

基于直接2D-3D匹配的定位pipeline有效地扩展主动搜索匹配
描述
作者:Zhuo Song , Chuting Wang2, Yuqian Liu3, Shuhan Shen
一、 引言
估计图像相对于 3D 场景模型的 6-DOF相机位姿是近年来许多计算机视觉和机器人任务中的基本问题,如增强现实、机器人导航、自动驾驶等。在 3D 重建、深度学习、云计算、无线通信等领域,单目视觉定位技术取得了长足的进步,并开展了一些实际应用。视觉定位基本上可以分为三类,称为直接 2D-3D 匹配方法、基于图像检索的方法和基于学习的回归方法。在这些方法中,直接2D-3D匹配方法由于其对GPU的依赖少、计算复杂度低等优点,已成为许多实际应用的首选方法。 对于直接 2D-3D 匹配方法,预先构建的 3D 场景模型中的每个 3D 点都与相应的图像描述符相关联。然后,对于查询图像中的每个 2D 特征,在包含所有 3D 点描述符的特征空间中,通过找到其最近邻来搜索其对应的 3D 模型点。为了加速搜索,Active Search [1] 通过在词汇树中应用最近邻搜索来执行 2D 到 3D 匹配。然而,由于视觉词汇引起的量化伪像,如果将图像特征及其对应的 3D 点分配给不同的词,则 2D-3D 匹配将丢失,这将降低内点率,进而导致定位精度。为了恢复这种丢失的匹配,从 2D 到 3D 匹配开始,Active Search [1] 利用匹配点的 3D 位置,并通过同一词汇树中的粗略词汇将其最近的 3D 点作为 3D 到 2D 搜索的候选者。然而,由于空间接近并不一定意味着两个 3D 点的共可见性,因此在查询图像中可以看到的正确候选点的数量是有限的。此外,由于错误的 2D-to-3D 匹配发现了不正确的 3D 候选,以及 3D-to-2D 搜索的高误报匹配率,因此在 Active Search 中应用了严格的比率测试阈值,导致拒绝正确的 3D-to-2D 搜索。2D 轻松匹配。因此,在不断变化的条件下(昼夜、天气变化、季节变化),真实内点率会很低,这将导致定位失败。 在本文中,基于主动搜索 [1] 发现的初始 2D-3D 匹配,我们提出了两种简单有效的机制,称为基于可见性和基于空间的召回步骤,以恢复由量化伪像引起的丢失匹配。基于可见性的召回利用来自初始匹配和 SFM 模型的可见性信息来为查询图像找到最佳的共可见数据库图像。基于空间的召回进一步考虑了特征空间布局,以找到另一个与查询图像具有相似特征分布的数据库图像。然后将这两个数据库图像中的可见模型点作为粗词汇中的 3D-to-2D 匹配的候选点,以召回更多匹配。由于这两种召回机制,使得我们专注于更可能在查询图像中可见的场景点。因此,可以应用宽松的比率测试阈值,用来恢复已被主动搜索中使用严格阈值导致拒绝的正确匹配。本文的主要贡献可归纳如下:
我们提出了一种改进的基于直接2D-3D匹配的定位 pipeline,可以以简单有效的方式有效地扩展主动搜索的初始匹配。
在我们的pipeline中,所提出的基于可见性和基于空间的召回机制,可以充分利用初始匹配和词汇树结构来恢复由量化伪像引起的丢失匹配。
与SOTA的直接 2D-3D 匹配方法相比,所提出的方法在benchmarks上取得了更好的结果,而不会增加太多计算时间,并且适用于手工的特征和基于学习的特征。
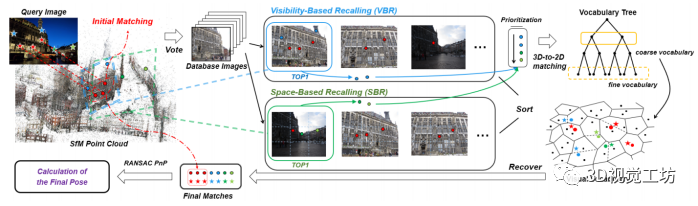
图1. 本文提出方法的 pipeline
二、相关工作
在本节中,我们简要回顾了视觉定位的相关工作,并将它们分为直接 2D-3D 匹配方法、基于图像检索的方法和基于学习的回归方法。
2.1 直接 2D-3D 匹配方法
通过直接比较从查询图像中提取的特征描述符与 SFM 模型 [2] 中的 3D 点来获得 2D-3D 匹配,然后基于 Perspective-n-Point (PnP) 算法 ,对这些 2D-3D 匹配使用 RANSAC 算法估计相机位姿。经典的直接匹配方法,例如基于近似树的搜索 ,在中小型问题上提供了出色的匹配结果。然而,在非常大和密集的描述符集合中,搜索得开销变得非常大。为此,李等人,基于场景点的共可见性,采用一种优先 3D 到 2D 的匹配方案,将 3D 点与查询图像进行比较。尽管比直接基于树的 2D 到 3D 匹配要快得多,但由于 3D 到 2D 搜索的高误报率,它们的方法还没有那么有效。萨特勒等人 [7] 表明 2D 到 3D 匹配为改进基于树的方法提供了相当大的潜力。在[7]的基础上,他们进一步结合了来自词汇树的不同数量视觉词汇中的2Dto-3D和3D-to-2D匹配,仅使用局部特征实现了最先进的结果,同时具有效率和有效性[1 ]。程等人。针对二进制特征表征,[8] 提出了一种Cascaded Parallel filtering(CPF) 的方法,该方法可以以节省内存的方式实现具有竞争力的定位精度。此外,一些方法在定位过程中使用附加信息来提高定位精度。鉴于有关重力方向和相机高度的知识,城市规模定位(CSL)[9] 采用异常值拒绝策略,用来拒绝不能成为最佳相机位姿的一部分对应关系。与 CSL 类似,基于语义匹配一致性 (SMC) 的定位 [10] ,使用基于场景语义的软异常值拒绝方法,该方法在环境变化剧烈的数据集上具有显着改进。
2.2 基于图像检索的方法
早期将视觉定位视为地点识别问题。他们使用最相似的检索图像的位姿,或前 N 个检索图像的融合位姿,来近似查询图像的位姿 [11]-[15]。其中,DenseVLAD [14] 和 NetVLAD [15] 是该类型的代表工作,其中 DenseVLAD 聚合了密集提取的 SIFT [16] 描述符,而 NetVLAD 使用学习特征。它们都可以抵抗昼夜变化,并且在大规模上运行良好。最近,大多数基于图像检索的方法,首先执行图像检索步骤,然后进行精细的位姿估计,因此它们也被称为分层定位 [2,17,18]。由于某些检索数据库图像可能不正确,Shi 等人 [19] 通过比较查询图像和检索图像之间的语义一致性,为每个检索图像赋予采样权重,并执行加权采样 RANSAC-loop,然后执行标准的 PnP 求解器。萨林等人 [20] 提出了一种基于单片 CNN 的分层方法,该方法同时预测局部特征和全局描述符,以实现准确的 6-DOF 定位。
2.3 基于学习的回归方法
随着深度学习的快速发展,基于学习的回归方法在过去几年中受到了广泛的关注。这类方法使用端到端的训练和推理来直接获取相机位姿。通常通过训练多层感知机来过滤异常值 [21, 22] ,或者训练卷积神经网络来实现直接回归得到 6-DOF 相机位姿[23]-[26] 。尽管基于学习的方法发展迅速,但这些方法仍然存在一些明显的局限性。例如,相比准确的位姿估计,位姿回归与通过图像检索得到的位姿更相似。因此,其性能在很大程度上取决于场景中的图像数据集的分布 [27]。除了通过 CNN 直接回归相机位姿外,近年来,基于学习的局部特征和基于学习的特征匹配 [28]-[31] 也被广泛用于提高定位性能和鲁棒性。
三、召回直接匹配
我们方法的流程如图1所示。包括四个主要步骤,包括初始匹配、基于可见性的召回、基于空间的召回和最终姿势计算。在我们的pipeline 中,首先使用标准的直接搜索方法,找到初始的 2D-3D 匹配。然后,使用基于可见性和基于空间的召回,在由这些匹配投票的两个图像数据集中找到 3D 候选。然后,候选者用于 3D 到 2D 搜索,以恢复最初由于量化伪像而丢失的匹配。一旦找到一定数量的匹配,我们将初始匹配和召回匹配结合在一起,并使用 RANSAC PnP 来估计相机位姿。每个步骤的详细信息将在以下小节中描述。
3.1 初始匹配
对于视觉定位问题,首先使用 Structure-from-Motion (SFM) 算法,离线构建出场景的 3D 模型 [32, 33]。在这个 3D 模型中,每个 3D 点都与从相应图像数据集中提取的一组描述符(例如 SIFT [16])相关联。同样在离线阶段,为了建立这些描述符的索引,首先使用(近似)k-means聚类训练一个通用或特定的视觉词汇。然后,通过最近邻搜索,将每个3D点的描述符分配给它们最接近的视觉词。为了减少内存消耗并提高效率,对于由给定 3D 点激活的每个视觉词,计算分配给该词的所有描述符的平均值,我们通过它来表示 3D 点。在在线阶段,对于给定的查询图像,描述符被提取并分配给它们最接近的视觉词。然后,从在每个视觉词中找到的 2D-to-3D 匹配开始,我们按照 [1] 通过利用匹配点附近的 3D 模型点来获得一些 3D-to-2D 匹配,并将这些 2D-to-3D 和3D-to-2D 匹配汇聚在一起。之后,最大的匹配子集,表示为 Mcluster,是通过对所有匹配的共可见进行聚类获得的,然后在 Mcluster上应用 RANSAC PnP 以获得我们 pipeline 中的初始匹配 Minitial。但是,由于 3D-to-2D 搜索的 3D 匹配点数量有限,以及比率测试的严格阈值, Minitial中的匹配可能很少。因此,在不断变化的条件下(昼夜、天气变化、季节变化),真实的内点率可能非常低,这将导致定位失败。在我们的 pipeline 中,我们使用 Minitial作为初始匹配,并进行后续的召回操作,以找到丢失的匹配,同时增加内点率。
3.2 基于可见性的召回
为了从 Minitial中恢复更多匹配,我们使用 Minitial 和 SFM 模型的可见性信息,来召回丢失的 2D-3D 匹配。由于此过程完全使用 3D 点的可见性作为寻找匹配的线索,我们将此步骤称为基于可见性的召回 (VBR)。 令 Pinitial 为 Minitial中所有 3D 点的集合。显然,对于每个 3D 点 p∈Pinitial ,通常在与 p 类似的区域中有许多 3D 模型点,尤其是在纹理丰富的区域。然而,由于查询图像与场景点之间未知的遮挡关系,p 的一些甚至很多附近的模型点不太可能在查询图像中可见。因此,为了在该区域获得合理的 3D 点,我们不再像 Active Search [1] 那样直接寻找 Pinitial 周围的最近邻,而是根据 3D 点与图像数据集的共可见关系进行选择,因为共可见性信息已存储在 SFM 模型中。因此,我们打算寻找可以在 P~initial~ 中看到尽可能多的点的图像数据集,并可以认为该图像数据集与查询图像具有最大的相似性。

图 2. VBR 结果的两个例子。在(a)和(b)中,左边是查询图像,右边是 VBR 选择的图像数据集,红线是初始匹配,绿线是 通过 VBR 得到的召回匹配。 更具体地说,我们首先检查 Pinitial和数据库图像之间的可见性关系。即,使用来自 SFM 模型的可见性信息,对可以观察到 Pinitial 中每个 3D 点的每个数据集图像进行投票。然后,投票数最高的数据集图像,被认为是 Pinitial 的最佳可见图像,表示为IVBR 。之后,我们从 SFM 模型中收集 IVBR 的所有可见模型点,记为 PVBR ,并使用类似于 [6] 的思想对 PVBR 中的所有 3D 点进行优先级排序。其中,在所有数据集图像中可见次数较多的点,具有更高的优先级,表明它们更有可能再次被查询图像可见。然后,我们在词汇树的第 2 层,对来自 PVBR的已排序 3D 点,逐个执行一个优先的 3D-to-2D 匹配方案,如 [1],以获得新的匹配 MVBR 。考虑到计算效率的问题,当 MVBR中的匹配数达到某个阈值 NR(本文中NR= 300)时,我们停止 3D-to-2D 搜索。这里,MVBR 是我们基于可见性的召回过程D得到的匹配结果,如图 2 所示。
3.3 基于空间的召回
在基于可见性的召回期间,会添加一组新匹配,但这些匹配存在一些限制。由于 IVBR 的选择仅取决于初始 3D 点Pinitial的可见性,当集合 Pinitial对应的初始 2D 特征在查询图像中数量较少或分布不佳时,这些点投票的图像数据集 IVBR 可能不完全表征查询图像中包含的场景。因此,可能并未找到查询图像中所有可见的 3D 点。基于这一观察,我们进一步提出了一种基于图像特征点分布特征的召回机制。由于这个过程主要基于特征的空间分布,我们称之为基于空间的召回(SBR)。 为了找到与查询图像具有相似分布特征的图像,我们需要比较数据集图像和查询图像之间特征分布的相似性。请注意,我们已经有了初始匹配 Minitial ,它描述了查询图像和数据集图像之间的局部特征对应关系,因此,我们可以使用这些关系直接比较空间相似度。为此,我们将前 10 个候选图像保留在前一个 VBR 步骤的投票结果中,并评估查询图像与每个候选图像之间的特征空间相似性。直观上,对于一对查询图像和候选图像,如果它们的匹配点在各自图像上具有相似的图像坐标,我们认为它们具有相似的特征分布,这意味着它们的位姿可能比较接近。为了有效地评估特征空间相似度,我们首先将查询图像 I~q~ 和候选图像 I~c~ 划分为图像平面中 m×n 大小相等的 bins(本文中 m 和 n 均设置为 3),如图 3(a) 所示。然后对于每对对应的 bins,并且分别来自 I~q~ 和 I~c~, 和 之间 ( i = 1...m, j = 1...n)的相似性,表示为 ,如果 和 包含至少一个匹配特征或不包含特征,则将其设置为 1,否则设置为 0。当这对 bin 不包含任何特征时设置 为 1 ,是因为我们认为没有特征比位于非对应 bins 上的匹配更好。最后,I~q~ 和 I~c~ 之间的相似度得分,由下式计算出:唯一的特殊情况是,当所有 bins 对都不包含匹配项时, 将设置为 0。因为在这种情况下,所有 的非零值都来自没有特征的空 bins。因此,该候选图像不是我们所期望的。查询图像和三个候选图像的示例,以及它们的相似度得分,如图 3 所示。 依次对所有候选图像进行评分后,相似度得分最高的图像将作为 SBR 找到的最佳数据集图像,记为 ISBR。如果有多个得分高的数据集图像,我们选择与查询图像初始匹配最多的一个作为 ISBR 。然后和 VBR 一样,收集 ISBR 的所有可见 SFM 模型点,进行优先的 3D-to-2D 匹配,得到新的匹配 MSBR,这是我们基于空间召回过程的丢失匹配的查找结果。

(a) 查询图像(左)和选择的数据集图像 *I~SBR~*(右),SBR 具有最高相似度得分( )。

图 3. VBR 结果示例。在 (a) 中,红线是初始匹配,绿线是 SBR 召回的匹配。在 (a)-(c) 中,绿色和红色框分别表示 和 的 bin 区域。
3.4 最终位姿的计算
最后,我们将基于可见性和基于空间的召回结果 MVBR和MSBR ,与初始匹配 Minitial相结合,然后再次执行 RANSAC PnP 以获得最终位姿。请注意,在前面的 VBR 和 SBR 步骤中,我们使用检索图像中的所有 3D 模型点,且有 Pinitial的 3D 模型点。这样做的原因如下,一些初始匹配Minitial 可能会受到量化伪像的严重影响,因此这些匹配可能是错误的。通过在粗略的视觉词汇表中重新匹配 Minitial中的这些点,这些 3D 点可能会因此找到正确的对应关系。
四、实验
4.1 数据集和评估指标
数据集和评估指标我们在两个长期视觉定位 benchmark 数据集 [34] RobotCar Seasons 和 Aachen Day-Night 上评估我们提出的方法。在 RobotCar Seasons 数据集中,所有图像都是用安装在汽车上的摄像头记录的,涵盖了广泛的条件变化,例如:不同的天气,不同的季节,昼夜。在 Aachen DayNight 数据集 [34] 中,数据库图像是在白天使用手持相机拍摄的,查询图像是在白天和夜间使用手机拍摄的。对于这两个数据集,我们遵循 [34] 中使用的评估指标,并报告定位在距离地面实况相机姿势一定距离(米)和方向角(度)内的查询图像的百分比。在基准测试中,使用了三个不同级别的定位精度,即高精度(0.25m,21°)、中精度(0.5m,51°)和粗精度(5m,101°)。
4.2 实施细节
对于每个数据集,我们使用FLANN 库 [36] ,在从所有数据集图像中提取的所有upright RootSIFT [16, 35] 特征上,训练一个特定的 100k 视觉词汇表。在初始匹配步骤中,由于每个数据集使用场景特定的词汇树,我们使用 [1] 中的默认参数,但用于 2D-to-3D/3D-to-2D 比率测试的阈值 r 和阈值 N~t~ 用于提前终止匹配搜索。阈值 N~t~ 主要影响计算效率,在 Active Search [1] 中默认使用 100。在我们的实验中,为了综合评估性能,我们将 N~t~ 分别设置为 100、200 和 500。阈值 r 主要影响匹配选择的严格程度,r 越小越严格,得到的初始匹配越少。在我们的实验中,初始匹配中比率测试的阈值 r 在 Aachen 数据集中分别设置为 0.75 和 0.6,在 RobotCar 数据集中分别设置为 0.85 和 0.6。为 RobotCar 数据集设置一个相对宽松的阈值 r ,是因为这个场景包含更剧烈的表征变化。请注意,在某些情况下,PnP 求解器在初始匹配步骤中,无法获得任何内部对应关系,如果发生这种情况,我们将使用 Mcluster 而不是Minitial 来执行后续的调用步骤。在基于空间的召回步骤中,划分图像时使用了 3×3 的空间 bins,在不同的数据集上取得了合理的结果。在基于可见性和基于空间的召回步骤中,所有数据集的 3D-to-2D 搜索的比率测试阈值都设置为 0.8,这比初始匹配步骤中的阈值要宽松得多,因为模糊 的3D 模型点的数量在场景的一定范围内大大减少。最后,我们 pipeline 中使用的 PnP 算法是 RansacLib [37, 38] 中重新实现的 RANSAC 部分,重投影误差阈值设置为 10 像素。所有实验均在具有 2.40GHz 英特尔 E5-2640 CPU 的服务器上使用单个 CPU 线程运行。
4.3 与 SOTA 的比较
我们与最先进的直接 2D-3D 匹配方法进行了比较,包括 Active Search (AS) V1.1 [1]、Cascaded Parallel filter (CPF) [8]、City-scale Localization (CSL) [9 ] 和语义匹配一致性 (SMC) [10]。请注意,后两种方法需要相机的一些先验知识或场景的语义信息。为了全面起见,我们还与两种广泛使用的基于图像检索的方法进行了比较,包括 NetVLAD [15] 和 DenseVLAD [14]。 表一展示了 RobotCar 和 Aachen 数据集上的定量比较结果。结果表明,我们的方法优于其他方法,除了 RobotCar 数据集中夜间的中等和粗略精度,这其中最好的结果来自 SMC [10]。请注意,SMC 需要有关重力方向的先验知识,并依赖于微调的神经网络进行语义分割。对于初始匹配中不同的 N~t~ 设置,结果表明初始匹配越多,最终结果越好,且在夜间的改善更为明显,尤其是 RobotCar 中的夜间。然而,更多的初始匹配也意味着更长的计算时间,因此在实际应用中,需要根据计算资源在效果和效率之间进行平衡。
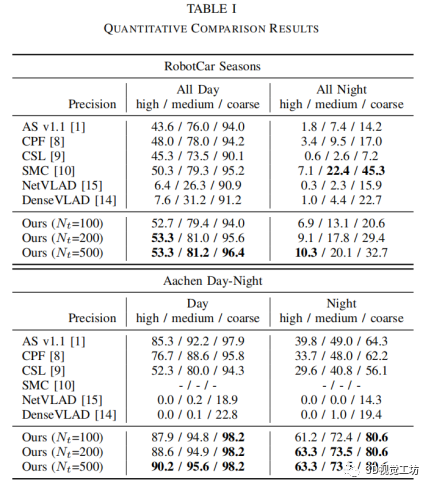
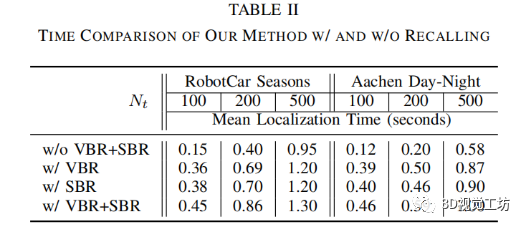
与原来的Active Search[1]相比,我们的方法在夜景上有更显著的改进。这是因为光照的变化导致查询图像和数据集图像的特征描述符之间存在较大差异,而这些差异导致 Active Search 从词汇树中计算出的正确匹配较少。因此,通过我们的方法召回匹配后,准确率将大大提高。并且,与基于图像检索的方法相比,我们的方法在没有 GPU 的情况下也实现了更高的精度(GPU 一直用于基于图像检索的 CNN 图像检索中,并加速图像到图像的完整特征匹配)。 由于计算效率高是直接 2D-3D 匹配方法的主要优势,我们还评估了整个pipeline 中基于可见性和基于空间的召回步骤的时间消耗,如表 ii 所示。表 ii 显示了在 RobotCar 和 Aachen 数据集上,我们的方法定位查询图像(不包括特征提取)所花费的平均时间。可以看出,加入可见性或空位召回比原来的Active Search(w/o VBR+SBR)增加约 200-300ms,同时使用VBR和SBR比单独使用多约 100ms,而不是分别运行它们的时间总和。因为一些 3D 候选点在 VBR 和 SBR 中是重复的,所以对于这些点,我们只执行了一次 3D-to-2D 搜索。
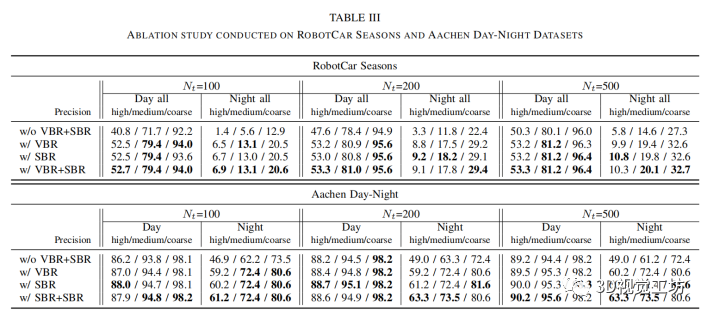
4.4 消融研究
消融研究用于评估两个关键步骤 VBR 和 SBR 的影响,在我们的方法中,我们基于 RobotCar 和 Aachen 数据集进行了消融研究,如表 iii 所示。 没有 VBR 和 SBR 的方法(表 iii 中每个数据集的第一行)时,我们的方法与表 i 中的 Active Search v1.1 基本相同,唯一的区别是我们为每个数据集重新训练了 100k 个单词的特定视觉词汇表, 而 Active Search v1.1 使用在来自 Aachen 模型和不相关数据集的图像上训练的 100k 词的通用词汇表,但它们的性能相似。表 iii 表明,对于这两个数据集,单独使用 VBR 或 SBR 都可以大大提高定位精度,使用 SBR 获得的结果更好,这表明找到与查询图像具有相同特征分布的图像很重要 。此外,同时使用 VBR 和 SBR 步骤可以进一步地提高定位精度。
4.5 手工制作的 V.S. 基于学习的局部特征
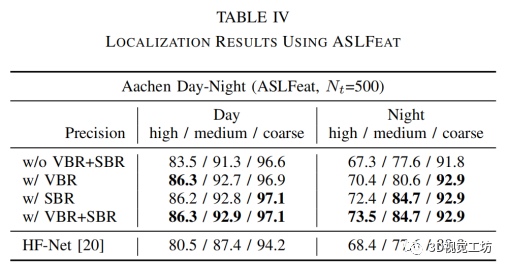
上述实验均基于 SIFT [16] 特征,但众所周知,昼夜条件下的视觉定位( 即基于白天 SFM 模型定位夜间图像 )的成功率很低。为此,近年来提出了几种基于学习的局部特征。为了使用基于学习的特征评估我们所提出的方法,我们使用最先进的基于学习的局部特征 ASLFeat [30] ,并在 Aachen Day-Night 数据集上对其进行评估。在实验中,我们首先从所有数据集图像中提取 ASLFeat 特征,并利用这些特征来训练特定的视觉词汇。此外,SFM 模型还使用 HF-Net [20] 提供的工具箱,根据 ASLFeat 特征重新构建。然后我们的全定位 pipeline(N~t~ = 500)被执行,结果如表IV所示。此外,HF-Net(使用基于学习的全局和局部描述符来定位)的结果显示在表 IV 的底行。将表 IV 中的 ASLFeat 的结果与 SIFT 的相应结果(表 iii 中右下两列)进行比较,我们可以发现在我们的 pipeline 中,可以使用手工制作和基于学习的特征,并且 ASLFeat 的性能要比SIFT 好得多,更适合夜间条件,但白天不如 SIFT 。我们认为原因是,虽然 ASLFeat 对光照变化的鲁棒性比手工制作的特征要强,但它的特征位置精度仍然不如 SIFT。
五、总结
在本文中,我们在 Active Search 的基础上,提出了一种改进的基于直接 2D-3D 匹配的定位方法 。在我们的 pipeline 中,提出了两种简单有效的机制,称为基于可见性和基于空间的召回步骤,以恢复由量化伪像引起的丢失匹配,从而可以在不增加太多计算时间消耗的情况下,大大提高定位的精度和成功率。具有挑战性的长期视觉定位 benchmarks 的实验结果,证明了我们方法的有效性。然而,目前的 pipeline 有两个限制。首先,我们的方法强烈依赖于初始的匹配结果。如果聚类的初始匹配不包含任何正确的 2D-3D 匹配,我们的方法也会失败。其次,在基于空间的召回步骤中,由于图像平面划分的规则,当查询和数据集合图像间有较大的旋转差异时,我们的方法可能无法正常工作。尽管这种情况在现实实际中很少发生。这两个限制,我们将在未来的工作中解决。
审核编辑:郭婷
-
什么是伽玛(γ)匹配2009-10-20 5403
-
基于D2D通信的最大带权匹配比例资源分配算法2017-12-03 1104
-
二维网格的室内匹配定位算法2018-01-29 1260
-
深度学习:搜索和推荐中的深度匹配问题2020-11-05 5534
-
阿里研发全新3D AI算法,2D图片搜出3D模型2020-12-04 4870
-
图像匹配应用及方法2020-12-26 8834
-
深度剖析3D视觉定位技术2021-04-01 5602
-
基于热核的3D对称图形匹配算法及研究2021-05-11 1042
-
基于热核的3D对称图形匹配算法研究2021-06-21 1022
-
如何直接建立2D图像中的像素和3D点云中的点之间的对应关系2022-10-18 11556
-
一种用于视觉定位的2D-3D匹配方法GAM2023-02-16 2989
-
六自由度视觉定位2023-04-20 2113
-
双目立体匹配的四个步骤2023-06-28 2450
-
2D图像和LiDAR的3D点云之间的配准方法2023-12-22 4752
-
英伦科技的15.6寸2D-3D可切换光场裸眼3D显示屏有哪些特点?2024-05-28 1326
全部0条评论

快来发表一下你的评论吧 !
