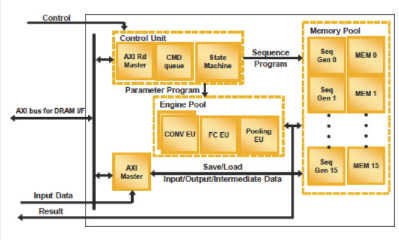
图 3B。作为莱迪思半导体 sensAI 技术堆栈的一部分,ECP5 FPGA 经过优化,可用作更强大的卷积神经网络 (CNN) 加速器。
使用 sensAI 套件开发的基于 ECP5 的 CNN 加速器支持 1 位、8 位和 16 位分辨率,适用于更复杂的神经网络,这些神经网络需要每秒超过 1000 亿次神经操作,且功耗低于 1 W。同时,依赖单比特量化且每秒需要少于 1000 亿次神经操作的要求不高的 BNN 可以利用基于 ICE40 UltraPlus 的 sensAI 设计,功耗在 1 到 10 mW 之间(图 4)。
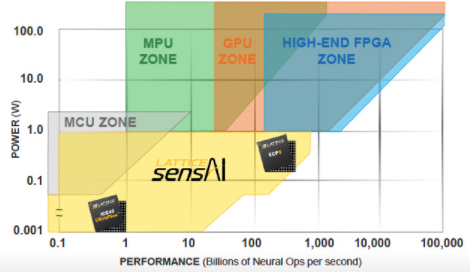
图 4. Lattice Semiconductor sensAI 平台使用 ICE40 UltraPlus 和 ECP5 PFGA 以低于 1 W 的功率水平实现可扩展性能。
降低 FPGA/AI 开发人员的复杂性
sensAI 堆栈由Lattice Diamond和Lattice Radiant软件开发工具套件支持,使 FPGA 设计工程师能够快速开始使用 sensAI 堆栈。对于不熟悉 RTL 或 FPGA 编程的开发人员,sensAI 还包括一个神经网络编译器,该编译器从 Caffe 或 TensorFlow 等深度学习开发框架中获取输出,并使用它来帮助为目标 FPGA 生成比特流。不需要先前的 RTL 经验(图 5A 和 5B)。
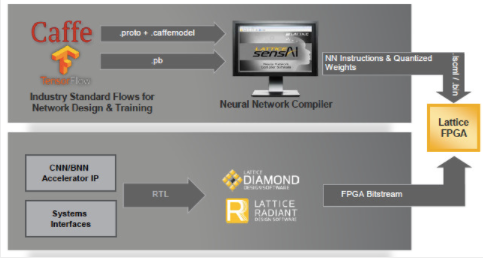
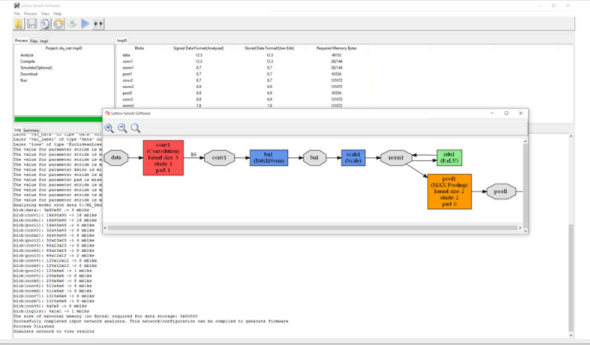
图 5A 和 5B。Lattice Semiconductor 的 sensAI 技术堆栈中的神经网络编译器可帮助开发人员在没有 RTL 经验的情况下在 Lattice FPGA 上实现在 Caffe 或 TensorFlow 中开发的神经网络。
sensAI 堆栈针对人脸检测、关键短语识别、人脸跟踪、对象计数和速度标志检测等应用。然而,莱迪思认识到,在许多情况下,其 FPGA 解决方案将用于还包括更高性能处理器的系统中的预处理。
与竞争的高端架构相比,Xilinx 的UltraScale+系列等 FPGA SoC 器件因其可重配置性和低性能功耗比 (PPW) 在 AI 系统设计中广受欢迎。尽管如此,对于不熟悉 FPGA 设计的开发人员来说,对这些设备进行编程仍然具有挑战性,尤其是当必须将遗留代码库迁移到支持机器学习的 FPGA SoC 设计时。
为了缩短开发周期,Silexa最近在其 SLX 开发工具中集成了功能,可将 FPGA 的 C/C++ 代码重构为高级综合兼容(HLS 兼容)格式,并插入任何需要考虑硬件和软件的 pragma对异构多核 SoC 目标的依赖。在使用 SDSoC 和 Vivado 等工具之前,自动遗留代码分区、代码指导和算法探索功能还有助于加快 UltraScale+ 系列等设备的代码迁移和优化过程(图 6)。
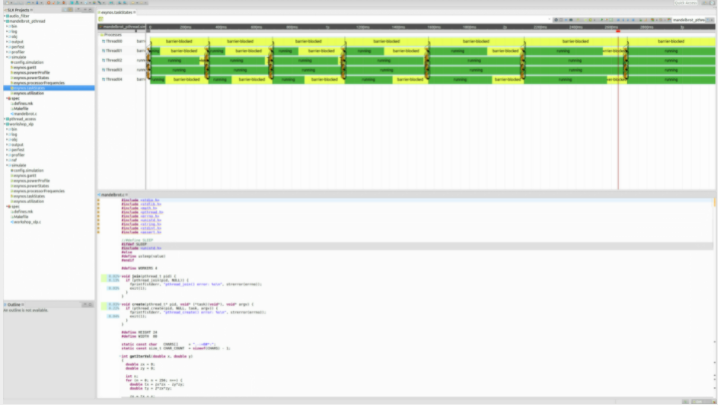
图 6. Silexa 的 SLX 开发工具有助于将 C/C++ 代码重构为高级综合格式,并针对 Xilinx UltraScale+ SoC 等异构多核设备进行了优化。
Silexa 与理光和其他致力于工业和国防市场传感器融合和深度学习解决方案的客户一起开发了新的 SLX 功能。
嵌入式解决方案服务于人工智能行业
应该注意的是,在许多用例中,人工智能技术本质上都映射到物联网架构。
如图 7 所示,大型 AI 学习模型在数据中心(云)中开发,然后将这些模型浓缩成足够小的引擎或算法,以便在边缘设备上运行。边缘设备使用这些精简的学习算法来得出有关其周围环境的结论(称为推理),例如动物是猫、狗还是人,或者露点的升高是否表明风暴即将来临。随着时间的推移,这些推断的结果可以聚合回数据中心,以不断改进人工智能学习模型,从而产生更精确的学习算法等等。因此,向这个良性反馈循环提供 AI 推理的系统越多越好。
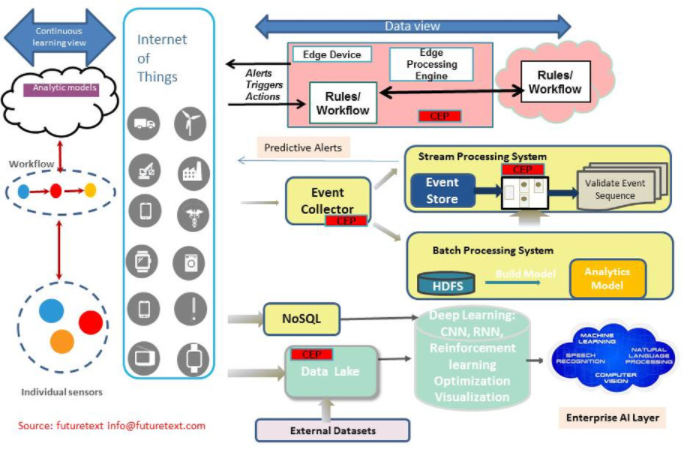
图 7.人工智能和物联网依赖技术合作伙伴生态系统,其中一个层面的挑战可能会破坏整个堆栈。
为什么这很重要?因为它使 AI 的力量和编程成为每个人的问题。
审核编辑:郭婷
-
fpga是嵌入式吗2024-03-14 5813
-
什么是嵌入式系统?2021-12-22 1141
-
嵌入式系统是什么意思2021-10-28 1293
-
嵌入式系统设计2021-10-27 2098
-
嵌入式编程为何如此复杂?2021-02-26 1785
-
嵌入式调试的复杂性分析2021-02-19 1166
-
抑制嵌入式系统设计的复杂性解析2020-12-30 1485
-
如何学习C语言嵌入式系统编程2019-11-11 4421
-
高手谈嵌入式调试的复杂性2017-11-28 3079
-
[转]闲谈嵌入式编程的复杂性2017-08-13 3269
-
闲谈嵌入式编程的复杂性2017-04-05 2905
-
C语言嵌入式系统编程修炼之道2012-08-01 4369
-
C语言嵌入式系统编程技巧2009-12-23 35375
-
C语言嵌入式编程修炼之道2009-10-31 4923
全部0条评论

快来发表一下你的评论吧 !
