

 rt-thread 心法系列(二) 使用宝典
rt-thread 心法系列(二) 使用宝典
描述
前言
接触 rt-thread 已有半年,混论坛也5个半月了,期间遇到过各种奇奇怪怪的棘手问题,有过尴尬,也自信曾经提供过比较妙的应对方案。所以产生了将一些典型的使用技巧汇总分享出来的想法,遂有此篇。
PS: 接触 rt-thread一年多了,这篇文章也经历了多次增补
入门篇
Q1. 刚下载的 SDK 啥也没干,编译没错,为啥程序跑不起来?
如果使用 keil + env 环境,下载源码后的**第一件事就是 `menuconfig`** ;
如果使用 RT-Studio ,创建项目后的**第一件事就是打开 Settings** ;
把其中所有配置页面所有配置项全浏览一遍,取消掉所有不相干的配置,最后只留一个内核。
先保证最小系统跑起来,用点灯程序验证最小系统运行正常。然后再添加自己需要用到的功能和底层外设等等。
Q2. 刚下载的 SDK 啥也没干,编译没错,为啥程序跑起来 hard fault on thread?
**同上**
Q3. 刚下载的 SDK 啥也没干,编译为啥报错了?
**同上**
内核篇
Q1. RT_NAME_MAX 定义多少合适
原则上越少越省内存,以内核对象 100 个为例,一个对象名占用 8 字节,总共是 800 字节。但是考虑到 `struct rt_object` 结构体定义,后面跟了两个 rt_uint8_t 型变量。
RT_NAME_MAX 可以定义成 2n + 2
Q2. RT_DEBUG
如非必要,不要开启内核调试。除非,你真的想学习内核,或者调试内核的问题。
Q3. 线程栈大小定义多少合适?
这个问题和应用有很大关系,如果仅仅是一个最小内核系统,除了 idle 线程,没有使用其它中断和应用,256 也将将够。如果添加了应用代码,还有中断和消息机制。建议 1024 起步。
Q4. 怎么快速计算 GET_PIN 返回的编号?
我们知道,芯片的 GPIO 分组往往是从 PA 开始,往后依次是 PB PC PD PE ... PZ。往往的,每组端口或者是 16bit 或者是 8bit (分别对应 16 个 IO 和 8 个 IO)。下面给出 `GET_PIN` 的简化公式:
16bit 是 `(X - A) * 16 + n`
> A10 就是 10.
C9 就是 2*16+9=41.
H1 就是 7*16+1=113.
8bit 是 `(X - A) * 8 + n`
这个公式别忘啊,别忘了!
PS: 有种,他们的引脚号编码很奇特,比如 RA6M4 ,见[【开发板评测】Renesas RA6M4开发板之GPIO、IIC(模拟)]( https://club.rt-thread.org/ask/article/36fe553196532ddd.html ) 第二节部分。
Q5. 硬定时器、软定时器、硬件定时器,傻傻分不清楚
rt-thread 内核定义了软件定时器,和硬件定时器不同,硬件定时器需要占用一个定时器外设,还有各种比较、捕获等功能。软件定时器仅仅是简单的设定一个时间,时间 timeout 的时候执行我们设定的回调函数。
rt-thread 定义的软件定时器还细分两种,“硬定时器” “软定时器”,前一种是在 SysTick 中断中执行回调函数的,多数用于线程内置定时器,应用层也可以用,但是要时刻谨记它的回调函数是在中断中执行的。
后一种,是在一个线程中运行的,应用层对定时精度要求不是很高的可以用这种,但是也要注意“定义定时器和执行定时器回调函数的线程是两个不同的线程!”
Q6. 消息队列池申请多少内存合适?
rt_err_t rt_mq_init(rt_mq_t mq, const char *name, void *msgpool, rt_size_t msg_size, rt_size_t pool_size, rt_uint8_t flag);
rt_mq_t rt_mq_create(const char *name, rt_size_t msg_size, rt_size_t max_msgs, rt_uint8_t flag)
如果使用 `rt_mq_create` 创建消息队列,消息队列池自动根据消息体大小 `msg_size` 和消息队列最多容纳的消息数量 `max_msgs` 计算。
但如果使用 `rt_mq_init` 初始化消息队列,消息队列池的内存 `msgpool` 需要用户提供,这个时候,需要注意消息池内存大小 `pool_size`。根据下面的公式计算得出:
`(RT_ALIGN(msg_size, RT_ALIGN_SIZE) + sizeof(struct rt_mq_message*)) * max_msgs`
其中,`msg_size` 是消息体大小,`max_msgs` 是消息队列中最多消息容量。
Q7. 使用消息队列注意
虽然 `rt_mq_send` `rt_mq_send_wait` `rt_mq_urgent` `rt_mq_recv` 几个 api 有 size 参数,但是请严格按照 `rt_mq_init` `rt_mq_create` 中的 msg_size 参数值传递相等的实参值。***千万不要随意改变 size 参数的数值***。
换种说法,别用消息队列直接发变长数据。
Q8. INIT_xxx_EXPORT 宏详解
当初接触 rt-thread 第一个让我感触的地方就是,main 函数里没有初始化配置,上来直接就是一个单独的线程。而,其它线程都通过 INIT_APP_EXPORT 自动启动了。
rt-thread 一共定义了 6 个启动阶段,
/* board init routines will be called in board_init() function */
#define INIT_BOARD_EXPORT(fn) INIT_EXPORT(fn, "1")
/* pre/device/component/env/app init routines will be called in init_thread */
/* components pre-initialization (pure software initilization) */
#define INIT_PREV_EXPORT(fn) INIT_EXPORT(fn, "2")
/* device initialization */
#define INIT_DEVICE_EXPORT(fn) INIT_EXPORT(fn, "3")
/* components initialization (dfs, lwip, ...) */
#define INIT_COMPONENT_EXPORT(fn) INIT_EXPORT(fn, "4")
/* environment initialization (mount disk, ...) */
#define INIT_ENV_EXPORT(fn) INIT_EXPORT(fn, "5")
/* appliation initialization (rtgui application etc ...) */
#define INIT_APP_EXPORT(fn) INIT_EXPORT(fn, "6")
其中, INIT_BOARD_EXPORT 运行在任务调度器启动前,也是唯一任务调度器运行前被执行的。这里是外设初始化配置阶段。
其余几个阶段都是任务调度器启动以后,由 main 线程(标准版,如果使用了 main 线程)负责执行。
这些阶段并不是完全固定,有些是可以调整的,例如,我曾经把 lcd 的初始化从 DEVICE 提前到 BOARD ,而把 emwin 的初始化放到 PREV 。还在 ENV 阶段初始化了一些消息队列等等。
大部分情况下,以上几个阶段可以完成所有定义的初始化工作。但是,也难免出现冲突的可能。
例如,github [#5194]( https://github.com/RT-Thread/rt-thread/pull/5194 ) 上的这个 pr。里面还提供了很多反应这个问题的链接。以及很多人提出的解决方案。
个人认为,启动顺序在同一级的,而且之间有依赖/互斥关系的两个部分。这种情况,应要求开发者自己注意调整代码执行顺序,把两个部分初始化过程写到同一个函数里,由开发者自己维护依赖关系。
Q9. 怎么通过 rt_thread_suspend rt_thread_resume 挂起唤醒某线程
尽量不要这么做,在 rt-thread 里,一个线程进入 suspend 态有两种情况,一种是时间片耗尽自动让出 cpu;一种是等待资源阻塞让出 cpu。两个线程之间并没有完整透明的了解对方当前状态的途径。
假如某线程 A 想显式挂起线程 B,但是,A 并不知道 B 当前是运行中让出 cpu,还是等待资源中已经处于挂起状态,还是资源可用正在从挂起态被唤醒过程中。所以,不明就里地挂起其它线程的做法是危险的。
笔者唯一能想到的,就是 B 线程执行任务比较多,自己不会主动出让 cpu。而且,它的线程优先级比较低,某高优先级线程 A 在某种条件下使得 B 挂起。但是这样线程 B 势必会影响到 idle 线程。
其实,这种场景,完全可以使用线程间同步机制实现,线程 B 通过发信号给 A 而挂起自己;线程 A 再通过另外一个信号唤醒线程 B。
曾经以为自己能找到直接使用这俩 api 的方式,有一天,突然想到 rt-thread 的 ipc 都是针对性的,因信号量挂起的,不可能因为邮箱被唤醒。因为时间片耗尽挂起的线程也别想着会被什么资源唤醒。挂起和唤醒具有唯一性。
Q10. list_thread 或 ps 查看线程状态不对?
1. error 列的线程错误没有多少参考价值,0 是正常,-2 表示超时,执行一个 `rt_thread_mdelay` 就变 -2 了。但并不表示有错误。目前还没有看到赋值有其它错误值的代码。
2. status 列代表当前线程状态。但是呢,因为 list_thread 或 ps 两条命令是在 tshell 线程执行的,所以 tshell 线程肯定是 running ;idle 线程不可能被挂起,肯定显示的是 ready;其它线程可能会出现 ready,但是多数时候是 suspend。但是这并不表示其它线程一直是 suspend 不被调度了。
Q11. 定时器可以执行长时间操作?
如上所说,rt-thread 中有三种定时器,每种定时器有各自的特点
硬件定时器:回调函数在中断里,不建议直接执行长时间操作。
硬定时器:同样也是在中断执行回调函数,不建议直接执行长时间操作。
软定时器:由定时器线程执行调用回调函数的软定时器,是具有执行长时间操作的理论基础的。定时器线程同样是一个线程,它也有自己的线程栈,优先级等。如果某些操作是独立的,把它们放到某特定线程里和在定时器线程运行是没区别的。
但是,目前定时器线程处理软定时器的方式不适合执行长时间操作。需要进行修改后才能做到。具体修改方法见 rt-thread优化系列(三)软定时器的定时漂移问题分析
注意:定时器线程的优先级需要根据需要进行调整;若有多个软定时器,回调函数执行都比较长,必然存在某回调被延迟执行的可能性,这个是无法避免的。
Q12. "Function[xxx] shall not be used in ISR" 错误是怎么回事儿?
以及类似的错误 "Function[xxx] shall not be used before scheduler start"
详见 rt-thread心法系列(一)那些你必须知道的几类 api
开发环境篇
Q1. 改变 env 或者 RT studio 下载源
rt studio 内置了 env 环境,studio 可能也是借助 env 实现下载更新组件的。有些第三方组件的主仓库在 github 上,这样就难为了很多小伙伴,经常因为访问不了 github 而出现下载更新失败。其实官方提供了镜像下载的方式,镜像仓库在 gitee 上,我们需要切换 env 下载方式为镜像下载。见此文章 RT-Studio 切换镜像服务器下载
文章中 **RTT_逍遥** 大佬提供了个命令 `menuconfig -s` ,这个命令也可以,查看 menuconfig 的帮助信息可以得到详细说明。
Q2. 生成 MDK5 项目,配置变了怎么办?
当执行 `scons --target=mdk5` 的时候,scons 从当前目录下的 "template.uvprojx" 文件为模版生成 "project.uvprojx" 项目配置文件。
我们修改项目配置,启用了 "Use MicroLIB" "Browse Information" "GNU extensions" 等等之后,重新生成可能导致之前的修改丢失,可以通过修改 "template.uvprojx" 文件
"0" 为 "1"
"0" 为 "1"
"0" 为 "1"
还比如,有人问,“[用Scons 生成keil工程时, 如何导入sct文件?]( https://club.rt-thread.org/ask/question/433781.html )”
打开 "template.uvprojx" 文件找到 “ScatterFile” 的位置,修改里面的文件路径及文件名就可以了。
`.boardlinker_scriptslink.sct`
其它可类比。
Q3. 修改 scons 使用的编译器
找到 rtconfig.py 文件,一般和 rtconfig.h 文件同目录,文件开头有几个变量
# toolchains options
ARCH='arm'
CPU='cortex-m4'
CROSS_TOOL='gcc'
分别定义了,cpu 核架构,版本,以及使用的交叉编译工具链平台。目前支持 gcc keil iar 三种平台。
接下来,针对每一种平台,使用不同的交叉编译工具链及其安装路径
最后是每种交叉编译工具链编译选项。
通过修改 `CROSS_TOOL='gcc'` 的定义可以修改编译器。
Q4. env 下的两种界面配置姿势
他人都说 studio 好,我却独衷心 env。
以前只知道 menuconfig,从此还有一个 `scons --pyconfig`。
论坛 mysterywolf 大佬发现的这个命令,像捡到一个宝,不习惯 menuconfig 的童鞋,喜欢 studio 配置可以点点点的童鞋,你们可以回来继续使用 env 啦!

修改完,点 SAVE -》关闭。
还支持搜索跳转,点 Jump to...,弹出界面里输入搜索内容,Search。
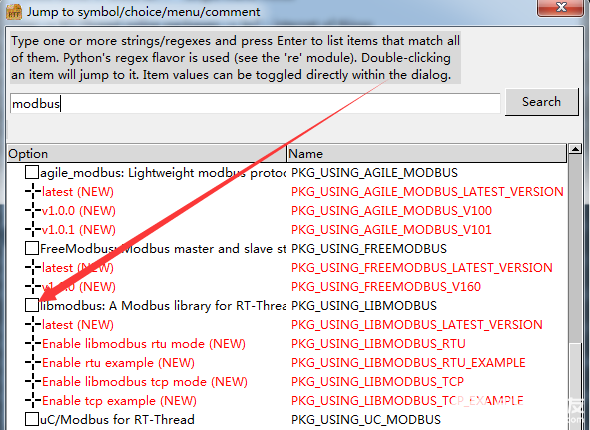
选项里可以直接配置,或者双击跳回原菜单位置。
比 studio 或 menuconfig 里的功能一点儿不少,还更方便操作啦。
Q5. menuconfig 找不到需要的在线包怎么办?
执行 `pkgs --upgrade` 命令,注意!不是 `pkgs --update` !
前一条命令用于更新 env 自带的 RT-Thread online packages 包列表信息。后者用于下载、更新、删除选择的包。
Q6. RT-Studio 怎么修改编译选项?
在 env 环境下,每个 bsp 根目录下都有个 rtconfig.py 文件,里面是各种开发环境下交差编译工具链配置(上文有提及过)。
修改了 rtconfig.py 文件后,使用 scons 编译直接使用的修改后的配置;使用 keil 开发需要执行 `scons --target=mdk5`,把新修改同步更新到 keil 项目配置文件里。
如果使用 RT-Studio 呢?。
1. 修改 RT-Studio 里的编译配置,需要按照 eclipse 的方式来。右键项目》》属性》》C/C++ 构建》》设置》》工具设置,在这里可以修改的有 c 编译器选项、c++ 编译器选项、链接器选项,blablabla 眼花缭乱的不一定能改对,小心谨慎,多加练习吧。
2. 使用 `scons --target=eclipse`,更新 RT-Studio 项目配置文件。需要注意的是,执行这个命令前先关掉 RT-Studio ,然后打开 env 切换到项目目录下,删掉 ".cproject" 项目文件,最后修改 rtconfig.py 文件后执行 `scons --target=eclipse`。
Q7. 添加第三方 lib 及其搜索路径
添加 lib 和路径也需要在 rtconfig.py 文件里修改,修改 LFLAGS 变量,增加库 `-lxxx` 。修改 LPATH 添加库搜索路径。
修改 rtconfig.py 之后按照上一小节的操作步骤刷新一下 IDE 工程文件。
还有一些 lib 是跟随软件包组件添加的,修改软件包目录下的 Scronscript 文件,
pathlib = [cwdlib + '/Lib']
group = DefineGroup('STemWin2RTT', src, depend = [''], CPPPATH = path, LIBS=['STemWin532_CM4_OS_Keil_ot'], LIBPATH = pathlib)
`pathlib` 用于添加 lib 文件路径。
“DefineGroup” 定义组时,增加两个参数 `LIBS=['STemWin532_CM4_OS_Keil_ot'], LIBPATH = pathlib` 分别指定库名称和库路径。
Q8. 添加头文件包含路径
因为 rt-thread 源码默认是 scons 自动化开发环境。源码中有大量的 Scronscript 脚本文件,这些文件控制着源码文件是否参与编译,增加哪些头文件搜索路径
`src += ['xxxx.c']` 添加源码文件。
`path += [cwd + '/ports']` 添加头文件路径。
外设驱动篇
Q1. USB Host 不识别 U 盘等设备
详见 [rt-thread STM32F4 usbhost 调试笔记](https://club.rt-thread.org/ask/article/2878.html)
这里还有另外两位大佬提供的修改方案,可以都尝试一下。或者集众家之长,前一段时间我按照两位大佬的也修改了一下,感觉都是可以兼容的,暂未发现问题。
PS: STM32 系列的芯片,可能要求 USBHOST 时钟频率是 48MHz ,这个要注意。
Q2. NAND Flash 驱动
[gitee](https://gitee.com/thewon/rt_thread_repo) 有完整代码
Q3. 移植 yaffs2 文件系统
配合上面的 nand flash 驱动使用。
[gitee](https://gitee.com/thewon/rt_thread_repo) 有完整代码
Q4. 更高效的串口驱动框架 serialX
请移步系列文章,从理论提出到实现,到实践验证,测试程序,用法demo,全套的。
rt-thread 驱动篇(一) serialX 框架理论
rt-thread 驱动篇(二) serialX 理论实现
rt-thread 驱动篇(三) serialX 压力测试
rt-thread 驱动篇(四)serialX 多架构适配
rt-thread 驱动篇(五)serialX 小试牛刀
使用篇
Q1. 串口通讯数据被分多次接收了,怎么办?
首先说明,串口是一种流设备,无协议接口。它收到一个字节给你一个字节,收到两个字节给你两个字节。如果你的数据是整齐的 16 个字节,而且想每收 16 个字节串口驱动给你个信号,这就难为人了。还有一种情况是,前后两次不同的数据被拼接在一起了。
这个时候,需要我们在应用层进行处理。或者是定长包,或者定义包头包尾,包长度等等。下面给出我在论坛上多次分享过的代码,这个是带包头包尾的,在这个基础上可以修改成其它各种形式包协议的。
rt_uint8_t *recvbuf = RT_NULL;
static struct serial_configure uart_conf = RT_SERIAL_CONFIG_USER;
rt_uint8_t *datbuf = RT_NULL;
rt_size_t rcv_off = 0, recv_sz = 1024, tmp = 0;
rt_size_t dat_off = 0, dat_len = 0, i;
rt_tick_t _speed_ctrl = 0;
recvbuf = rt_malloc(128);
rt_memset(recvbuf, 0, 128);
datbuf = rt_malloc(32);
rt_memset(datbuf, 0, 32);
busif_speed_ctrl = rt_tick_get();
rt_sem_init(&rx_sem, "bifrx", 0, 0);
dev_busif = rt_device_find("uart1");
if (dev_busif == RT_NULL)
{
rt_kprintf("Can not find device: %sn", "uart1");
return;
}
if (rt_device_open(dev_busif, RT_DEVICE_OFLAG_RDWR | RT_DEVICE_FLAG_INT_RX |
RT_DEVICE_FLAG_STREAM) == RT_EOK)
{
rt_device_set_rx_indicate(dev_busif, busif_rx_ind);
}
while(1) {
rt_sem_take(&rx_sem, RT_WAITING_FOREVER);
recv_sz = rt_device_read(dev_busif, -1, &recvbuf[rcv_off], 128-rcv_off);
if (recv_sz > 0) {
rt_kprintf("data: %dn", recv_sz);
if (rcv_off == 0) {
i = 0;
while ((recvbuf[i] != 0x1A) && (i < recv_sz)) i++; // find header
if (i == 0) {
rcv_off = recv_sz;
} else if (i < recv_sz) {
rcv_off = recv_sz-i;
rt_memcpy(recvbuf, &recvbuf[i], recv_sz-i);
} else { // no header
rcv_off = 0;
continue;
}
} else {
rcv_off += recv_sz;
}
if (rcv_off < 2) { // data not enough
continue;
}
dat_len = recvbuf[1];
if (dat_len > 16) { // error length
rcv_off = 0;
dat_len = 0;
continue;
}
if (rcv_off >= (dat_len + 3)) { // len enough
float val = 0;
AdcVal adc_val;
if (recvbuf[9+2] != 0x1B) { // find tailer error
dat_len = 0;
rcv_off = 0;
continue;
}
tmp = rcv_off-(dat_len + 3);
_speed_ctrl = rt_tick_get();
if (/*busif_busy > 0 || */(_speed_ctrl - busif_speed_ctrl < 100)) {
busif_busy--;
if (tmp > 0) {
rt_memcpy(recvbuf, &recvbuf[dat_len + 3], tmp);
rcv_off = tmp;
} else {
rcv_off = 0;
}
dat_len = 0;
continue;
}
switch(recvbuf[2]){ // map function type id
case 1:
adc_val.type = FUNC_DCV;
break;
case 2:
adc_val.type = FUNC_DCI;
break;
default: // unsupport type id
if (tmp > 0) {
rt_memcpy(recvbuf, &recvbuf[dat_len + 3], tmp);
rcv_off = tmp;
} else {
rcv_off = 0;
}
dat_len = 0;
rt_kprintf("error type: %dn", adc_val.type);
continue;
break;
}
rt_memcpy(datbuf, recvbuf+4, 7); // change str 2 float
datbuf[7] = 0;
rt_kprintf("%sn", datbuf); // 数据域 ,可以是字符串,可以是十六进制数据
// 其它数据处理
....
// prepare next package 准备下一包
if (tmp > 0) {
rt_memcpy(recvbuf, &recvbuf[dat_len + 3], tmp);
rcv_off = tmp;
} else {
rcv_off = 0;
}
dat_len = 0;
}
}
}
项目代码,神明保佑,别被老板看到
Q2. 线程间传输不定长数据
有两种消息机制可以传输数据,邮箱和消息队列。以下是一些使用建议:
- 邮箱传输的是定长 32bit 数据,或者是一个整型值,或者是一个地址;
- 消息队列的可伸缩性更强,而且有队列,消息体大小由用户决定,但是,一经初始化,消息体大小也是固定长度的了。
- 对于某些不同类型数据,每种数据长度固定,而且各种类型数据长度差别不是很多的情况,我们可以使用联合体代替结构体。这样消息体的长度也是固定的,以最长长度为准。
- 用邮箱传递内存地址,这样不限定数据长度,但是要求每一次邮箱必须被接收方接收。发送方申请内存,接收方释放内存。如果出现邮箱发送失败,由发送方释放内存。
- 用消息队列传递内存地址,比邮箱的优势就在于它能缓存多个地址,降低发送失败的风险。
- pipe 管道或 ringbuffer。pipe 内部数据结构也是 ringbuffer。虽然可以读写任意长度数据,但是,这样又将数据变成流了。需要读取方根据事先约定的协议进行解析拆分。还有个缺陷是它没有消息机制,写方需要单独发消息通知接收方,或者,接收方死等这个数据。鉴于这种方式必须用锁,不适合中断和线程之间的数据传输。
Q3. 插上 U 盘怎么通知应用程序?
[gitee](https://gitee.com/thewon/rt_thread_repo) 有完整代码,主要修改在 hub.c 和 udisk.c 两个文件
Q4. 怎么优雅的挂载多种存储设备?
内存、片上 flash 、片外 spi flash、sd 卡、U盘... 各式各样的的设备,挂载的文件系统也可能不一而足。怎么优雅的把多种设备挂载到文件系统就是个需要考虑的问题了。
1. 挂载 rom 根文件系统,同时创建其它可读写文件系统挂载点。
2. 其它设备分别挂载到 rom 文件系统的挂载点上。
Q5. rom 文件系统
rt-thread 源码目录下 “components/dfs/filesystems/romfs” 有个 romfs.c 文件,是 rom 文件系统配置模板文件,拷贝它到你的应用目录下,修改 `_root_dirent` 定义。可以创建只读文件。
RT_WEAK const struct romfs_dirent _root_dirent[] =
{
{ROMFS_DIRENT_DIR, "dummy", (rt_uint8_t *)_dummy, sizeof(_dummy) / sizeof(_dummy[0])},
{ROMFS_DIRENT_FILE, "dummy.txt", _dummy_txt, sizeof(_dummy_txt)},
};
或者,只有目录
RT_WEAK const struct romfs_dirent _root_dirent[] =
{
{ROMFS_DIRENT_DIR, "mnt", RT_NULL, 0},
{ROMFS_DIRENT_DIR, "usr", RT_NULL, 0},
{ROMFS_DIRENT_DIR, "var", RT_NULL, 0},
};
有了只读文件系统,可以很方便扩展挂载很多其它文件系统。
Q6. 丝滑挂载设备
在嵌入式里很多存储设备是焊接到电路板上的存储芯片。如果我们有在存储芯片上挂载文件系统的需求,出厂生产必须有方式对存储设备进行格式化。为此,可能难倒一大批流水线工人。可以使用下面的流程进行挂载。
result = dfs_mount(mtd_dev->parent.parent.name, "/usr", "yaffs", 0, 0);
if (result == RT_EOK)
{
rt_kprintf("Mount YAFFS2 on NAND successfullyn");
}
else
{
result = dfs_mkfs("yaffs", mtd_dev->parent.parent.name);
if (result == RT_EOK)
{
result = dfs_mount(mtd_dev->parent.parent.name, "/usr", "yaffs", 0, 0);
}
else
{
rt_kprintf("Mount YAFFS2 on NAND failedn");
return -RT_ERROR;
}
rt_kprintf("Mount YAFFS2 on NAND successfullyn");
}
挂载失败,直接格式化,有些比较暴力,但是不需要人工格式化存储设备了。
Q7. 如何自动挂载文件系统
两种方式:一种是通过配置,启用 RT_USING_DFS_MNTTABLE 。这种方式需要使用者自己实现一个结构体数组 `const struct dfs_mount_tbl mount_table[]` 。
另一种就是自己写代码挂载不同设备。我喜欢这一种,因为这样我可以使用上一小节提到的设计。
Q8. assertion failed at function:rt_xxxxx
问题是我没调用 `rt_xxxxx` 函数啊?!
这种问题分两种:
一种是,确定这个函数在运行中正常调用的,例如:(tid != RT_NULL) assertion failed at function:rt_applilcation_init,可以确定的是 `rt_applilcation_init` 函数运作于线程调度器启动前,这个时候肯定不会是多线程非法写了内存引起的。可以确定是因为 `rt_thread_create` 函数调用返回了空指针。那么,问题来了,堆初始化成功了吗?内存有多大?
另外一种是,没有调用那个函数的地方,但是提示这个函数参数检测出错。这种情况大概率是 PC 指针飞了。走到了不应该走到的位置。
定位问题方法请见下节。
Q9. hard fault on thread: xxx
考虑了很久,要不要把这个加进来。出现这个错误提示的可能性太多了。从现象上看也分两类,一类比较确定的,程序走到这个位置必然出现;一类不太确定,每次运行可能现象不一样。
- 环境搭建问题,系统移植有缺陷引起的。
- 线程栈太小,线程栈爆栈。
- 数组越界、野指针、函数参数传参错误...
- 逻辑性错误,内存释放后还有可能被使用。多发生在外设的接收缓存上。
但是,上面这些只是扯淡,并不能定位到错误位置。定位问题是个方法论范畴的概念。每个人都应该有自己熟悉的一套做法,我的想法请见 rt-thread 工具讲解系列(二) 之 如何排查系统 bug
Q10. 怎么定义变量到指定内存位置?
非 gcc 版
- 定义一个宏
#ifndef __MEMORY_AT
#if (defined (__CC_ARM))
#define __MEMORY_AT(x) __attribute__((at(x)))
#elif (defined (__ARMCC_VERSION) && (__ARMCC_VERSION >= 6010050))
#define __MEMORY_AT__(x) __attribute__((section(".ARM.__AT_"#x)))
#define __MEMORY_AT(x) __MEMORY_AT__(x)
#else
#define __MEMORY_AT(x)
#warning Position memory containing __MEMORY_AT macro at absolute address!
#endif
#endif
- 使用 `uint8_t blended_address_buffer[480*272*2] __MEMORY_AT(0xC0000000);`
gcc 版
- 修改链接文件
/* Program Entry, set to mark it as "used" and avoid gc */
MEMORY
{
CODE (rx) : ORIGIN = 0x08000000, LENGTH = 1024k /* 1024KB flash */
RAM1 (rw) : ORIGIN = 0x20000000, LENGTH = 192k /* 192K sram */
RAM2 (rw) : ORIGIN = 0x10000000, LENGTH = 64k /* 64K sram */
SDRAM (rw): ORIGIN = 0xC0000000, LENGTH = 8092k /* 1024KB sdram */
}
SECTIONS
{
... /* 忽略其它内容 */
.sdram :
{
KEEP(*(.sdram_section))
} >SDRAM
}
- 定义一个宏
#ifndef __MEMORY_AT
#define __MEMORY_AT(x) __attribute__((section(".#x")))
#endif
- 使用 `uint8_t blended_address_buffer[480*272*2] __MEMORY_AT(sdram_section);`
gcc 版本是把变量分配到某 section ,距离地址还有查一点儿。当多个变量放到同一个 section 的时候,它们的顺序就不保证了。这种情况只能多定义一些 section。
Q11. 结构体字节对齐
__packed struct __packed_struct{
...
};
struct __attribute__((packed)) __packed_struct{
...
};
struct __packed_struct{
...
} __attribute__((packed));
#pragma pack(push, n)
struct __packed_struct{
...
};
#pragma pack(pop)
keil 里可以这么写,其它开发环境下有差异。gcc 不支持 `__packed` 的写法
最后的写法,可以指定按照 n 个字节对齐,n 是一个具体是常数,常用的有 1 2 4 8 ...
Q12. unaligned access 是怎么出现的?
据我所知,当取指令的时候要求比较严格,编译器也往往把指令做了对齐处理。如果出现非对齐访问,多半是 pc 指针异常了。
还有一种情况,有人说 ARMv7-M 架构设计的时候,0xC0000000-0xDFFFFFFF 这个地址段默认要求必须 4字节(数据总线宽度)对齐访问。如果这片内存有个压缩的结构体变量,对此变量读写也可能出现 unaligned access 错误。解决方法如下:
1. 修改 MPU 让这个区域变成正常储存器
/* Configure the MPU attributes as WT for SRAM */
LL_MPU_ConfigRegion(LL_MPU_REGION_NUMBER1, 0x00, 0xC0000000UL,
LL_MPU_REGION_SIZE_16MB | LL_MPU_REGION_FULL_ACCESS | LL_MPU_ACCESS_NOT_BUFFERABLE |
LL_MPU_ACCESS_NOT_CACHEABLE | LL_MPU_ACCESS_NOT_SHAREABLE | LL_MPU_TEX_LEVEL1 |
LL_MPU_INSTRUCTION_ACCESS_DISABLE);
2. 映射 SDRAM 到别的地址.(0x60000000, 如果你外挂 NOR Flash,这个方法行不通)
RCC-> APB2ENR | = RCC_APB2ENR_SYSCFGEN;
SYSCFG-> MEMRMP | = SYSCFG_MEMRMP_SWP_FMC_0;
3. 取消未对齐访问检测
编译器添加 `–no_unaligned_access` 编译选项。
有人介绍这个选项的时候说“强制编译对齐”或者“禁用未对齐访问支持”,个人认为这种说法不正确,因为,结构体还是按照咱们的想法按照字节对齐的,只是在访问这个数据的时候换了种方式,不用4字节(数据总线宽度)对齐的方式访问了。添加这个选项,恰恰是支持了未对齐数据访问。
支持未对齐数据访问的基于 ARM 体系结构的处理器,包括:
- 基于 ARMv6 体系结构的所有处理器
- 基于 ARMv7-A 和 ARMv7-R 体系结构的处理器。
不支持未对齐数据访问的基于 ARM 体系结构的处理器,包括:
- 基于 ARMv6 以前版本的体系结构的所有处理器
- 基于 ARMv7-M 体系结构的处理器。
Q13. STM32F767 怎么使用 PersimmonUI?
不止 STM32F767,可以使用 PersimmonUI 芯片可以很多,详情见独立文章 STM32F767 使用 PersimmonUI 及其它芯片使用可行性分析
结束语
本人能力有限,文中难免有错误,或者方法错误。望各位同仁不吝赐教。
拜谢拜谢
此宝典不定期更新,希望有朝一日能破万条。
审核编辑:汤梓红
-
RT-Thread v5.0.2 发布2023-10-10 3702
-
基于RT-Thread Studio学习2023-05-15 6828
-
RT-Thread文档_RT-Thread 简介2023-02-22 1125
-
【原创精选】RT-Thread征文精选技术文章合集2022-07-26 11686
-
RT-Thread学习笔记 RT-Thread的架构概述2022-07-09 6460
-
RT-Thread记录(二、RT-Thread内核启动流程)2022-06-20 7606
-
RT-Thread全球技术大会:萤石研发团队使用RT-Thread的技术挑战2022-05-27 3084
-
RT-Thread Smart 上手指南2022-01-25 1424
-
RT-Thread编程指南2015-11-26 2372
全部0条评论

快来发表一下你的评论吧 !
