

基于pipeline的文本纠错系统框架分析
描述
1 简介
传统的文本纠错系统基本都是基于pipeline的,将分词,文本检测,文本纠正等模块等剥离开来,同时经常会在其中插入相应的规则模块,一环扣一环,如果生产流水线一样,依次执行,构成一个完整的系统。这种系统设计虽然直观,容易被人所理解,也方便人工介入去优化和排查问题。但是如果前面环节出现了错误,后面的环节很难进行弥补。任何一个环节出现的错误,都会影响系统整体的效果。各个子模块的训练和优化都是相互隔离的,子模块的优化并不一定会导致系统整体性能的提升。
2 TM+LMM
这是比较早期的一个中文文本纠错系统,该系统结合了规则模版和统计的方法,很大程度的解决了同期纠错系统误报率过高的问题。TM+LMM中的TM指的是规则模版(template module),LMM指的统计模型(translate module)。
该中文纠错系统需要提前准备的事项有以下几种。
a) 混淆集,为可能的错别字提供候选字符。该系统为5401个中文字符准备了相对应的混淆集,每个中文汉字相应的混淆集包含1到20个不等的字符(也就是有1到20个汉字you有可能被误写成这个汉字),包括读音相似和字形相似的字符。同时,混淆集中的元素会根据谷歌搜索的结果进行排序,方便后续的纠正模块按顺序进行纠正。
b) n-gram语言模型,一种可以用来检测字符是否错误的方式。n-gram语言模型通过最大似然估计方法在训练数据中训练得到(在训练语料中不同字符组合同时出现的频率越大,相应的n-gram模型得分就越大。这些ngram得分可以用来计算句子合理性的得分,如果一个句子所有ngram得分都很大,那么就说明这个句子是合理的,反之,如果一个句子所有的n-game得分都很小,那么说明这个句子很大概率是有问题的,也就是很大概率有错别字出现。句子的得分跟句子中所有n-game的得分呈正相关,跟句子的长度呈负相关。),从而可以计算不同字符在当前位置的概率得分,更合适的字符可以得到更高的概率值。该系统用到了1-gram跟2-gram的信息。
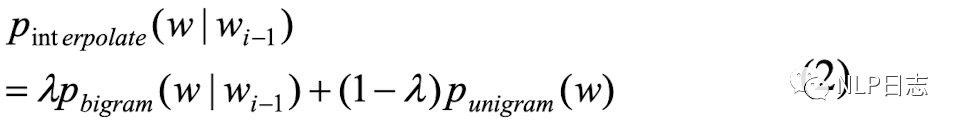
图1:2gram得分计算
c) 统计翻译模型,可以理解为n-gram语言模型的加强版本。可以计算出将字符A替换成字符B的一个条件概率。
TM+LMM的流程如图所示,
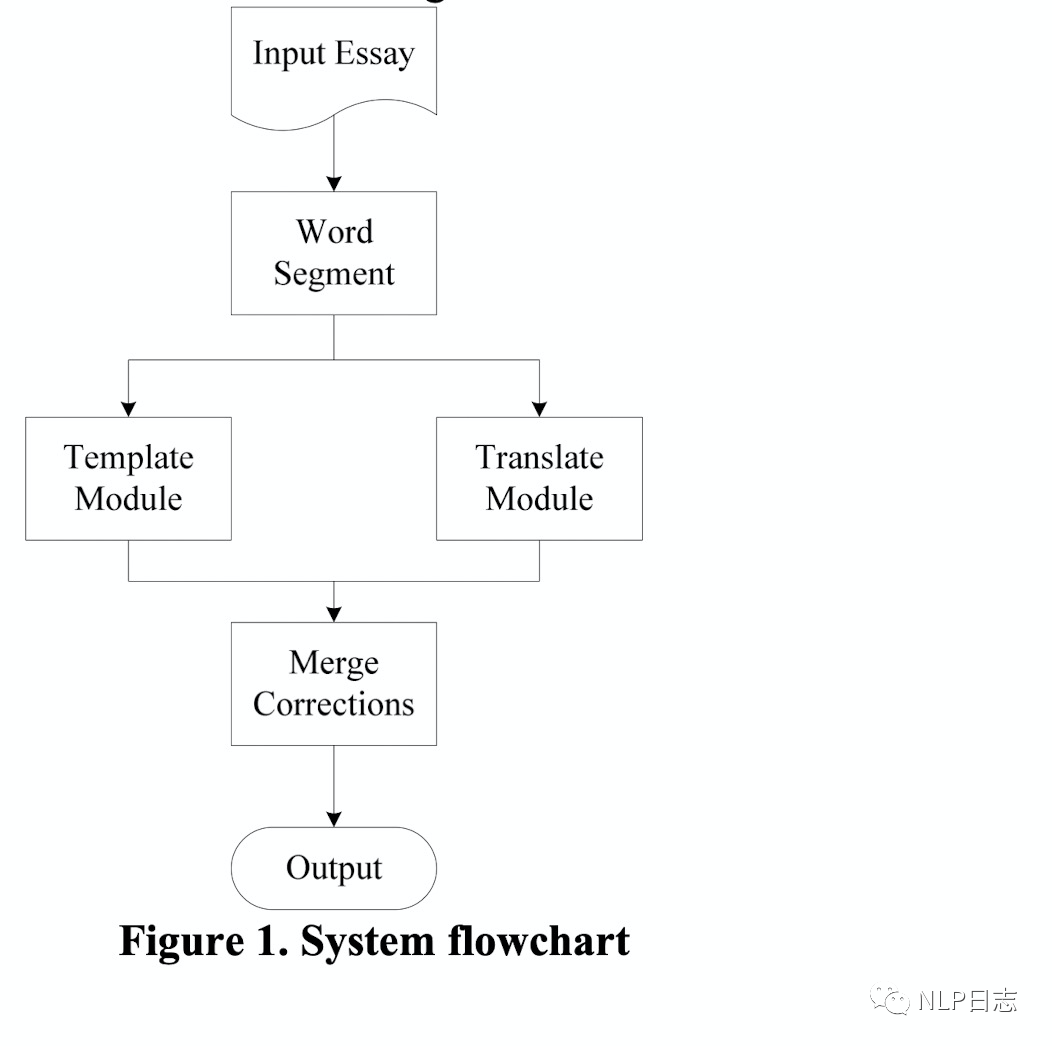
图2: TM+LMM框架
a) 分词模块,将句子切分为以词为基本单位的结构。其中那些单个字符的结果会被额外关注,系统会将其认为有是有更大概率出现错误的地方。这也比较好理解,因为句子中错误的位置大概率在语法或者语义上不大连贯,所以分词模块大概率会把句子中错误的位置切分为单个的字。
b) 规则模块,寻找将第一步中可能错误位置上的字符对应的混淆集,尝试将用混淆集中的元素替代当前位置的字符,如果替换结果命中系统中设置的规则模版,则进行相应的替换,反之则不变。这其实就是个规则模版,如果命中系统设置的规则,就进行替换。
c) 翻译模块,寻找将第一步中可能错误位置的字符对应的混淆集,同样尝试用混淆集中的元素替代当前位置,通过2-gram语言模型跟翻译模型计算相应的得分,将两个模型的得分相乘,计算相应的困惑度分数(如下图所示,p(S)是句子经过平滑后得到的2-gram语言模型跟翻译模型乘积得分,N是句子长度),选择困惑度得分最小的字符作为最终的替换结果。这里可以理解为正确的字符对应的语言模型跟翻译模型得分乘积更大,困惑度得分更小。
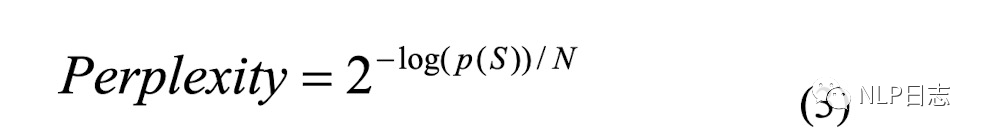
图3:困惑度计算公式
d) 输出模块,汇总规则模块跟翻译模块的纠错结果, 可以求两者的交集或者并集作为最终的结果输出。
3 LMPS
LMPS是该中文纠错系统对应的文章标题中最后几个单词的首字母(作者没给自己的文本纠错系统起名,为了编辑方便,就用LMPS指代这个系统)。构建该文本纠错系统需要准备的事项如下。
a) 混淆集,跟TM+LMM一样构建基于发音跟字形的常用字符的混淆集。
b) 5-gram语言模型,利用语料训练一个5-gram语言模型,用于计算不同字符对应的语言得分。
c) 一个基于词的字典,存储基本的中文词语,用于判断不同字符的组合是否合法?如果某字符组合位于这个字典,那么就认为这个字符组合是合法的,是没有错误的。如果某字符组合在该字典中没有找到,那么这个字符组合大概率是存在错误的。这个字典在检测阶段的b)环节跟纠正阶段的b)环节都会用到。
该文本纠错系统流程分为检测阶段跟纠正阶段。
检测阶段
a) 通过前馈5-gram语言模型计算句子中每个字符的得分,得分低于阈值的字符跟对应位置会被检测出来并传递到下一个阶段。
b) 判断上一步检测出来的字符是否可以用来构建成一个合法的词,如果不能,则认为这个字符可能是一个错误,然后将可能错误的字符跟位置传递到纠正模块进行相应的纠正。具体执行方式就是检查固定窗口位置内的其他字符跟这个字符的组合是否存在于前面提及的字典中。
纠正阶段
a) 从混淆集中生成错误位置的可能候选字符。
b) 判断每一个候选字符是否可以跟附近字符构成一个合法的词语,如果可以,那么这个候选字符会被留下来。通过这种方式可以过滤到大量不相关候选字符,只保留少量的更有可能作为最终结果的候选字符。
c) 利用5-gram语言模型计算上一步保留下来的候选字符的得分,如果得分超过阈值,那么就用候选字符替换掉原来的字符。
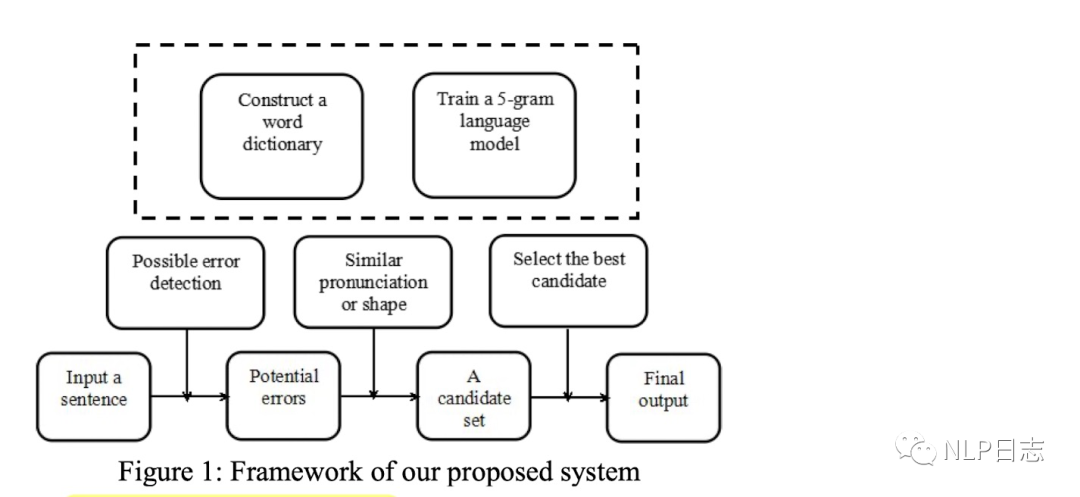
图4: LMPS框架
4 ACE
ACE是针对粤语的一种文本纠错方法,也是一种n-gram语言模型跟规则的结合,它的思路可以迁移到其他中文的方言中去。ACE需要事先构建的内容包括以下几个部分。
a) 混淆集。
b) 粤语词表,这个词表不仅来源于常见的粤语词组,还加入了当前火热的新词。同时给词表中的每个词打分,会根据训练集汇中每个词的出现概率记录相应的分值,出现概率高的词对应的得分也会比较高,然后将常见的词中得分的最低值作为阈值记录下来(后面会用到)。
c) n-gram语言模型,用于计算句子的n-gram得分。
ACE的纠错也是基于pipeline依次进行的。
a) 对文本进行分词。
b) 规则模块,借助于若干预先定义好的粤语句子结构规则对句子结构进行调整。例如,将“吃饭先”调整为“先吃饭”。
c) 查询句子中每个词在粤语词表中的得分,如果得分低于前面提及的阈值,那么就认为这个词可能是有问题的。
b) 知道所有可能有问题的词后,根据混淆集可以获得相应的候选,如果将可能有问题的词替换为相应的候选后,句子的得分(通过n-gram语言模型计算得到)提高了,那么就会把可能有问题的词替换为相应的候选,反之则还是维持现状。依次遍历所有可能出错的位置,完整所有必要的替换。
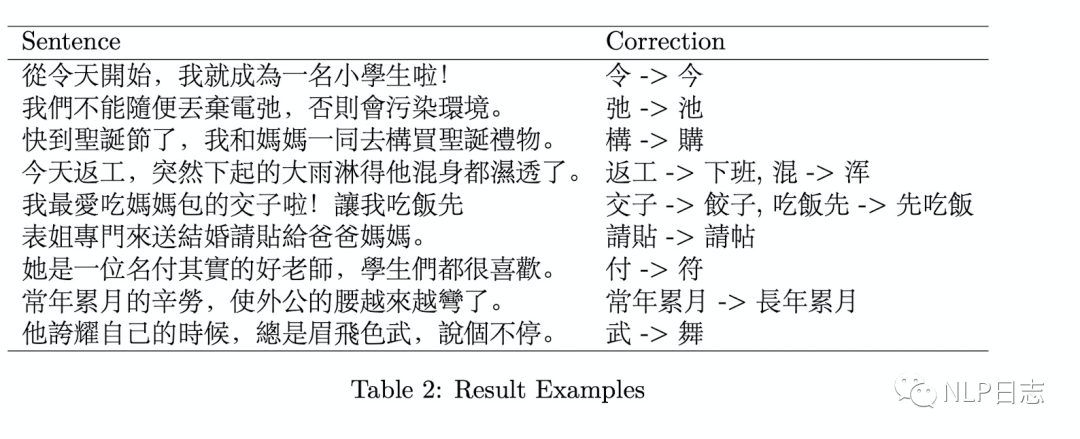
图5: ACE的纠错效果演示
5 总结
基于pipeline的文本纠错系统的框架都比较类似,没有太多惊艳的操作。
a) 基本必备混淆集跟语言模型,其中混淆集用于生成字符候选,语言模型用于比较不同字符在当前位置的合理性。
b) 各个模块都是独立运转的,缺乏联合优化的手段,很难协调好不同的环节的设置,子模块的优化并不一定会导致系统整体性能的提升。例如,为了保证召回率,就需要把检测环节放松点,导致很多正确字符都是检测为错误,这样就会导致纠正环节的准确率下降。如果把检测任务限制得更紧,提高了纠正环节的准确率,但是相应的召回率又会下降。
c) 整个系统有较多人为的痕迹,包括规则模块或者相关字典,泛化能力有限,后期需要一定的人力维护成本。例如更新规则或者字典等。
d) 支持解决一些比较常见的文本错误,但是对于稍微复杂的情形效果比较差。一方面,混淆集的构建需要成本跟时间,对于新词或者非常见字符不友好。另一方面,n-gram语言模型作为一种统计模型,没有考虑到句子的语义信息,效果有限。
参考文献
1.(2010) Reducing the false alarm rate of Chinese character error detection and correction
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.4106&rep=rep1&type=pdf
2.(2015) Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape
https://aclanthology.org/W14-6835.pdf
3.(2016) ACE: Automatic colloquialism, typo- graphical and orthographic errors detection for Chi- nese language.
https://aclanthology.org/C16-2041.pdf
编辑:黄飞
-
如何使用自然语言处理分析文本数据2024-12-05 3125
-
什么是pipeline?Go中构建流数据pipeline的技术2024-03-11 2028
-
Pipeline中throwIt的用法2023-10-21 1493
-
SpinalHDL里pipeline的设计思路2023-08-16 1791
-
中文文本纠错任务2022-07-26 2876
-
OpenHarmony 3.1 Beta版本关键特性解析——HiStreamer框架大揭秘2022-03-29 2969
-
v4l2_pipeline_pm_use的知识点分析,错过后悔2022-03-10 2306
-
如何使用Spark计算框架进行分布式文本分类方法的研究2018-12-18 1649
-
基于语义的文本语义分析2017-12-15 1151
-
网络谣言文本句式特征分析与监测系统2017-12-07 749
-
数字通信系统及纠错编码技术的介绍2017-11-17 1222
-
纠错码与通信系统的保密2016-07-29 867
-
认证系统与纠错码的应用研2009-08-13 840
-
Pipeline ADCs Come of Age2009-04-16 1391
全部0条评论

快来发表一下你的评论吧 !
