

通过Tensai架构简化AI边缘计算
描述
随着物联网开发人员解决在边缘部署设备所面临的连接性、可管理性和安全性挑战,现在的需求转向使这些系统更智能。工程师现在的任务是将人工智能 (AI) 集成到网络远端的嵌入式系统中,这必须最大限度地减少功耗、通信延迟和成本,同时还要变得更加智能。
不幸的是,许多可用于嵌入式 AI 的处理解决方案太耗电,太难编程,或者对于边缘应用来说太昂贵。
为了在更高的性能、功耗、成本和易用性之间取得平衡,无晶圆厂 SoC 供应商 Eta Compute 的 Tensai 芯片在 55 nm ULP 中结合了异步 Arm Cortex-M3 CPU、NXP CoolFlux DSP16 内核和低功耗模拟模块过程(图 1)。Tensai 解决方案还包含一个神经网络软件堆栈,用于实现在 DSP 的双 16x16 MAC 上本地执行的卷积神经网络 (CNN) 和尖峰神经网络 (SNN)。
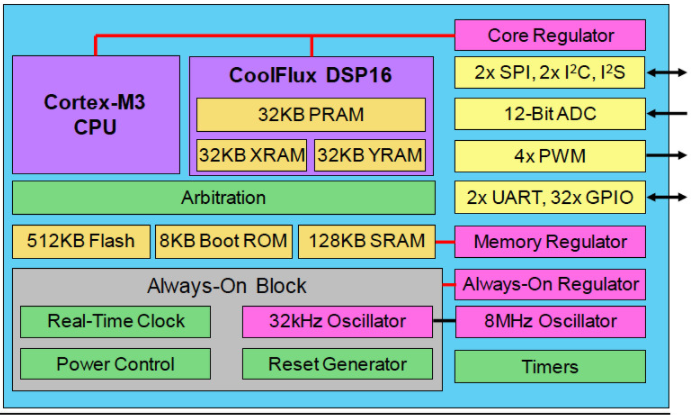
图 1. Tensai 架构提供超低功耗和确定性以及 AI 边缘计算所需的性能。
《 2mW 的边缘 AI
Tensai 架构采用多个稳压器来支持以小于 2 mW 的超低功耗、始终在线的处理,适用于纽扣电池或太阳能电池供电的 AI 系统。其中包括一个用于芯片实时时钟和复位电路的专用稳压器,另一个用于存储块,第三个用于 MCU 和 DSP 内核。
该设备仅消耗 600 纳安电流,只需开启常开模块即可。在内存块通电的睡眠模式下,这个数字增加到 10 微安。
然而,Tensai 的超低功耗配置并没有限制 SoC 在 AI 工作负载中的应用。CoolFlux DSP16 内核的运行频率高达 100 MHz,每秒可提供 2 亿个 16 位 MAC 的性能。Tensai 对来自 CIFAR-10 数据集的 32x32 像素图像进行推理,每秒可以处理 5 张图像,每张图像消耗 0.4 毫焦耳。
对于非 DSP 工程师,Tensai 的神经网络软件堆栈允许开发人员通过 Cortex-M3 上的解释器传递量化的 TensorFlow Lite 模型,从而抽象出硬件编程的复杂性。然后 Cortex-M3 生成代码,这些代码被翻译成可以在 DSP 上执行的功能。
四通道 DMA 引擎在 I/O 和 32 KB PRAM 以及为 DSP 保留的 64 KB 联合 XRAM 和 YRAM 之间传输数据。除了 16 位分辨率外,CoolFlux 内核还可以处理两个 8x8 MAC。
在人工智能的边缘
超低功耗和易于编程将有助于将人工智能带入普通嵌入式和物联网工程师,因为他们将智能添加到边缘。嵌入式和物联网开发人员熟悉的 Tensai 芯片的其他高级特性包括:
512 KB 闪存(足够约 450,000 个神经网络权重)
Cortex-M3 和 DSP 共享 128 KB SRAM
4 个 ADC 通道(12 位 ADC 在 200,000 个样本/秒时消耗 uW)
4x PWM 通道
I2S、I2C、SPI、UART、GPIO
审核编辑:郭婷
-
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联2025-08-09 1794
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1521
-
什么是AI边缘计算,AI边缘计算的特点和优势介绍2024-02-01 2211
-
算力强劲的AI边缘计算盒子# 边缘计算成都华江信息 2023-11-24
-
AI边缘计算是什么意思?边缘ai是什么?AI边缘计算应用2023-08-24 4133
-
AI边缘计算盒子是如何推动边缘AI应用落地的2023-05-26 2568
-
Eta Compute的Tensai Flow将机器学习置于物联网的边缘2022-11-24 1871
-
嵌入式边缘AI应用开发简化指南2022-10-28 684
-
分享一种基于RK3399+RK1808架构的AI边缘计算商显主板2022-02-16 3055
-
AI边缘计算网关介绍2021-07-26 2914
-
【米尔百度大脑EdgeBoard边缘AI计算盒试用连载】I. 开箱报告(ZMJ)2021-03-14 3999
-
【HarmonyOS HiSpark AI Camera】通过kubeedge边缘计算框架驱动边缘侧基于HarmonyOS上的图像采集和分析2020-09-25 2167
-
EdgeBoard FZ5 边缘AI计算盒及计算卡2020-08-31 2700
全部0条评论

快来发表一下你的评论吧 !
