

使用稀疏计算和Facebook Glow进行神经网络优化
人工智能
描述
2017 年 8 月出版了《神经网络最完整的图表,解释》,并确定了 27 种不同类型的神经网络。从那时起,随着工程师和数据科学家为他们的用例寻找人工智能 (AI) 的优化实现,神经网络类型的数量不断增加。
处理器架构师一直在争先恐后地提供能够执行这些工作负载的新型计算平台,但也正在努力在软件方面提高神经网络的效率。一种这样的技术是修剪,或从神经网络中删除重复的神经元和冗余,使其更小更快(图 1)。
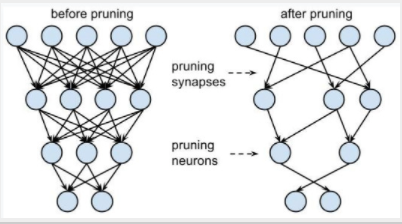
图 1. 修剪可以产生更快、更小的神经网络,但具有相同的精度。
一般来说,修剪是嵌入式系统深度学习的重要推动力,因为它降低了达到相同精度水平所需的计算量。剪枝技术还可以进一步减少神经网络的特定低效率,例如稀疏性。
通过神经网络进行稀疏
在神经网络图中,稀疏性是指包含零值或与相邻神经元没有连接的神经元(图 2)。这是存在于深度神经网络的输入和输出层之间的隐藏矩阵的固有特征,因为当数据通过图时,给定的输入通常会激活越来越少的神经元。神经网络矩阵中的连接越少,稀疏度越高。
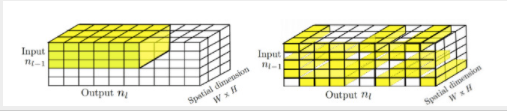
图 2. 左图将具有活跃连接的神经元密集化为黄色立方体,而右图描绘了分布在整个神经网络中的稀疏随机连接。
Tensilica 高级总监兼营销和业务开发主管 Lazaar Louis 说:“当您通过这些层并将 1 与 0 相乘时,您会得到 0,因此神经元激活的稀疏性会随着您通过层而增加。” Cadence Design Systems 的产品。“平均而言,当前的神经网络在从输入到输出的激活中表现出 50% 的稀疏性。”
与使用处理器和内存资源来计算稀疏神经网络的零值不同,修剪网络以诱导稀疏性可以转化为计算优势。稀疏度的修剪可以通过将接近零的值强制为零来实现,这与模型再训练一起可以将稀疏度提高到 70%。
一旦神经网络被修剪以增加稀疏性,Cadence 的 Tensilica DNA 100 处理器 IP 等计算技术就可以通过仅对非零值执行乘法累加 (MAC) 运算来利用这一优势(图 3)。这要归功于集成的稀疏计算引擎,其中包括一个直接内存访问 (DMA) 子系统,该子系统在将可执行文件传递给处理单元之前读取值。
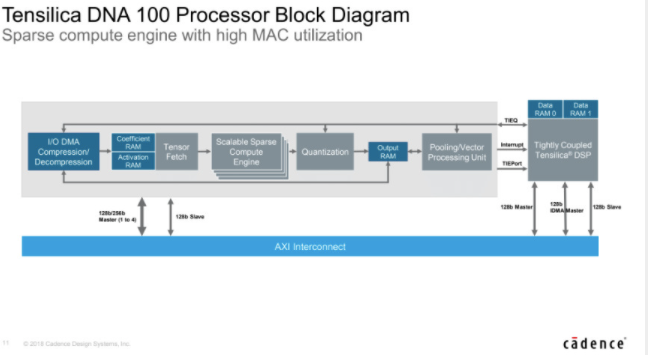
图 3. Cadence Design Systems DNA 100 处理器 IP 包含一个稀疏计算引擎,该引擎仅执行非零值的乘加 (MAC) 操作,从而提高吞吐量。
总体而言,这为 DNA 100 IP 提供了更高的 MAC 利用率,与具有类似阵列大小的替代解决方案相比,性能提高了 4.7 倍。
发光编译
与任何嵌入式处理器一样,DNA 100 利用编译器来帮助解释神经网络图的稀疏性。Tensilica 神经网络编译器从 Caffe、TensorFlow、TensorFlow Lite 和 Android 神经网络 (ANN) 应用程序等深度学习开发框架获取浮点输出,并将它们量化为整数和针对 Cadence IP 优化的机器代码。
编译器还有助于将接近零的权重推至零,并在可能的情况下将多个神经网络层融合到单独的操作中。这些功能对于提高 DNA 100 等设备上的神经网络吞吐量至关重要,同时还将精度保持在原始浮点模型的 1% 以内。
然而,尽管 Tensilica 神经网络编译器具有优势,工程师们已经受到越来越多的神经网络类型、深度学习开发框架和 AI 处理器架构的挑战。随着这一趋势的继续,开发人员将寻求编译器,使他们能够在最多样化的处理器目标上使用最广泛的神经网络类型和工具。另一方面,像 Cadence 这样的供应商将需要能够让他们支持技术进一步发展的解决方案。
意识到市场需求,Facebook 开发了Glow,这是一种基于 LLVM 编译器基础架构的异构硬件架构的降图机器学习编译器。Glow 的目标是接受来自 PyTorch 等框架的计算图,并使用与数学相关的优化为多个硬件目标生成高度优化的代码。它通过将神经网络数据流图降低为中间表示,然后应用两阶段过程来实现(图 4)。

图 4. Facebook 的 Glow 编译器是一种与硬件无关的编译器,它使用两阶段过程来优化嵌入式计算加速器的神经网络。
Glow 中间表示的第一阶段允许编译器执行特定领域的改进,并根据神经网络数据流图的内容优化高级构造。在这个阶段,编译器是独立于目标的。
在 Glow 表示的第二阶段,编译器在生成特定于硬件的代码之前优化指令调度和内存分配。由于其增量降低阶段以及它支持大量输入运算符的事实,Glow 编译器能够利用专门的硬件功能,而无需在每个受支持的硬件目标上实现所有运算符。这不仅减少了所需的内存空间量,而且还使其可扩展用于仅关注少数线性代数基元的新计算架构。
Esperanto Technologies、英特尔、Marvell、高通和 Cadence 已经承诺在未来的硅解决方案中使用 Glow
“Facebook Glow 让我们能够快速优化尚未到来的技术,”Louis 说。“假设引入了一个新网络。要么有人会做出贡献,要么我们会做。他们希望建立一个开源社区,这样人们就可以进来并贡献和加速通用的事情。
“他们还在 Glow 中引入了插入各种加速器的功能,因此我们可以使其适合我们的架构,”Louis 继续说道。我们将 Glow 视为我们编译器中的底层引擎 [向前发展]。”
嵌入式神经网络:少即是多
在过去的几年里,围绕人工智能的炒作、研究和开发呈爆炸式增长,但正如嵌入式技术经常出现的情况一样,事实证明,少即是多。
修剪神经网络正迅速成为神经网络开发人员的一种常见做法,因为他们试图在不牺牲准确性的情况下提高性能。与此同时,Facebook Glow 正在解决处理器碎片化问题,以免阻碍人工智能的采用。
非常好地使用一个正确的工具通常会导致成功。对于神经网络,使用 Glow 编译器和稀疏计算技术可以完成工作。
审核编辑:郭婷
-
Glow神经网络编译器首次应用于MCU,面向边缘端机器学习2020-08-05 2112
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 2575
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 3985
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3322
-
如何构建神经网络?2021-07-12 2021
-
嵌入式中的人工神经网络的相关资料分享2021-11-09 1501
-
卷积神经网络一维卷积的处理过程2021-12-23 2091
-
神经网络移植到STM32的方法2022-01-11 3274
-
卷积神经网络模型发展及应用2022-08-02 13388
-
优化神经网络训练方法有哪些?2022-09-06 1757
-
基于反馈神经网络的稀疏信号恢复的优化算法2017-11-28 889
-
人工神经网络控制2021-05-27 1640
-
基于神经网络的优化计算实验2021-05-31 1417
-
如何训练和优化神经网络2024-07-01 1868
-
如何使用神经网络进行建模和预测2024-07-03 2019
全部0条评论

快来发表一下你的评论吧 !
