

ME结构在FPGA加速芯片ACAP有何作用
可编程逻辑
描述
引言
随着人工智能和5G的兴起,数据处理对芯片的算力和带宽要求更高。为了布局未来,助力人工智能和5G,赛灵思也推出了自己的FPGA加速芯片-ACAP。ACAP是一款基于7nm工艺,集成了通用处理器(PS),FPGA(PL),math engine以及network-on-chip的革命性芯片。特别是新增的ME结构,是一个类似于GPU的多核并发计算单元,可以大大提高数据处理能力。同时ME支持软件语言C,C++,这有利于扩大FPGA的使用用户,同时方便了设计开发。
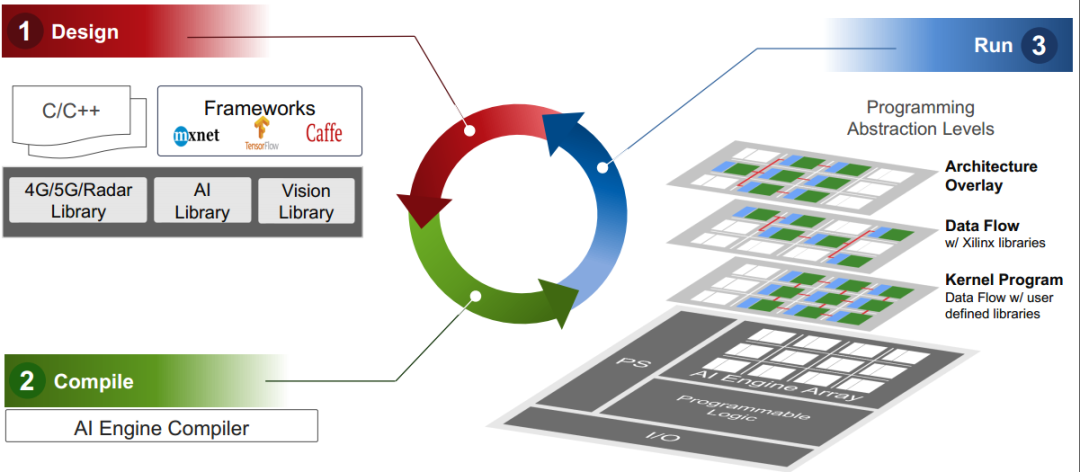
ME结构简介
ME结构由很多ME核组成的二维阵列结构,核之间可以实现数据通信。ME阵列通过NoC可以和PL以及PS端进行通信,NoC是一种互联总线,其提供了ME阵列到PL侧的高带宽通路。ME核包含了BRAM,DSP以及控制逻辑。ME具有以下特点:
1) 有一个RISC处理器,能够支持32bit标量数据运算,包括sin/cos,开方,乘法等操作;
2) 向量乘法计算单元。这是一个由DSP组成的阵列,能够支持32个16bitx8bit,64个16x8bit,128个8x8bit计算。还支持8个单精度乘法计算;
3) 指令控制结构支持load和save,向量乘法等操作,这些操作统一用一个指令字段描述;
4) 含有多路AXI stream,可以实现高速数据通信;
5) 含有一个128bit宽1K深的程序存储器,支持指令压缩,可通过AXI-MM进行配置;
6) 含有多个数据存储器,分成多个bank,共有32KB容量;
7) 含有配置接口,用于ME核的配置和调试;
8) 含有debug/trace/profile功能,用于程序追踪和调试;
ME核的工作频率达到1GHz,电压0.7V,具有较低功耗。ME支持多种形式的数据传送,包括AXI-MM,AXI-stream,以及ME之间共享的bank进行数据直接交互。
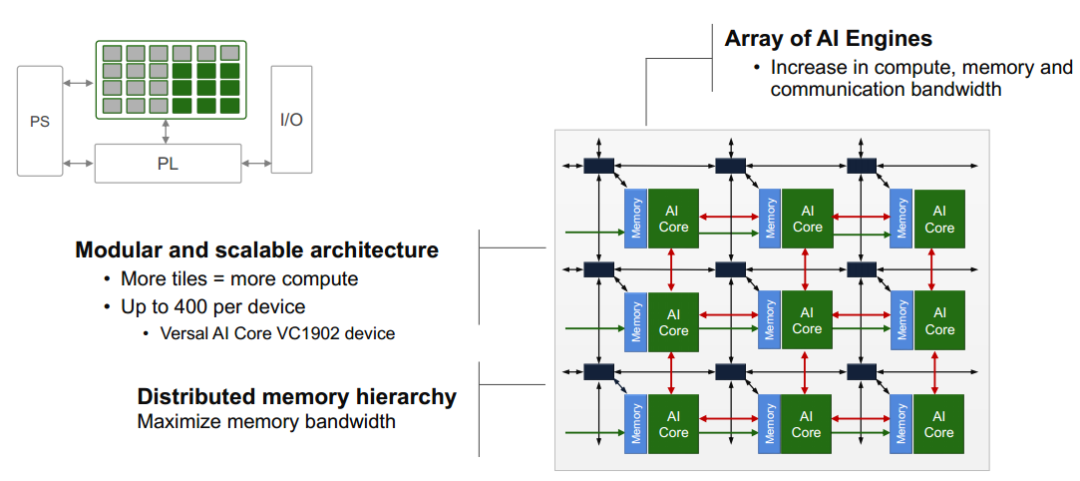
为了保证性能的可预测性,ME之间数据通信不存在缓存一致性。但是ME和PS之间通信是需要缓存一致性功能的,ME和PS端共享DDR中一段内存。当PS处理完数据发送给ME时,是要保证处理的数据都已经存储到DDR中了。而ME处理完数据写到DDR中后,也要让PS知道数据已经写完。ME可以使用虚拟地址去访问PS的存储或者DDR,ME地址会经过PS端的MMU进行解析。
为了保证某些过程的安全性(比如对TrustZone的保护,或者防止ME阵列的重要信息被读取),ME提供了一些保护措施。主要包括对ME访问的保护,AXI-MM传输的安全性保护,AXI-stream数据访问的保护等。
ME阵列可以在功能上被分割成多个子阵列使用,这可以用于一些需要ME阵列完成多种功能的任务。其中ME核,AXI-stream,数据存储访问等模块都可以被分割。只有AXI-MM不能被分割。NoC中可以支持对控制信息的修改,从而可以给不同子阵列发送不同的控制信息。每个ME核含有256Kb的数据存储器和128Kb的程序存储器,对于一个300个ME核的芯片就含有77Mb数据存储和38Mb程序存储,这么大的空间,保证数据准确性是很关键的。因此不论是数据存储器还是程序存储器都提供了ECC校验,以防止软件错误产生的数据错误问题。程序存储器每144bit包含128bit有效数据和8bitECC校验位。8bit校验位可以在每64bit数据中纠正1bit数据和检测出2bit数据错误。存储数据出错会生成错误事件,反馈给debug或者profile模块报告这些错误。
ME阵列被分配了4个1GB的地址映射区域,目前芯片只有一个ME阵列,所以只使用了1GB地址映射空间。ME的地址含有整体阵列的offset,阵列的行列编号,以及ME核中存储地址。这些信息可以确定往哪个ME中的存储位置读写数据。
ME中有4个时钟:ME核时钟,高频,可到1GHz,用于ME中的数据传输和运算。NoC时钟,数据时钟,用于从PL到ME的数据输送。PL侧时钟以及NPI时钟,NPI时钟用于调试追踪等。
数据传输结构
为了保证不同设备之间的数据交换,我们需要满足两个条件:一个是数据实际的流通,这个包含数据传输通路和数据存储;当然也不必包含有存储,流水线处理的数据只有数据流通;另外一个是发送者和收发者之间的同步。接受者接收数据只有在发送者发出数据之后,同时发送者发送数据必须等接受者准备好接收数据。因此一些同步信号是必须的。
ME阵列中能够实现数据交互的设备有:
1) 本地存储bank。每个ME包含8个bank,这些bank可以用于和周围4个ME进行数据通信。ME通过load和save指令来读写本地存储器。如果ME的写和另外一个ME的读同时发生,可以通过ping/pong操作同步。
2) Stream-network可用于所有ME之间数据交互。而且stream本身是具有同步信号的,所以无需增加额外同步信号。
3) AXI-MM接口能够用于ME和PL端甚至是外部存储器进行通信。
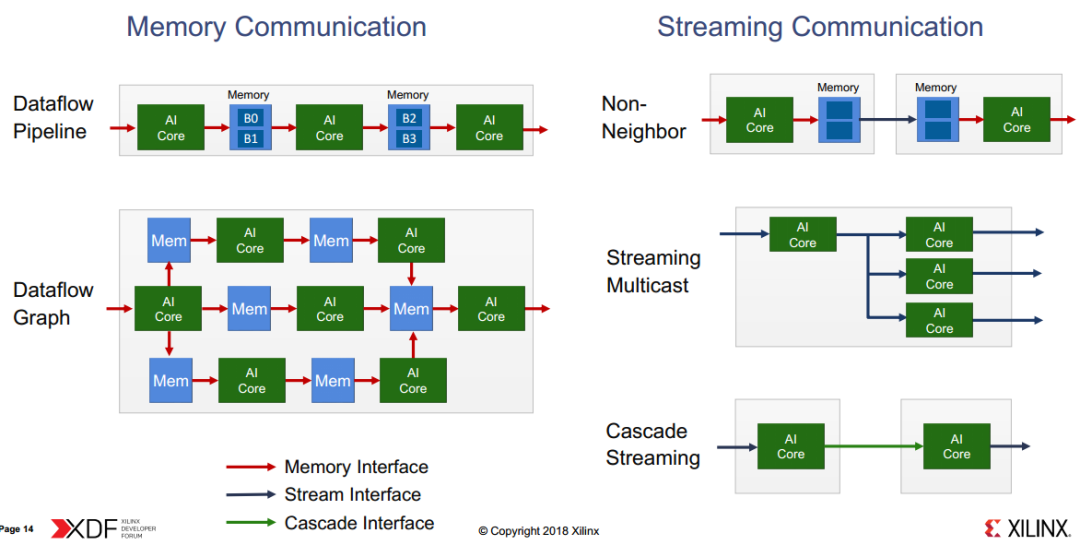
保证数据同步的装置有:
1) ME本地原子锁。这个锁可以保证生产者和消费者的数据访问冲突解决。如果锁被置为1,表示可以被读,如果为0表示可以写。
2) Shim-DMA锁。用于同步不同DMA通道,或者DMA通道和AXI-MM通道;
3) 信号量机制。对于ME和PS端的数据通信,还可以通过软件层次的信号量机制来进行同步,因为PS端可以通过AXI-MM接口实现和ME之间的数据同步;
4) Stream网络自身附带的同步特性,用于不同ME之间交换数据。
PL和ME由于处于不同时钟区域,ME是高频时钟,而PL侧时钟频率较低。为了实现数据跨时钟域传输,芯片提供了shim接口,shim中含有异步FIFO。FPGA可以以64bit或者32bit将数据写入FIFO,而ME将FIFO中数据读出进行运算。ME获得数据有两种方式,一种是通过DMA将数据读出写入到ping/pong buffer,这样可以实现ME核中两个函数的计算任务。如果ME中不需要ping/pong操作,可以不同各国DMA将数据存储到buffer。可以从stream直接获得数据进行计算。
接下来我们看看ME内部数据如何通信:
1) ME内部不同操作之间可以使用shared memory来进行数据交互,但是每次只允许一个操作来访问shared memory,即读写无法同时进行;
2) 两个相邻ME可以通过shared memory来进行数据交互,通过ping/pong buffer可以实现一个写一个读;
3) 对于不相邻的ME,也可以使用ping/pong buffer。但是这个时候ME无法直接去访问另外一个ME的存储,但是每个ME都可以建立自己的ping/pong buffer,这两组buffer可以通过DMA进行数据交互;
4) 不同的ME之间还可以通过AXI-stream接口进行数据交互;
5) 有时候一个大型计算要在几个ME之间完成,这就需要不同ME之间进行高速数据通信,相邻的ME之间还有级联总线,可以实现两个ME之间的累加运算,这个总线位宽达到384bit;
6) ME还可以直接从外部存储器中获得数据,它将数据请求包发送给ME-shim,这个请求包含有包头和数据请求信息,包头中有原和目的地址,数据请求中含有数据长度信息。
审核编辑:刘清
-
基于7nm工艺的FPGA加速芯片-ACAP2020-11-05 4976
-
【AD新闻】赛灵思新CEO访华绘蓝图,7nm ACAP平台要让CPU/GPU难企及2018-03-23 5021
-
ACAP的主要架构创新解析2020-11-27 2920
-
与传统模式的芯片设计进行对比FPGA芯片有哪些优势2021-09-14 1668
-
芯片组在主板中有何作用2021-09-22 5317
-
Hi3559V200芯片有何作用2021-10-19 1490
-
FPGA与DSP有何关系2021-10-21 2187
-
Bus Bridge在AHB和APB之间有何作用2021-11-02 2142
-
STM32芯片的BOOT管脚有何作用2021-11-03 3662
-
485芯片的接收端口与发送端口有何作用2021-11-18 2192
-
TCP/IP模型的结构是怎样的?TCP/IP协议有何作用2021-12-23 1851
-
在linux下的RTSP推流软件有何作用2022-02-11 1927
-
TPL是什么?有何作用2022-03-02 3997
-
FPGA发明以来最伟大的技术ACAP解析2018-10-05 11134
-
三张图解析FPGA/ACAP在AI推理中的优势2020-12-04 2094
全部0条评论

快来发表一下你的评论吧 !
