

适用于Python代码的开源式即时编译器NUMBA介绍
描述
Numba 是一个适用于 Python 代码的开源式即时编译器。借助该编译器,开发者可以使用标准 Python 函数在 CPU 和 GPU 上加速数值函数。
什么是 NUMBA?
为了提高执行速度,Numba 会在执行前立即将 Python 字节代码转换为机器代码。
Numba 可用于使用可调用的 Python 对象(称为修饰器)来优化 CPU 和 GPU 功能。修饰器是一个函数,它将另一个函数作为输入,进行修改,并将修改后的函数返回给用户。这种模组化可减少编程时间,并提高 Python 的可扩展性。
Numba 还可与 NumPy 结合使用,后者是一个复杂数学运算的开源 Python 库,专为处理统计数据而设计。调用修饰器时,Numa 将 Python 和/或 NumPy 代码的子集转换为针对环境自动优化的字节码。它使用 LLVM,这是一个面向 API 的开源库,用于以编程方式创建机器原生代码。Numba 针对各种 CPU 和 GPU 配置,提供了多种快速并行化 Python 代码的选项,有时仅需一条命令即可。与 NumPy 结合使用时,Numba 会为不同的数组数据类型和布局生成专用代码,进而优化性能。
为何选择 NUMBA?
Python 是一种广泛应用于数据科学的高效动态编程语言。由于其采用简洁明了的语法,并具有标准数据结构、全面的标准库、高水准的文档、庞大的库和工具生态系统以及大型开放社区,因此深受欢迎。不过,也许最重要的原因是,Python 等动态型态解释语言能够带来超高效率。
但是,对于 Python 来说,这既是最大的优势,也是最大的劣势。“它的灵活性和无类型的高级语法可能会导致数据和计算密集型程序的性能不佳,因为运行本地编译代码要比运行动态解释代码快很多倍。因此,注重效率的 Python 程序员通常会使用 C 语言重写最内层的循环,然后从 Python 调用已编译的 C 语言函数。许多项目都力求简化这种优化(例如 Cython),但它们通常需要学习新的语法。虽然 Cython 显著提高了性能,但可能需要对 Python 代码进行艰巨的手动修改工作。
Numba 被视作 Cython 的替代方案,并且要简单得多。它最大的吸引力在于无需学习新的语法,也无需替换 Python 解释器、运行单独的编译步骤或安装 C/C++ 编译器。只需将 @jit Numba 修饰器应用于 Python 函数即可。这样,在运行时即可进行编译(即“即时”或 JIT 编译)。Numba 能够动态编译代码,这意味着,您还可以享受 Python 带来的灵活性。此外,Python 程序中由 Numba 编译的数值算法,可以接近使用编译后的 C 语言或 FORTRAN 语言编写的程序的速度;并且与原生 Python 解释器执行的相同程序相比,运行速度最多快 100 倍。这是一项重要进步,推动了高效编程与高性能计算的完美结合。
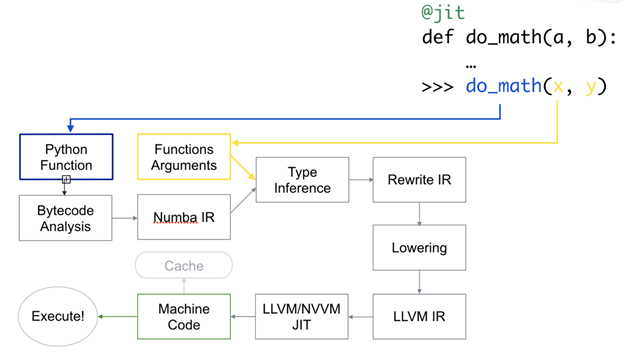
Numba 执行图
Numba 专为面向数组的计算任务而设计,与应用广泛的 NumPy 库类似。在面向数组的计算任务中,数据并行性与 GPU 等加速器自然契合。Numba 理解 NumPy 数组类型,并将其用于生成高效的编译代码,以在 GPU 或多核 CPU 上执行。所需的编程工作非常简单,只需添加一个 @vectorize 函数修饰器,指示 Numba 在运行时生成编译的向量化函数版本。这样,它便可用于在 GPU 上并行处理数据数组了。
除了为 CPU 或 GPU 即时编译 NumPy 数组代码外,Numba 还公开了“CUDA Python”:这是适用于 NVIDIA GPU 的 NVIDIA CUDA 编程模型,采用 Python 语法编写。加速 Python 后,它可以从胶水语言扩展至可高效执行数字代码的完整编程环境。
Numba 与 Python 数据科学生态系统中其他工具的结合使用,改变了 GPU 计算的体验。Jupyter Notebook 提供基于浏览器的文档创建环境,允许结合使用 Markdown 文本、可执行代码以及绘图和图像的图形输出。Jupyter 在教学、记录科学分析和交互式原型设计领域深受欢迎。
Numba 已在 200 多种不同的平台配置下进行了测试。它基于 Intel 和 AMD x86、POWER8/9、ARM CPU 以及 NVIDIA 和 AMD GPU 上的 Windows、Apple Macintosh、Linux 操作系统运行,大多数系统均可使用预编译的二进制文件。
用例
科学计算
数组处理应用广泛,从地理信息系统到计算复杂的几何形状,无一不及。电信公司使用数组来优化无线网络的设计,而医疗健康研究人员则使用数组分析包含内脏器官信息的波形。数组还可用于减少语言处理、天文成像和雷达/声纳中的外部噪声。
有了 Python 等语言,开发者无需进行大量数学训练,即可使用这些领域的应用程序。但是,Python 在数值密集型计算中存在性能缺陷,这会严重影响某些应用程序的处理速度。Numba 是其中一个解决方案。许多人都认为它易于使用,因此对于没有 C 语言等比较复杂语言经验的学生和开发者来说,意义重大。
NUMBA 对数据科学家的重要意义
在数据科学中,迭代开发是一种非常实用的省时方案,因为开发者能够通过观察结果来不断地改进程序。Python 等解释语言在这种情景中尤为有用。但是,Python 在高度数学运算中存在性能限制,这可能会造成瓶颈,从而减缓整体处理速度并限制开发者的工作效率。
Numba 为开发者提供了一种调用编译器函数的简单方法,显著提升了大型计算和数组的性能,从而解决了这一问题。Numba 简单易学,并使数据科学家无需执行使用编译语言编写子程序这一复杂任务,从而加快速度。
NUMBA 为何可在 GPU 上表现更突出
在架构方面,CPU 仅由几个具有大缓存内存的核心组成,一次只可以处理几个软件线程。相比之下,GPU 由数百个核心组成,可以同时处理数千个线程。

Numba 通过以下方式支持 CUDA GPU 编程:在 CUDA 执行模型后,直接将受限的 Python 代码子集编译到 CUDA 内核函数和设备函数中。使用 Numba 编写的内核看起来可以直接访问 NumPy 数组,而这些数组在 CPU 和 GPU 之间自动传输。这为 Python 开发者提供了一个轻松进行 GPU 加速计算的方法,而且无需学习新语法或语言,即可学会如何应用日益复杂的 CUDA 编码。借助 CUDA Python 和 Numba,您可以一举两得:使用 Python 实现快速迭代开发,同时达到针对 CPU 和 NVIDIA GPU 的编译语言的速度。
我们使用配备 NVIDIA P100 GPU 和 Intel Xeon E5-2698 v3 CPU 的服务器进行了一次测试,结果显示,使用 Numba 编译的 CUDA Python Mandelbrot 代码比只使用 Python 快了近 1700 倍。与 CPU 上的单线程 Python 代码相比,性能提升是多个因素的共同作用,包括编译、并行化和 GPU 加速。但是,它说明单是添加一个 GPU 即可实现加速。
NVIDIA GPU 加速的端到端数据科学
基于 CUDA-X AI 创建的 NVIDIA RAPIDS 开源软件库套件使您完全能够在 GPU 上执行端到端数据科学和分析流程。此套件依靠 NVIDIA CUDA 基元进行低级别计算优化,但通过用户友好型 Python 接口实现了 GPU 并行化和高带宽显存速度。
借助 RAPIDS GPU DataFrame,数据可以通过一个类似 Pandas 的接口加载到 GPU 上,然后用于各种连接的机器学习和图形分析算法,而无需离开 GPU。这种级别的互操作性可通过 Apache Arrow 等库实现,并有助于实现端到端流程(从数据准备到机器学习再到深度学习)的加速。
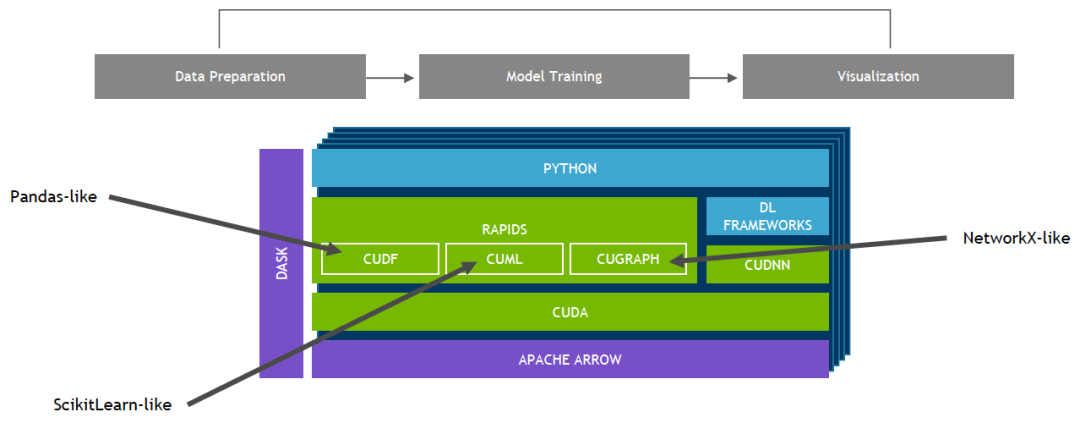
RAPIDS 支持在许多热门数据科学库之间共享设备内存。这样可将数据保留在 GPU 上,并省去了来回复制主机内存的高昂成本。
RAPIDS 团队正在开发和参与许多开源项目,并与众多开源项目(包括 Apache Arrow、Numba、XGBoost、Apache Spark、scikit-learn 等)密切协作,确保 GPU 加速数据科学生态系统中的所有组件顺畅地协同工作。
审核编辑:汤梓红
-
适用于PIC MCU的MPLAB XC8 C编译器用户指南2025-01-22 496
-
Triton编译器功能介绍 Triton编译器使用教程2024-12-24 3674
-
适用于AVR MCU的MPLAB XC8 C编译器用户指南2023-09-19 674
-
DASK适用于Python中的并行和分布式计算2022-05-20 3983
-
适用于Blackfin处理器的VisualDSP++<sup>®</sup>5.0 C/C++编译器和库手册2021-05-11 923
-
CompCert编译器目标代码生成机制研究综述2021-05-07 1393
-
适用于Microchip PIC的Pascal编译器2020-04-16 1632
-
英伟达适用于Python的VPF的功能2019-12-18 4233
-
方舟编译器开源核心代码的揭示2019-09-04 4408
-
IAR STM8编译器是否适用于STVD?2019-03-21 2753
-
Python高性能计算库—Numba2018-03-14 4780
-
C编译器及其优化2017-10-17 1556
-
一种用于反编译代码与源代码的比较算法2009-03-21 532
全部0条评论

快来发表一下你的评论吧 !
